LLM in Action
- AI Model Rankings
- Intro to Large Language Models - Andrej Karpathy
- Deep Dive into LLMs like ChatGPT - Andrej Karpathy
- Papers
- LLM 参数
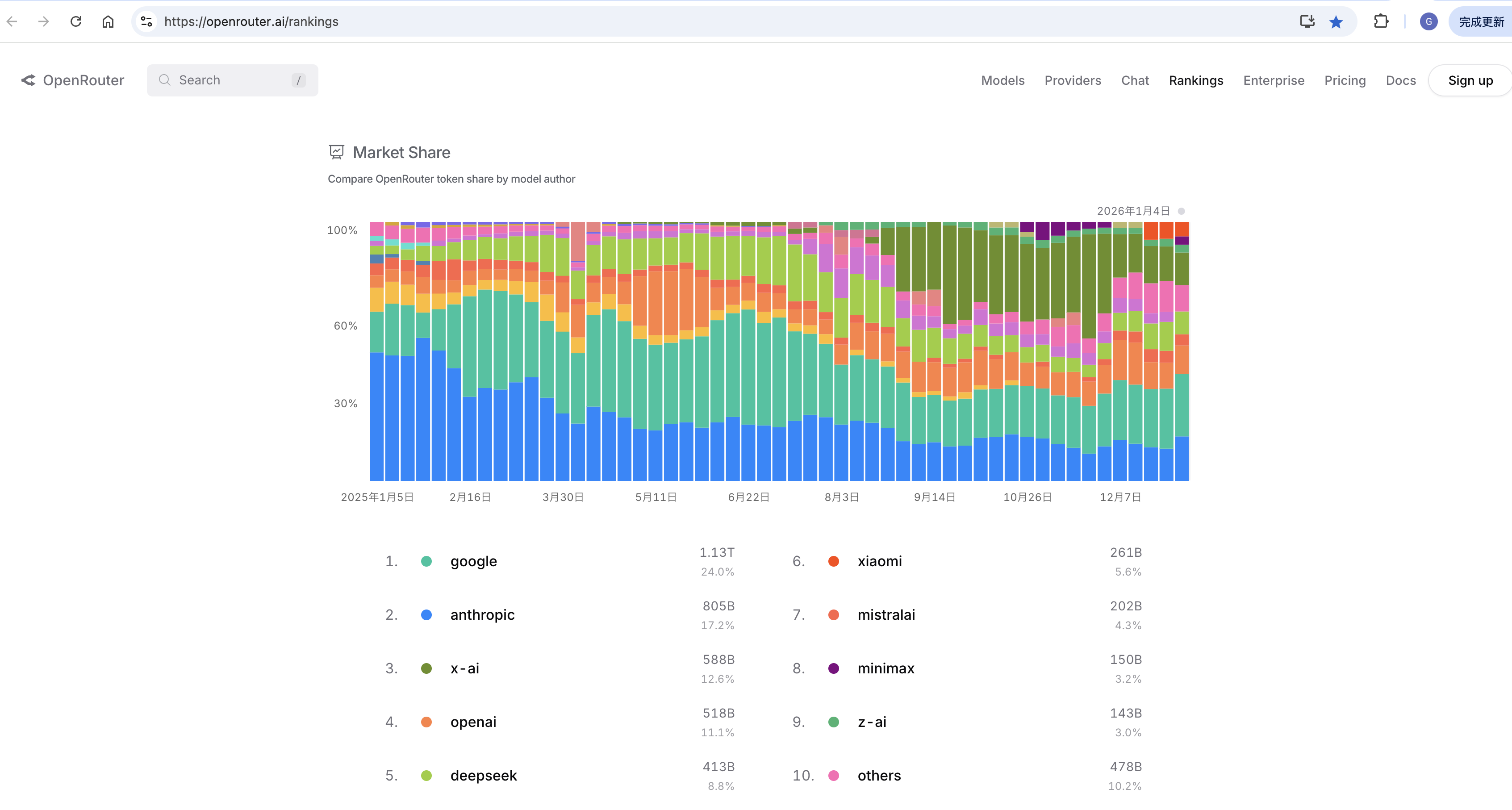
AI Model Rankings
OpenRouter
https://openrouter.ai/rankings
Artificial Analysis
https://artificialanalysis.ai/

Code Arena
https://lmarena.ai/zh/leaderboard/
Intro to Large Language Models - Andrej Karpathy
This is a 1 hour general-audience introduction to Large Language Models: the core technical component behind systems like ChatGPT, Claude, and Bard. What they are, where they are headed, comparisons and analogies to present-day operating systems, and some of the security-related challenges of this new computing paradigm.
As of November 2023 (this field moves fast!).
Context: This video is based on the slides of a talk I gave recently at the AI Security Summit. The talk was not recorded but a lot of people came to me after and told me they liked it. Seeing as I had already put in one long weekend of work to make the slides, I decided to just tune them a bit, record this round 2 of the talk and upload it here on YouTube. Pardon the random background, that’s my hotel room during the thanksgiving break.
Slides as PDF: https://drive.google.com/file/d/1pxx_… (42MB) Slides. as Keynote: https://drive.google.com/file/d/1FPUp… (140MB)
Few things I wish I said (I’ll add items here as they come up):
-
The dreams and hallucinations do not get fixed with finetuning. Finetuning just “directs” the dreams into “helpful assistant dreams”. Always be careful with what LLMs tell you, especially if they are telling you something from memory alone. That said, similar to a human, if the LLM used browsing or retrieval and the answer made its way into the “working memory” of its context window, you can trust the LLM a bit more to process that information into the final answer. But TLDR right now, do not trust what LLMs say or do. For example, in the tools section, I’d always recommend double-checking the math/code the LLM did.
- How does the LLM use a tool like the browser? It emits special words, e.g.
|BROWSER|. When the code “above” that is inferencing the LLM detects these words it captures the output that follows, sends it off to a tool, comes back with the result and continues the generation. How does the LLM know to emit these special words? Finetuning datasets teach it how and when to browse, by example. And/or the instructions for tool use can also be automatically placed in the context window (in the “system message”). - You might also enjoy my 2015 blog post “Unreasonable Effectiveness of Recurrent Neural Networks”. The way we obtain base models today is pretty much identical on a high level, except the RNN is swapped for a Transformer. http://karpathy.github.io/2015/05/21/…
- What is in the run.c file? A bit more full-featured 1000-line version hre: https://github.com/karpathy/llama2.c/…
Chapters:
Part 1: LLMs
00:00:00 Intro: Large Language Model (LLM) talk
00:00:20 LLM Inference
00:04:17 LLM Training
00:08:58 LLM dreams
00:11:22 How do they work?
00:14:14 Finetuning into an Assistant
00:17:52 Summary so far
00:21:05 Appendix: Comparisons, Labeling docs, RLHF, Synthetic data, Leaderboard
Part 2: Future of LLMs
00:25:43 LLM Scaling Laws
00:27:43 Tool Use (Browser, Calculator, Interpreter, DALL-E)
00:33:32 Multimodality (Vision, Audio)
00:35:00 Thinking, System 1/2
00:38:02 Self-improvement, LLM AlphaGo
00:40:45 LLM Customization, GPTs store
00:42:15 LLM OS
Part 3: LLM Security
00:45:43 LLM Security Intro
00:46:14 Jailbreaks
00:51:30 Prompt Injection
00:56:23 Data poisoning
00:58:37 LLM Security conclusions
End
00:59:23 Outro
Deep Dive into LLMs like ChatGPT - Andrej Karpathy
This is a general audience deep dive into the Large Language Model (LLM) AI technology that powers ChatGPT and related products. It is covers the full training stack of how the models are developed, along with mental models of how to think about their “psychology”, and how to get the best use them in practical applications. I have one “Intro to LLMs” video already from ~year ago, but that is just a re-recording of a random talk, so I wanted to loop around and do a lot more comprehensive version.
Papers
- https://papers.cool
- https://www.aminer.cn/
- https://consensus.app/
可通过元宝上传 pdf 总结精读。
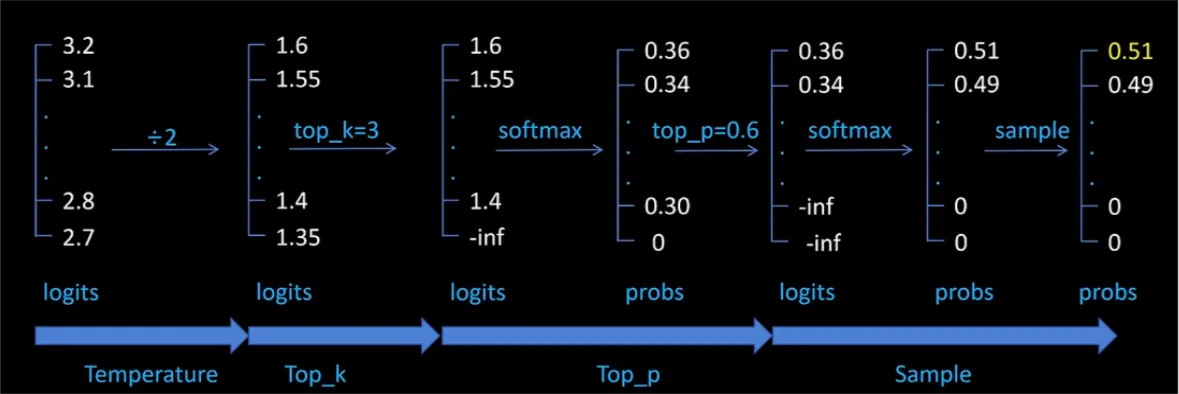
LLM 参数
影响大模型输出的主要参数
- temperature
- 解释:控制 softmax 输出的平滑性,temperature 越小,输出越固定
- 使用场景
- temperature=0.6,适合推理模型及分析场景(更合适推理模型,DeepSeek 论文里推荐)
- temperature<0.1,严谨的智能问答、text2sql、实体提取等场景(更适合通用模型)
- top_k
- 解释:过滤前 k 个 token 候选项
- 使用场景:top_k<5 适合确定性分类场景(如意图识别),避免非候选意图集中的结果出现,以及确保专业性,避免非专业术语出现
- top_p
- 根据候选 token 的概率从大到小,累积概率达到 p
- 使用场景:同 top_k,确保回复的专业性
- top_p (0.8-0.9): 适合代码生成/数学解题
- top_p (0.9-0.95): 适合数据抽取/实时回答
- top_p (0.95-0.99): 适合创意写作/营销文案
- num_beams
- 解释:保留的候选集数目,减少回答陷入局部最优的情况
- 使用场景
- num_beams>1: 适合精确度要求比较高的场景
- num_beams=1 (默认): 适合快速生成的场景
分析场景,一般采用的推理模型,建议参数选用 temperature=0.6,num_beams=1。
各个参数的作用先后顺序