Linux inode 从元数据到硬链接
- 起因:凌晨的电话告警
- TL;DR
- inode 是什么
- 词源与 POSIX 术语
- inode 里通常有什么
- 为什么 inode 里不存文件名
- 目录是一种特殊文件
- inode 号与文件名:打开文件时发生了什么
- inode 数量与空间:
df -i - 硬链接与符号链接
- 若干实践上的推论
- 小结
- 参考
起因:凌晨的电话告警
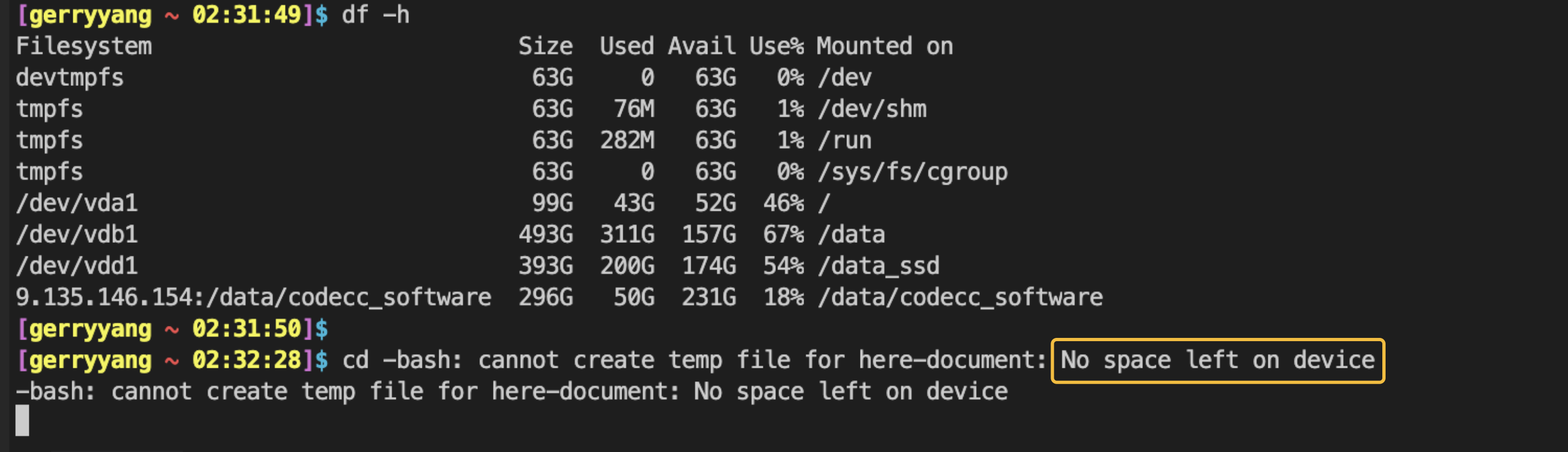
问题起因源于凌晨的一个电话告警,某机器磁盘空间不足。然后远程登陆确认问题,发现磁盘空间实际并没有用完,而是某个文件系统分区的 inode 被耗尽了,导致出现了 No space left on device 错误。
对于磁盘空间不足的问题,通常可以通过:
- 首先检查磁盘空间,使用
df -h命令查看哪个分区满了 - 如果空间显示还有剩余,再检查 inode 的占用情况,使用
df -i命令查看,如果IUse%是 100%,说明文件系统无法创建新文件。
如果是磁盘空间不足,可参考下面的快速清理建议:
- 清理临时文件:
sudo rm -rf /tmp/* - 清理软件包缓存
- Ubuntu/Debian:
sudo apt-get clean - CentOS/RHEL:
sudo yum clean all
- Ubuntu/Debian:
- 查找并删除大日志:
sudo find /var/log -type f -size +100M - 清理 Docker 镜像:
docker system prune -f
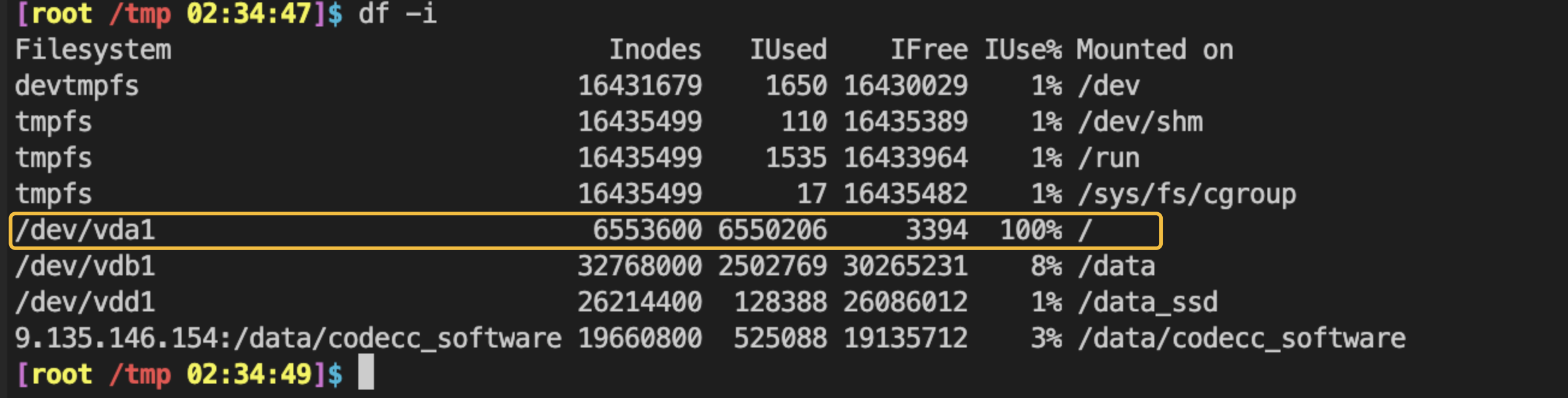
而当前显示 /dev/vda1 的 Inode 使用率已达到 100%。这意味着即使磁盘还有存储空间,系统也无法再创建任何新文件或目录。此时需要排查 / 根目录下哪个文件夹包含的文件数量最多。
查找各目录下文件数量排名可通过下面的命令查看,在根目录下运行以下命令,它会统计当前目录下每个子目录的文件总数(包括子目录中的文件),并按数量从大到小排序:sudo find / -maxdepth 1 -type d | xargs -I {} sh -c "echo -n '{}: '; find '{}' | wc -l" | sort -n -t: -k2,但是如果文件数量非常多的情况下,执行此命令会非常慢。因此需要根据经验先排查可能出现问题的场景。
根据经验,以下目录最容易导致 inode 耗尽:
/tmp/:临时文件溢出。/var/log/:某些应用程序产生大量细碎日志。/var/spool/postfix/maildrop/:如果系统邮件服务配置不当,会产生大量零碎的未投递小邮件。- Docker 容器目录:某些容器(如
OverlayFS)会生成海量小文件,路径通常在/var/lib/docker/。
根据上面可能的目录分别进行排查,最后发现是 /var/spool/postfix/maildrop/ 目录下的文件过多导致的。查看这个目录下的文件信息,发现无法输出说明目录下的文件太多了。

已经定位到是 /var/spool/postfix/maildrop 目录下的文件过多导致的问题,如何解决?
可以使用以下方法删除文件:
- 如果文件太多,直接用
rm -rf *可能会报 “Argument list too long” 错误 - 建议使用,
sudo find /var/spool/postfix/maildrop -type f -delete
然后检查是否有定期任务(Cron Job)失效。当系统的 Cron 任务(定时任务)执行时,如果该任务有标准输出(stdout)或错误输出(stderr),系统默认会尝试将这些输出内容通过 sendmail 发送给该任务的属主。如果你的系统没有正确配置 Postfix(邮件传输代理),或者邮件发送功能失效,这些邮件就会堆积在 /var/spool/postfix/maildrop/ 目录中。每个任务执行一次,就会产生一个几 KB 的小文件,时间一长就会耗尽 inode。
导致 /var/spool/postfix/maildrop/ 目录文件堆积常见的两个原因:
- 没有重定向输出:定时任务在运行时产生了日志或报错信息。
- Postfix 未运行或配置错误:系统尝试发信但无法处理,导致队列溢出。
通过 crontab -l 命令查看当前的定时任务配置,可以看到导致此问题的原因是:没有重定向输出。
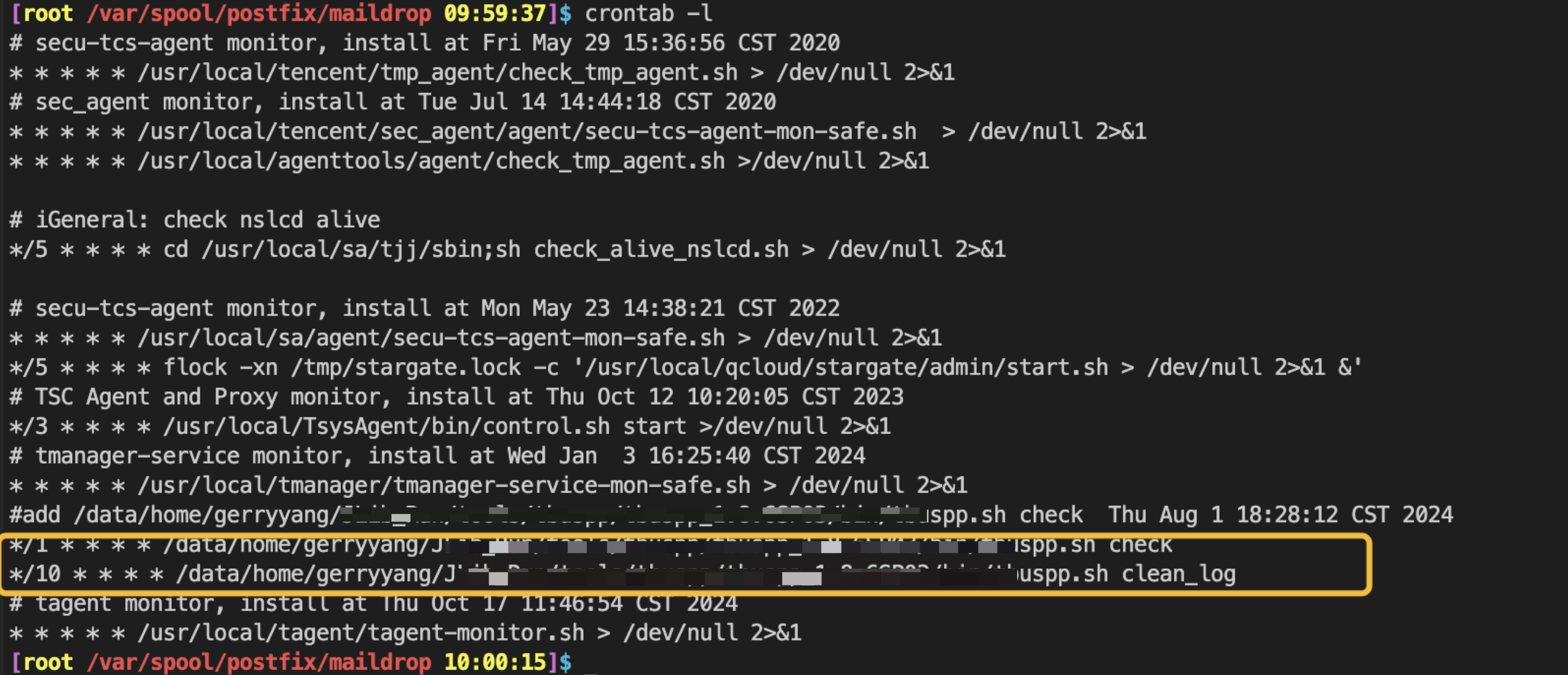
通过查看 maildrop 目录下某个文件的信息,也可以看到是哪个定时任务报错了:

修复此问题的方法:
- 重定向输出。修改报错的 crontab 任务,在末尾加上
>/dev/null 2>&1,彻底禁止产生邮件。 - 禁用 Cron 的邮件功能。通过
crontab -e命令编辑定时任务配置,在 crontab 文件的最顶端添加一行MAILTO="",将邮件接收人设为空。
因为报错的定时任务是 */1(每分钟执行一次),如果脚本持续失败,每分钟就会产生一个报错文件。
- 一天 1440 分钟 = 1440 个文件。
- 一个月就会积累 4.3 万个 小文件。
- 这些小文件虽然体积小,但每个文件都要占用一个
inode,最终导致磁盘inode耗尽。
一个文件系统的 inode 数量是在格式化(创建文件系统)时根据磁盘大小自动计算并固化下来的。
当执行类似 mkfs.ext4 /dev/vda1 的命令时,文件系统会根据默认比例(通常是每 16KB 或 25KB 空间分配一个 inode)预分配好所有的 inode。一旦格式化完成,这个 6,553,600 (约 655 万个) 的总数就是上限。除非重新格式化或使用特殊工具(如 resize2fs 配合特定参数,但风险极高且通常不支持增加 inode 比例),否则无法动态增加。
inode 的限制是基于文件系统(分区)的,而不是针对单个目录或整个系统。以问题场景为例,限制是针对 /dev/vda1 这个磁盘分区的。
-
同分区共享:只要在
/dev/vda1下的所有目录(如/etc、/var、/root、/home等),它们都共享这 6,553,600 个 inode 额度。 -
谁用得多,别人就没得用:如果
/var/spool/postfix/maildrop一个目录产生了几百万个小文件占满了 inode,那么在/root或/tmp下连创建一个 1 字节的空文件都做不到。 -
跨分区隔离。如果系统有多个分区(例如
/dev/vda1挂载在/,而/dev/vdb1挂载在/data),那么/分区的 inode 满了,不会影响/data分区创建文件。每个分区在格式化时都有自己独立的 inode 池,可以运行df -i输出查看。
通过以下命令查看你的文件系统当初是怎么定义的:
- 查看分配的 inode 数量:
sudo tune2fs -l /dev/vda1 | grep -i "Inode count" - 每个 inode 的大小:
sudo tune2fs -l /dev/vda1 | grep -i "Inode size"

TL;DR
在类 Unix 系统里,在终端里看到的「文件名、权限、大小、时间」等信息,并不和文件内容堆在同一块区域里:内容在数据块里,描述文件本身的元数据则集中在 inode(index node,索引节点)里。理解 inode,有助于解释硬链接为何不能跨分区、df -i 报满时磁盘却还有空间、以及目录权限里 x 为何如此关键。
较早的笔记 Linux in Action — inode 小节。
阅读线索:先弄清「数据块 / inode / 目录项」分工与 inode 里有哪些字段(文中配有 Mermaid 示意图)→ 再讲 目录文件 如何存文件名、路径如何解析到 inode → 然后落到 磁盘上的 inode 表大小、df -i 与耗尽 → 最后 硬链接、软链接 与日常推论。
inode 是什么
从存储层次看:硬盘以扇区(sector)为物理最小单位(常见 512 字节),操作系统读写时往往按更大的 块(block) 聚合,常见为 4KB。文件的字节内容存放在这些块里;而 谁拥有这个文件、权限、大小、时间戳、数据块在磁盘上的索引 等,则记录在 inode 中。因此常说:除文件名以外,与文件相关的大部分信息都在 inode 里(文件名放在目录项里,见下文)。这一分层在 阮一峰:理解 inode 里有很直观的「扇区—块—inode—数据」叙述。
从内核与手册的角度,每个文件对应一个 inode;应用可通过 stat(2) / statx(2) 取得与 inode 对应的元数据字段,手册 inode(7) 逐项说明了这些字段的含义。
Red Hat 博文 则强调:inode 是「某个已挂载文件系统」内部的标识,不同文件系统各自维护 inode 表;inode 号在同一文件系统内唯一,在不同文件系统间可以重复,因此 硬链接不能跨越文件系统边界(与 inode(7) 的表述一致)。
下图概括 「元数据在 inode、正文在数据块」 的关系;文件名不在此图中,它存放在 目录项 里(后文「目录是一种特殊文件」)。
flowchart LR
subgraph inode_part["inode(索引节点)"]
IM["权限 / 属主 / 大小<br/>时间戳 / 链接数<br/>指向数据块的指针 …"]
end
subgraph data_part["数据块"]
DB["文件内容(字节)"]
end
IM -->|"按指针读/写"| DB
词源与 POSIX 术语
英文 inode 一般读作 index node(索引节点) 的缩写。据 Wikipedia: inode 引用的 Dennis Ritchie 说明,早期 UNIX 里目录项只保存 文件名 和一个整数 i-number(索引号);打开文件时用 i-number 到磁盘上已知的 i-list 里取出对应的 i-node,因此 i 多半就是 index 的含义。文献里也常见「inode 是 index node 的缩写」这类表述(同条目中引 Maurice J. Bach)。
POSIX 不把「inode」写进 C API 名字,但约定每个文件在 其所在文件系统内 有一个 file serial number(文件序列号),通常就是实现里的 inode 号;再与 含有该文件的设备的 device ID 组合,可在整台机器上区分不同卷上的「同号」文件。用户空间看到的 st_ino / st_dev 与这一模型一致(仍见 Wikipedia: inode — POSIX inode description)。
实现层面:Linux 内核里与文件对象对应的数据结构常称 struct inode;BSD 传统里在 VFS 层更常听到 vnode(v 表示 virtual file system 层),语义上与「已解析到的文件节点」相近,并不改变「目录项指向 inode、inode 描述内容与元数据」这一大图。
inode 里通常有什么
一句话概括:除了文件名以外的、用来描述「这个文件对象」的信息,都放在 inode 里——包括类型、权限、属主、大小、时间戳、硬链接数、数据块位置等。使用 ls -li 时,第一列是 inode 号,最后一列是文件名(来自目录项);中间权限、链接数、属主、大小、时间等字段都来自 inode。使用 ls -l 只是少了一列 inode 号,文件名仍来自目录项,不是从 inode 里读出来的。
下面按 inode(7) / stat(2) 的常见字段归纳(具体文件系统可能多几项或少几项,例如 birth time):
| 含义 | stat 结构里常见成员 |
你在意什么 |
|---|---|---|
| 所在设备 | st_dev |
哪块盘/哪个挂载上的文件系统 |
| inode 编号 | st_ino |
在该文件系统内的唯一编号 |
| 类型 + 权限 + setuid 等 | st_mode |
是普通文件、目录、软链还是设备;rwx 与 s/t 位 |
| 硬链接数 | st_nlink |
有多少个目录项指向同一 inode |
| 属主 / 属组 | st_uid / st_gid |
用户名、组名可由 /etc/passwd 等解析 |
| 设备文件时的设备号 | st_rdev |
字符/块设备的主次设备号 |
| 逻辑大小 | st_size |
字节数;对软链常是目标路径字符串长度 |
| 建议 I/O 块大小 | st_blksize |
高效读写的块大小提示 |
| 已分配块数 | st_blocks |
占用的 512 字节块数(单位见手册与实现) |
| 最后访问时间 | st_atime |
atime |
| 最后修改内容时间 | st_mtime |
mtime |
| 最后改 inode 元数据时间 | st_ctime |
ctime(改属主、权限等也会变) |
| 数据块索引 | (内核/驱动使用) | 正文或内联数据在哪里 |
另外,极小的内容有时可 内联(inline) 进 inode 里为数据块预留的指针区域,从而少一次读盘:例如经典 ext 系对很短符号链接的 fast symbolic link,以及 ext4 可选的 inline_data 等(见 Wikipedia: inode — Inlining)。因此「元数据在 inode、正文永远在独立块里」在工程上不能当成绝对规则。

为什么 inode 里不存文件名
不是疏忽,而是 刻意拆分角色:
- 一个 inode 可以对应多个名字(硬链接)。若文件名写在 inode 里,就无法表达「同一文件、两个合法路径」;实际是 多个目录项 各自保存一段 文件名 + 同一个 inode 号,共同指向 同一个 inode。
- 名字是相对「在哪个目录里」而言的。同一 inode 在不同目录下的名字可以不同;名字属于 父目录的数据(目录文件里的一行行 dirent),不属于「被命名的那个文件对象」自身。
- 早期 UNIX 模型就是:目录项 ≈ 「名字 + i-number」,打开时用 i-number 去 inode 表里取元数据(见上文「词源」一节)。这样查找路径时,只在各级目录里做 名字 → inode 号 的匹配,inode 只描述 对象本体。
因此:文件名在目录里,inode 描述「这个对象是谁、多大、谁有权、数据在哪」(与 Wikipedia: inode — Details 一致)。
硬链接时,多个目录项指向 同一 inode,图中表现为两条边汇入同一节点(与后文「硬链接与符号链接」一致)。
flowchart TB
subgraph names["目录项里的名字(在父目录文件中)"]
N1["名称: report.txt"]
N2["名称: report.bak"]
end
subgraph one["同一文件对象"]
INO["inode 314159"]
INO --> BLK["数据块(一份内容)"]
end
N1 -->|"inode 号"| INO
N2 -->|"同一 inode 号"| INO
目录是一种特殊文件
目录在实现上常视为「目录项的列表」:每项包含 文件名 与对应的 inode 号。因此:
ls列出的是目录文件里的名字;ls -i可连同 inode 号一起列出。- 目录的读权限
r:允许列出文件名(目录项中的名字部分)。 - 目录的执行权限
x:允许「穿过」该目录去解析其中的名字,从而访问子项的 inode(没有x往往无法cd或打开子路径)。这与「详细信息在 inode 里」是一致的——没有执行位,你可能读得到一串名字,却无法继续stat到目标 inode。
目录本身也是一个 inode + 若干数据块;其数据块里排布的是 目录项(名字 ↔ inode 号),而不是普通文件的「正文」。
flowchart TB
subgraph dir_inode["目录的 inode"]
DI["类型=目录<br/>权限 / 属主 …"]
end
subgraph dir_data["目录的数据块(概念)"]
E1["readme.md → inode 1001"]
E2["notes/ → inode 1002"]
E3["…"]
end
DI --> dir_data
inode 号与文件名:打开文件时发生了什么
内核以 inode 号(结合设备号)识别文件,而不是文件名;文件名是便于人类使用的标签。路径解析完成后,打开描述符往往只与 inode 绑定,因此通常 不能 从「已打开的文件」可靠反推出当初用的是哪一个路径——getcwd(3) 等要从当前目录向上扫描父目录、在目录项里匹配 inode 号来 拼 路径(内核还会用 dentry 缓存加速;见 Wikipedia: inode — inode number conversion and file directory path retrieval)。打开文件的典型逻辑可以概括为(与 阮一峰:理解 inode 一致):
- 在目录中根据 文件名 → inode 号 解析出目标 inode;
- 读取 inode 中的元数据与块指针;
- 按块读/写实际数据。
对路径 /home/u/a.txt,内核在每一级 目录的数据块 里做 名字 → inode 号 的查找,最后得到目标文件的 inode,再读其元数据与数据块。下图是 逻辑顺序 的简化(真实实现还有 dentry 缓存、挂载点等细节)。
flowchart LR
P["路径: /home/u/a.txt"] --> L1["在 / 的目录项中找 home"]
L1 --> L2["在 /home 的目录项中找 u"]
L2 --> L3["在 /home/u 的目录项中找 a.txt"]
L3 --> INO["得到目标 inode"]
INO --> RW["读 inode → 访问数据块"]
与 普通文件 的 inode 号、stat 长格式字段相关的命令见上文「查看某个文件的 inode 信息」中的 stat、ls -i、ls -li。此处仅补充 查看目录自身 的 inode(避免 ls 列出的是目录「里面」的条目而非目录本身):
ls -idl /path/to/dir
与 Red Hat 博文 中的 ls -idl 用法一致。
inode 数量与空间:df -i
单条 inode 多大、inode 表占多少盘
磁盘上除了 数据区(存文件内容),通常还有 元数据区,其中一块用来放 inode 表:每个已分配或预留的「文件槽位」对应 一条定长的 inode 记录(存放权限、时间戳、块指针等,见前文表格)。这条记录在磁盘上的长度叫 Inode size,常见为 128 字节或 256 字节(视文件系统与创建时的选项而定),与「文件逻辑大小 st_size」不是一回事——后者是文件内容有多长,前者是 描述这个文件对象 的元数据结构在盘上占多少字节。
创建文件系统(mkfs.ext4、mke2fs 等)时,工具会按容量和 inode 密度 的启发式规则决定 一共准备多少个 inode(例如历史上常见「每 1KB~2KB 卷容量给一个 inode」一类的比例,具体以手册与默认值为准;Red Hat 博文 也提到量级上「约每 16KB 容量对应一个 inode」这类经验比例,以你机器上实际格式化参数为准)。因此:
- inode 表占用的磁盘空间 ≈ 「inode 个数 × 每条 inode 记录大小」再加上可能的索引/对齐开销;
- 卷总容量里,除了数据块,还要扣掉 inode 表、位图、日志等开销,不是 100% 都能当用户数据用。
经典 ext 系布局可粗看成「一块盘上既有 inode 表区域,也有 数据块区域」(实际还有超级块、块组描述符、位图等,下图仅突出与本文最相关的两块)。
flowchart TB
subgraph vol["某个文件系统分区(概念)"]
subgraph meta_area["元数据区(示意)"]
IT["inode 表<br/>定长记录 × N 个"]
BM["位图 / 组描述符 / 日志等"]
end
subgraph data_area["数据块区"]
BK["存放目录与文件内容"]
end
end
IT -.->|"每条 inode 指向"| BK
每个文件都要占一个 inode:用光 inode 时「有空间却建不了文件」
在典型 Unix 文件语义下,每一个独立的文件系统对象(普通文件、目录、符号链接、设备节点等)都要消耗至少一个 inode。 硬链接是多个目录项共用一个 inode,不额外增加 inode;软链接自己是单独文件,会占自己的 inode。
因此会出现 阮一峰:理解 inode 里强调的情况:inode 已经用光,但数据区还有大量空闲块,此时再在 该文件系统上 touch、vim 保存新文件、mkdir 等需要 分配新 inode 的操作会失败。常见报错仍是 No space left on device(ENOSPC),容易误以为磁盘满了——实际上应同时看 df -h 与 df -i:若 IUse% 为 100% 而容量仍有余,就是 inode 耗尽 而非数据块耗尽。
典型诱因:海量小文件(邮件队列、CI 缓存、node_modules、会话文件、Sharded 存储等),每个文件哪怕只有几字节,也要 一个 inode + 至少若干元数据/数据开销。
df -h 与 df -i 要对照看:下图表示一种常见错位——块空间仍有余,但 inode 配额已用尽,此时新建文件仍会失败。
flowchart LR
subgraph dfh["df -h(块容量)"]
H["数据块: 仍有空闲 ░░"]
end
subgraph dfi["df -i(inode)"]
I["inode: 已用尽 ████"]
end
H --> R["touch / mkdir 仍可能报 No space left on device"]
I --> R
查看某挂载点的 inode 总量与使用情况:
df -i /path # 或 df -i /dev/sdXN
Red Hat 博文 中的示例输出可读作:IUsed / IFree / IUse% 与容量无关,单独反映 inode 资源。排查与容量相关问题务必 df -h 与 df -i 一起看。
缓解思路(仅列方向,实施前需评估业务与备份):删掉不需要的小文件或整目录、迁走到别的卷、在 新建文件系统 时调大 inode 比例或换用更适应海量小文件的文件系统;已存在的卷 上 ext4 不能 在线把 inode 总数改大,往往需要迁移或重建文件系统——故 规划阶段 就要对「小文件密度」有数。
固定 inode 表与动态元数据
不少 传统 Unix 文件系统在创建文件系统时就划定 固定大小的 inode 表,因此 inode 上限与「还能不能建小文件」在运维上很实在。另一类设计(如 Wikipedia 中列举的 XFS、JFS、btrfs、ZFS/OpenZFS、ReiserFS、APFS 等)用 B 树等结构 动态维护等价元数据,不一定再有一块字面意义上的「inode 表」,但仍要能为每个文件对象保存同样的信息;动态分配可以缓解「空间还有但 inode 光了」的问题,具体仍取决于文件系统与版本,排障时仍以 df -i 为准。
硬链接与符号链接
- 硬链接:多个 目录项中的不同文件名 指向 同一个 inode;
st_nlink递增。删除其中一个名字只减少链接数;链接数减到 0 时,目录里已没有任何名字指向该 inode,这类对象有时称为 unlinked(已解除链接) 的文件:若仍有进程持有打开的文件描述符(包括正在执行的程序镜像),内核通常会 推迟 真正回收数据块,直到最后一个引用关闭(与 Wikipedia: inode — inode persistence and unlinked files 一致)。无打开引用时,inode 与数据块可被回收。因为 inode 号仅在同一文件系统内唯一,硬链接不能跨挂载点/分区(inode(7))。 - 符号链接:自身是一个独立文件(自有 inode),内容多为目标路径字符串;删除目标后链接会悬空。不会增加目标 inode 的链接数。
对照图(同一目标文件 data.bin):右为 硬链接(两个路径共享 inode);左为 符号链接(链接自己是独立 inode,里面是路径文本,需再次解析)。
flowchart TB
subgraph HL["硬链接"]
ha["/opt/app/data.bin"] --> hi["同一 inode"]
hb["/var/backup/data.bin"] --> hi
hi --> hbk["数据块"]
end
subgraph SL["符号链接"]
sp["/tmp/p"] --> si["独立 inode<br/>类型=symlink"]
si -->|"内容=/opt/app/data.bin"| hi2["解析到目标 inode"]
hi2 --> hbk2["数据块"]
end
创建方式:
ln target name # 硬链接
ln -s target name # 符号链接
目录的链接数:新建目录时 . 与 .. 会使计数呈现固定规律(子目录数 + 2),日常用 ls -ld 观察即可。
若干实践上的推论
- 重命名、同文件系统内移动:通常只改目录项里的名字或位置,inode 号不变(跨设备移动则往往是复制+删除,inode 会变)。
- 无法删除的怪异文件名:若 shell 展开困难,可通过
ls -i找到 inode,再用find等按 inode 删除。 - 正在运行的程序与更新:进程打开文件后依赖的是 inode 描述符;同名文件被替换为新 inode 时,已打开的旧 inode 仍可继续访问旧内容——这是无停机更新的一种常见底层原因。这与上面「unlinked 但仍占用空间」同属 按 inode 生命周期与引用计数管理存储 这一脉络(Wikipedia 也从共享库替换角度讨论过类似机制)。
以上现象都建立在 「目录映射名字 → inode,inode 映射数据」 这一模型上。
小结
- inode = 文件在某一文件系统内的元数据与数据块索引;文件名 存在于目录项中。
- 唯一性 是「设备 + 文件系统 + inode 号」层面的;跨文件系统则 inode 号可能重复,故硬链接不跨卷。
- 盘上 inode 记录 有固定 Inode size(常见 128/256 字节);每个文件对象通常占一个 inode,故会出现 inode 100% 用尽而
df -h仍有余量、无法新建文件 的情况;报错可能是ENOSPC,需用df -i与df -h对照判断。