Machine Learning in Action
- Vibe coding
- Prompt Engineering Guide
- RAG (Retrieval-Augmented Generation) 检索增强生成
- Model Context Protocol (MCP)
- TTS (Text To Speech 从文本到语音)
- 静态的图像识别技术 OpenCV
- 推荐系统 (Recommender systems)
- Stable Diffusion
- 了解如何避免过拟合,进而能够准确泛化模型外部的数据
- Sora (OpenAI)
Vibe coding
Vibe coding is an AI-dependent programming technique where a person describes a problem in a few sentences as a prompt to a large language model (LLM) tuned for coding. The LLM generates software, shifting the programmer’s role from manual coding to guiding, testing, and refining the AI-generated source code. Vibe coding is claimed by its advocates(倡导者) to allow even amateur(业余的) programmers to produce software without the extensive training and skills previously required for software engineering. The term was introduced by Andrej Karpathy in February 2025 and listed in the Merriam-Webster Dictionary the following month as a “slang & trending” noun.
More: Vibe Coding - AI-Assisted Coding for Non-Developers
I’m a big fan of Cursor for coding with AI, and this movement now has a name — “vibe coding” — which allows people to create programs by describing what they want in natural language and letting AI handle much of the actual coding.
What is Vibe Coding?
Vibe coding is a term for coding with the assistance of AI — essentially, using AI tools to do the heavy lifting of writing code while you focus on guiding the process with ideas and descriptions. The phrase started as a Silicon Valley buzzword (coined by (创造) AI expert Andrej Karpathy) to describe “using AI tools … for the heavy lifting in coding to quickly build software”. In vibe coding, you don’t write every line of code by hand. Instead, you communicate what you want (the “vibe” of the program or feature), and the AI generates the code for you.
This approach marks a shift in how software can be created. Traditionally, developing software meant knowing programming languages and writing precise syntax. But AI advancements are changing that paradigm. Modern AI coding assistants can understand plain English problem descriptions and produce working code. As Karpathy humorously noted, “the hottest new programming language is English” meaning that describing what your program should do in English can be as effective as writing the code yourself. Vibe coding embraces this shift from manual coding to AI-assisted generation.
The term “vibe coding” gained popularity after Karpathy shared his experience of building software by fully giving in to the vibes — essentially forgetting about the code and just iteratively prompting the AI. “It’s not really coding — I just see stuff, say stuff, run stuff, and copy-paste stuff, and it mostly works,” he wrote, highlighting how different this feels from traditional programming. In other words, vibe coding is more like conversing with your computer about what you want, rather than manually typing out every function. This idea of programming by chat (or even by voice) has opened up programming to people who might not be fluent in any coding language. One enthusiast described vibe coding as programming “by chatting with LLMs or even by voice” instead of writing code directly.
AI assistance is lowering the barrier to entry for creating software. People with ideas but little coding experience can now build prototypes by describing their vision to an AI. Meanwhile, even experienced developers are using these tools to automate rote tasks and speed up development. AI can generate boilerplate code (the repetitive, standard parts of programs) so that humans can focus on higher-level design. It’s also enabling much faster prototyping — what might take days or weeks to code from scratch can sometimes be achieved in a few hours of back-and-forth with an AI. This democratisation of coding means more people can bring their ideas to life. “Software engineers have remained in hot demand… but the arrival of AI that can ‘vibe’ code into existence has some industry leaders predicting big changes,” with experts expecting software engineering to look “very different by the end of 2025” due to these AI capabilities.
How Vibe Coding Works
Vibe coding works through a tight interplay between human guidance and AI generation. Humans provide instructions, descriptions, or goals in everyday language, and AI tools translate those into code. The process is typically iterative (重复的) and interactive (交互的):
-
You describe what you want: For example, you might say “Create a simple web page that displays the current weather for a city the user enters.” This description (called a prompt (提示词)) is given to an AI coding assistant.
-
The AI generates code: The AI, which has been trained on vast amounts of programming knowledge, will attempt to produce code that fulfills your request. It might write the
HTML,CSS, andJavaScriptneeded for the weather page automatically. Essentially, the AI acts like an autocomplete on steroids — it predicts the code that matches your description. -
You review and refine (完善): After the AI provides some code, you (the human) check it. Does the web page work? Maybe the AI’s first attempt has issues or isn’t quite what you envisioned. You then tell the AI what to change or fix. For instance, “The page looks too plain, make the design more colorful and add error handling if the city is not found.” The AI will take this feedback and modify the code accordingly.
-
Iterate as needed: This cycle continues — describe changes, get new code, test it out — until you’re satisfied with the result. Because the AI can produce a lot of code quickly, you might go through multiple iterations in a short time.
Modern AI coding tools are quite powerful. They not only generate code from scratch but can also help debug and improve it. For example, if the code doesn’t run due to an error, you can paste the error message into the AI chat and ask for help. Karpathy noted that when he gets error messages, he simply copies and pastes them into the AI and “usually, that fixes it”. The AI can read the error and suggest a correction in code. This means you can troubleshoot problems even if you don’t fully understand the programming error — the AI will explain or fix it for you.
Natural language prompts replace traditional syntax-heavy coding in vibe coding. You don’t need to remember the exact syntax for a for-loop or the parameters of a library function — you just tell the AI in plain language what you want to achieve, and it writes the syntax for you. It’s as if you’re pair-programming with a very knowledgeable assistant: you provide the intent, the assistant writes the actual code. Tools like GitHub Copilot have demonstrated this capability well: “When provided with a programming problem in natural language, Copilot is capable of generating solution code.” It can even turn comments (written in English) into runnable code and fill in entire functions for you. Vibe coding extends this concept to bigger tasks — even creating whole modules or simple apps from a high-level description.
Because the AI handles syntax and heavy lifting, vibe coding can dramatically shorten the programming learning curve. Tasks that would have required learning a programming language and framework can now be done by describing the end goal. One Cambridge researcher observed that “for a total beginner who’s just getting a feel for how coding works, it can be incredibly satisfying to build something that works in the space of an hour” using these AI-assisted methods. In other words, someone with no programming experience can potentially create a simple working app extremely fast — something previously unimaginable without months of learning.
It’s important to note that vibe coding is usually an iterative process. The AI might not get everything right on the first try. You guide it like a junior programmer: step by step. Humans still have to have a vision of the final product and break the project into manageable tasks or prompts. But the AI handles the tedious parts and even helps catch mistakes along the way. This synergy between humans and AI — human sets the direction, AI executes and suggests — is at the heart of how vibe coding works.
Tools for Vibe Coding
Several tools and platforms have been developed to facilitate vibe coding. These range from AI-enhanced code editors to web-based coding assistants. Here’s an overview of some popular tools and what they offer:
Cursor
Cursor is an AI-powered code editor based on Visual Studio Code (VS Code). It integrates AI directly into your coding environment. Cursor provides a sidebar chat (called Composer) where you can instruct the AI, and it will write or edit code in your files. One of Cursor’s core features is the ability to “explore code, write new features, and modify existing code” via natural language in the Composer chat. It has two modes: a normal mode and an “Agent” mode. In normal mode, it acts like a smart assistant that waits for your prompts and then makes code changes which you review. In agent mode, it can take higher-level commands and execute multiple steps (even running commands or managing files) independently. Cursor is known for giving the user much control: for example, you explicitly choose which files or sections of code the AI can see, showing you diffs (changes) before applying them. This means you always get to review the AI’s output and accept or reject it. There are also handy “AI buttons” in the interface — e.g. a “Fix with AI” button appears when you encounter an error, which triggers the AI to suggest a fix. Because it’s built on a familiar editor (VS Code), developers find it comfortable, and non-developers benefit from the interface that visually highlights what the AI is doing. Cursor is currently one of the flagship tools for vibe coding, often mentioned alongside the vibe coding trend.
GitHub Copilot
Copilot is an AI pair-programmer developed by GitHub and OpenAI. It works as an extension in code editors like VS Code, and it autocompletes code as you type. While Copilot originally focused on suggesting the next line or block of code, it has evolved also to include a chat mode (Copilot Chat) where you can ask coding questions in natural language. Copilot is very useful for vibe coding because you can, for example, write a comment like // sort a list of strings alphabetically in your code, and Copilot will generate the code to do that below the comment (注释). It can produce solution code from a natural language description of a problem. Copilot’s strength is in assisting you as you write — it’s constantly suggesting possible implementations. For a tech-savvy non-developer, Copilot can feel like a smart autocomplete that understands your intent. However, it’s usually used by folks at least dabbling in writing code, as it integrates into the coding environment rather than a chat interface alone. It’s a great tool if you want to start learning actual code with AI help.
ChatGPT and other LLM-based assistants
OpenAI’s ChatGPT, Anthropic’s Claude, and similar large language model (LLM) chatbots can also be used for vibe coding even though they are not dedicated coding IDEs. Many people simply open ChatGPT in their browser and describe the program they want. ChatGPT can output code in formatted blocks for you to copy-paste into your environment. For example, you could say “I want a simple HTML page with a form to input a number and a button that calculates the square of that number using JavaScript” — ChatGPT will happily generate the HTML and JS code. It will even explain the code if you ask. The limitation is that ChatGPT doesn’t run or test the code, so you have to do that part. However, as a coding assistant, it’s very powerful. There are also plugins and enhancements (like ChatGPT’s Code Interpreter environment, and community plugins) that can execute code or manage files, inching it closer to a full-vibe coding tool. Similarly, Claude by Anthropic is known for handling very large prompts (which can be useful if you feed it a lot of existing code and ask for modifications).
Windsurf AI
Windsurf is another AI-driven code editor/IDE, often compared to Cursor. Windsurf takes a slightly different philosophy: it has an agentic mode by default that tries to do things more automatically for you, making the experience very streamlined for the user. For instance, Windsurf will automatically pull in relevant parts of your codebase and even run the code to show you results as it generates changes. The idea is to keep you “in the flow” — describe what you want, and Windsurf’s AI will directly apply it and show the outcome, allowing quick iterations. Cursor, by contrast, makes you explicitly accept changes. Each approach has its pros: Windsurf is a bit more “it-just-works” with fewer manual steps, which might appeal to non-developers who want simplicity, whereas Cursor provides more checkpoints and manual control (appealing if you want to inspect every change). Both are useful for vibe coding; it often depends on user preference.
Prompt Engineering Guide
替代你的不是 AI,而是会用 AI 的人
提示工程(Prompt Engineering)是一门较新的学科,关注提示词开发和优化,帮助用户将大语言模型(Large Language Model, LLM)用于各场景和研究领域。 掌握了提示工程相关技能将有助于用户更好地了解大型语言模型的能力和局限性。
More: Prompt engineering
RAG (Retrieval-Augmented Generation) 检索增强生成
Retrieval-augmented generation (
RAG) is a technique that enables generative artificial intelligence (Gen AI) models to retrieve and incorporate new information. It modifies interactions with a large language model (LLM) so that the model responds to user queries with reference to a specified set of documents, using this information to supplement information from its pre-existing training data. This allows LLMs to use domain-specific and/or updated information. Use cases include providing chatbot access to internal company data or generating responses based on authoritative sources.
参考:https://aws.amazon.com/cn/what-is/retrieval-augmented-generation/
检索增强生成 (RAG) 是指对大型语言模型输出进行优化,使其能够在生成响应之前引用训练数据来源之外的权威知识库。大型语言模型 (LLM) 用海量数据进行训练,使用数十亿个参数为回答问题、翻译语言和完成句子等任务生成原始输出。在 LLM 本就强大的功能基础上,RAG 将其扩展为能访问特定领域或组织的内部知识库,所有这些都无需重新训练模型。这是一种经济高效地改进 LLM 输出的方法,让它在各种情境下都能保持相关性、准确性和实用性。
如果没有 RAG,LLM 会接受用户输入,并根据它所接受训练的信息或它已经知道的信息创建响应。RAG 引入了一个信息检索组件,该组件利用用户输入首先从新数据源提取信息。用户查询和相关信息都提供给 LLM。LLM 使用新知识及其训练数据来创建更好的响应。以下各部分概述了该过程。
- 创建外部数据
LLM 原始训练数据集之外的新数据称为外部数据。它可以来自多个数据来源,例如 API、数据库或文档存储库。数据可能以各种格式存在,例如文件、数据库记录或长篇文本。另一种称为嵌入语言模型的 AI 技术将数据转换为数字表示形式并将其存储在向量数据库中。这个过程会创建一个生成式人工智能模型可以理解的知识库。
- 检索相关信息
下一步是执行相关性搜索。用户查询将转换为向量表示形式,并与向量数据库匹配。例如,考虑一个可以回答组织的人力资源问题的智能聊天机器人。如果员工搜索:“我有多少年假?”,系统将检索年假政策文件以及员工个人过去的休假记录。这些特定文件将被退回,因为它们与员工输入的内容高度相关。相关性是使用数学向量计算和表示法计算和建立的。
- 增强 LLM 提示
接下来,RAG 模型通过在上下文中添加检索到的相关数据来增强用户输入(或提示)。此步骤使用提示工程技术与 LLM 进行有效沟通。增强提示允许大型语言模型为用户查询生成准确的答案。
- 更新外部数据
下一个问题可能是——如果外部数据过时了怎么办? 要维护当前信息以供检索,请异步更新文档并更新文档的嵌入表示形式。可以通过自动化实时流程或定期批处理来执行此操作。这是数据分析中常见的挑战——可以使用不同的数据科学方法进行变更管理。
下图显示了将 RAG 与 LLM 配合使用的概念流程:
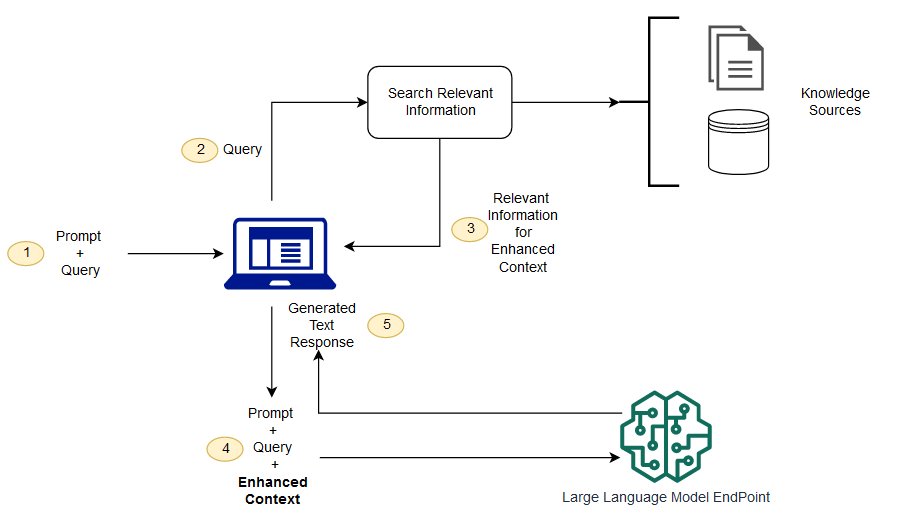
如果无法一次性给 LLM 喂太多知识,那就少喂点,根据用户的具体提问去找到和它最相关的知识,把这部分精选后的知识喂给 LLM。应用程序要提前根据用户问题,对海量材料进行过滤,把最相关的内容截取出来发给大模型。这种方法就是我们经常在各种技术方案中看到的:RAG (Retrieval-Augmented Generation),检索增强生成技术。通过检索出和问题相关的内容,来辅助增强生成答案的准确性。
RAG 需要注意两个问题:
- 检索结果和解答问题需要参考的资料越相关,生成结果越准确
- 检索出过多的内容,又会引入更多的噪声影响 LLM 注意力,增加幻觉风险,生成的质量反而降低
向量相似度检索,就是基于这种方式,使用训练好的神经网络模型去“理解”文本,得到对应的高维向量。再通过数学上的相似度计算,来判断文本之间的语义相关性。
通过模型把各种内容(词、句子、图片等)转化成高维向量的过程,称为 Embedding(嵌入)。但是,和 LLM 有上下文长度限制一样,使用模型进行 Embedding 时,对输入的有长度也是有限制,不能直接把一篇文章扔给模型做 Embedding,通常需要对内容进行一定的切分 (Chunk),比如按照段落或者按照句子进行 Chunk。
一篇文章 -> Chunk (文本分块) -> Embedding (向量化) -> 一些列长度相等的向量
当把文档按如上流程 Embedding 之后,就可以得到这篇文档的向量表示 [[..], [..], [..]]。进一步可以把它们存储到向量数据库 (VectorDB)。
对于一个给定的待搜索文本,就可以把它以用同样的方式进行 Embedding,然后在向量数据库中执行相关性查找,这样可以快速找到它语义相近的文本。
Chunk + Embedding + VectorDB = RAG
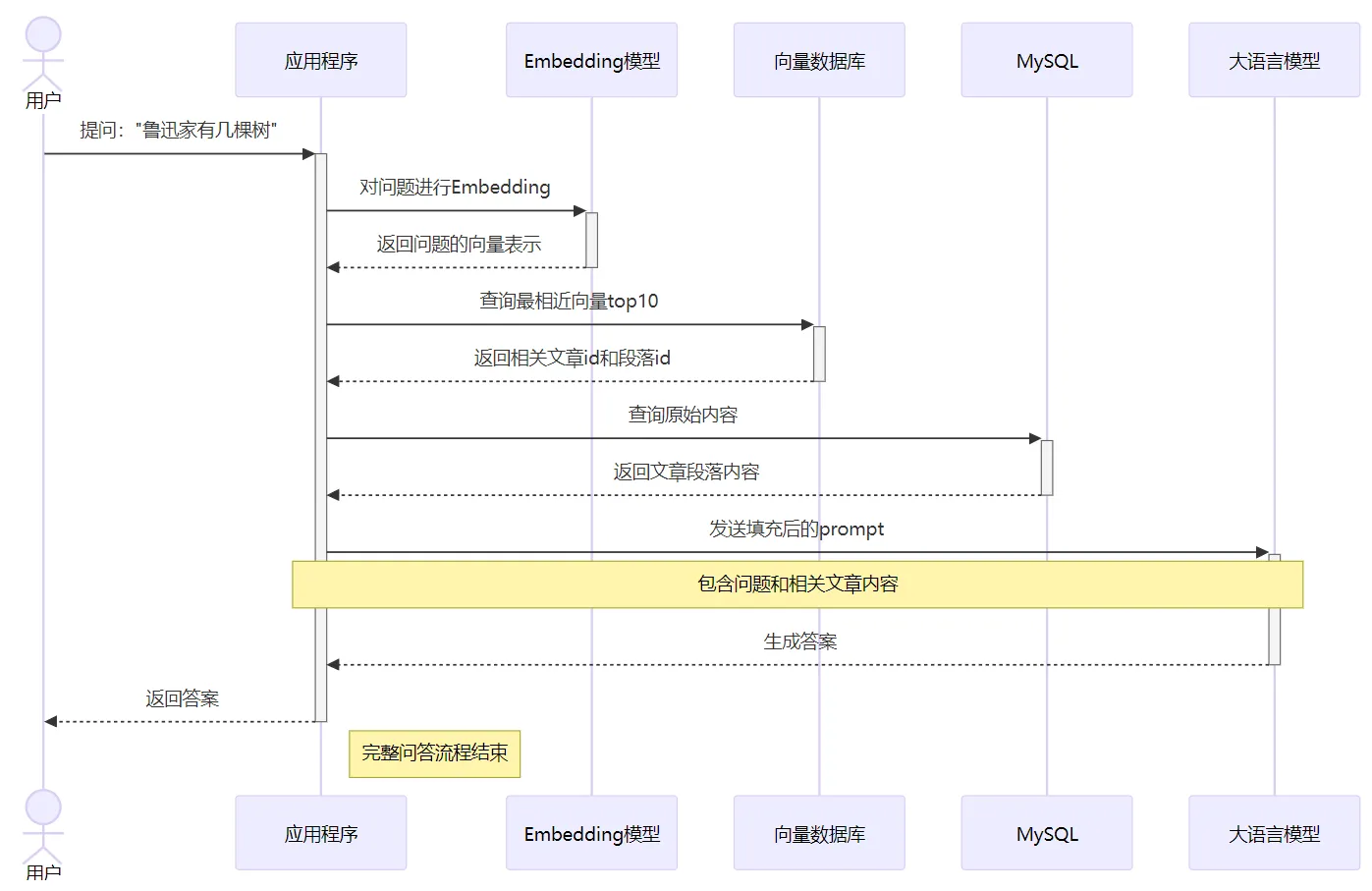
这就是所谓的检索增强生成:通过检索,拿到和问题相关内容,去增强 prompt,从而增强大模型生成的回答质量。RAG 完整的流程如下:
Model Context Protocol (MCP)
MCP is an open protocol that standardizes how applications provide context to LLMs. Think of MCP like a USB-C port for AI applications. Just as USB-C provides a standardized way to connect your devices to various peripherals and accessories, MCP provides a standardized way to connect AI models to different data sources and tools.
Why MCP?
MCP helps you build agents and complex workflows on top of LLMs. LLMs frequently need to integrate with data and tools, and MCP provides:
- A growing list of pre-built integrations that your LLM can directly plug into
- The flexibility to switch between LLM providers and vendors
- Best practices for securing your data within your infrastructure
General architecture
At its core, MCP follows a client-server architecture where a host application can connect to multiple servers:
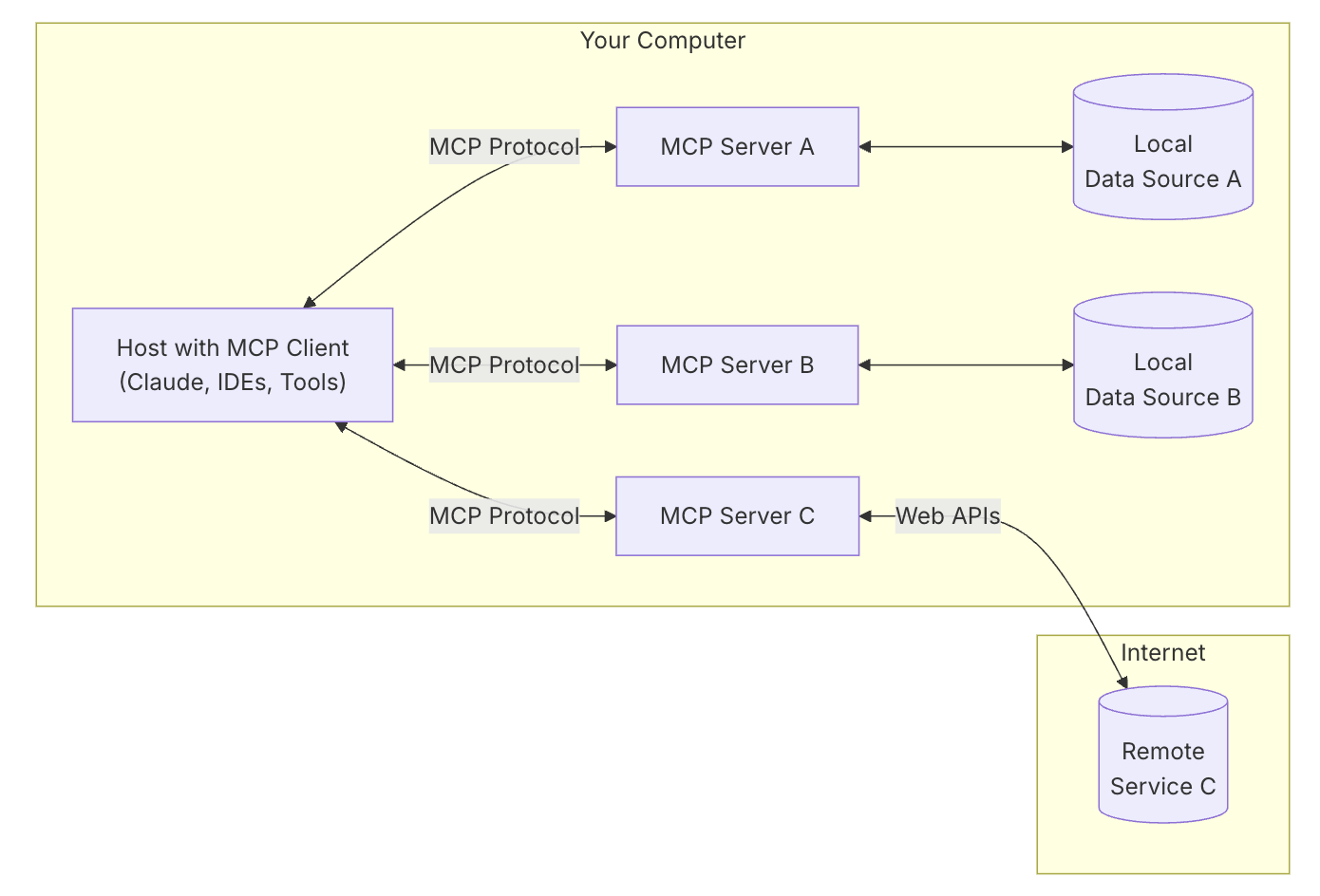
- MCP Hosts: Programs like Claude Desktop, IDEs, or AI tools that want to access data through MCP
- MCP Clients: Protocol clients that maintain 1:1 connections with servers
- MCP Servers: Lightweight programs that each expose specific capabilities through the standardized Model Context Protocol
- Local Data Sources: Your computer’s files, databases, and services that MCP servers can securely access
- Remote Services: External systems available over the internet (e.g., through APIs) that MCP servers can connect to
TTS (Text To Speech 从文本到语音)
它是同时运用语言学和心理学的杰出之作,在内置芯片的支持之下,通过神经网络的设计,把文字智能地转化为自然语音流。TTS技术对文本文件进行实时转换,转换时间之短可以秒计算。在其特有智能语音控制器作用下,文本输出的语音音律流畅,使得听者在听取信息时感觉自然,毫无机器语音输出的冷漠与生涩感。
- GPT-SoVITS指南
- GPT-SoVITS-WebUI A Powerful Few-shot Voice Conversion and Text-to-Speech WebUI.
- 耗时两个月自主研发的低成本AI音色克隆软件
- GPT-SoVITS语音合成官方镜像,3080Ti卡测试通过
测试使用:
- 各种游戏600多个角色在线试用:https://gsv.acgnai.top/
- zero shot试用:https://gsv-zs.acgnai.top/&https://huggingface.co/spaces/lj1995/GPT-SoVITS-v2
静态的图像识别技术 OpenCV
OpenCV(Open Source Computer Vision Library)是一个开源的计算机视觉和机器学习库,广泛应用于静态图像识别技术中。它由英特尔公司开发,并且支持多种编程语言,包括C++、Python、Java和MATLAB,适用于多个操作系统,如Windows、Linux、Mac OS、Android和iOS。
推荐系统 (Recommender systems)
召回
推荐系统如何根据已有的用户画像和内容画像去推荐,涉及到两个关键问题:召回和排序。
召回(match) 指从全量信息集合中触发尽可能多的正确结果,并将结果返回给排序。
召回的方式有多种:协同过滤、主题模型、内容召回和热点召回等,而排序(rank)则是对所有召回的内容进行打分排序,选出得分最高的几个结果推荐给用户。
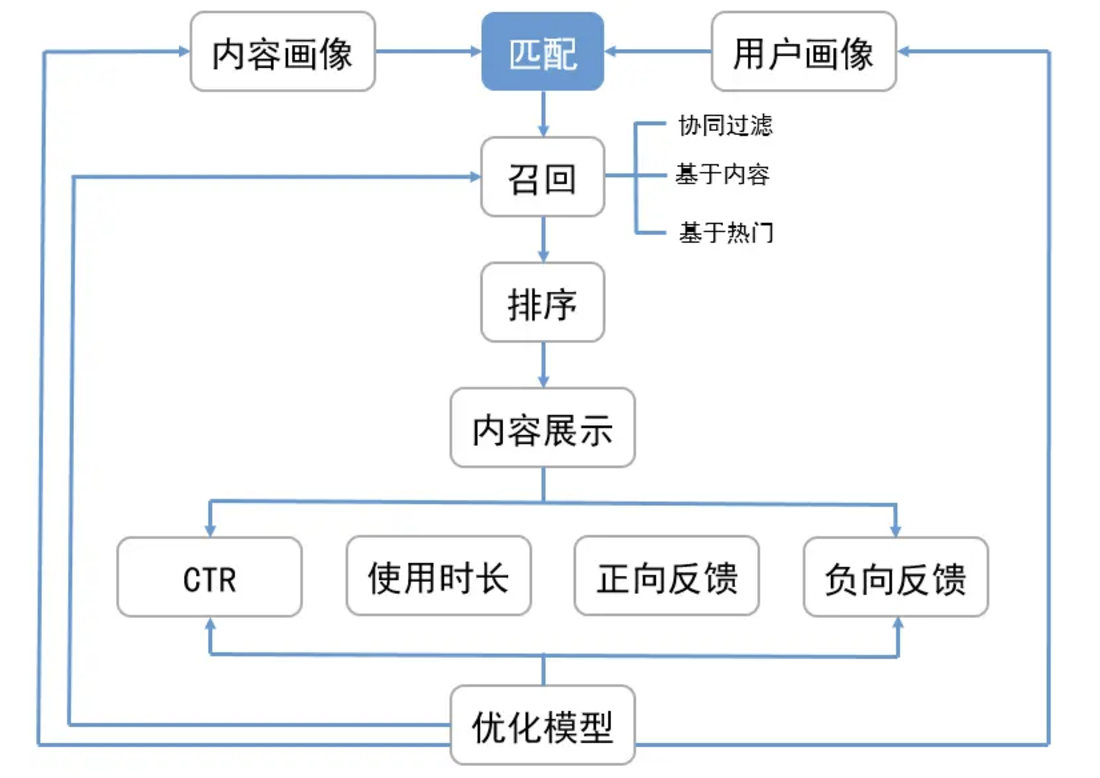
在搜索系统中,用户会输入明确的搜索词,根据搜索词进行内容的召回和呈现即可,但在推荐系统中,用户没有一个明确的检索词(Query)输入,推荐系统需要做的,就是根据用户画像、内容画像等各种信息为用户推荐他可能感兴趣的内容。另外,由于没有明确的检索词,推荐系统就需要从整个信息集合中挑选出尽可能多的相关结果,同时又需要剔除相关性较弱的结果,降低排序阶段的工作量。
怎样的召回策略是好的?
召回策略的评估主要根据两个评价指标:召回率和准确率。
- 召回率 (Recall) = 系统检索到的相关内容 / 系统所有相关的内容总数
- 准确率 (Precision) = 系统检索到的相关内容 / 系统所有检索到的内容总数
例如在搜索情境下,当用户搜索“北京大学”时,想看到北大相关的网站、新闻等,系统返回了以下三个网页:
a. 北京大学保安考上研究生;
b. 北京互联网工作招聘;
c. 大学生活是什么样的;
可以看到,只有 a 是用户真正想看到的,其他两个和用户搜索词无关,而事实上数据库里还有这种网页:
d. 北大开学季;
e. 未名湖的景色;
d、e 这两个网页没被搜索到,但它们和“北京大学”的相关度其实是超过 b、c 的,也就是应该被搜索(被召回)到但实际并没有显示在结果里,所以,这个系统的:
召回率 = a / (a + d + e) = 0.33
准确率 = a / (a + b + c) = 0.33
这是搜索情境下的召回率和准确率,而“推荐”其实就是没有检索词输入时的搜索,例如,用户并没有输入“北京大学”这样的关键词,但其实他是北京大学的学生,对自己学校相关的新闻很感兴趣,推荐系统的召回就是要根据用户画像、内容画像等各种信息,为用户提供他感兴趣的相关内容,所以也存在召回率和准确率的问题。
召回率和准确率有时存在相互制衡的情况,好的召回策略应该在保证高准确率的情况下也保证高召回率。
今日头条的召回策略
今日头条作为业界推荐系统方面的顶级选手,不免有人会好奇,它的召回策略是怎样的?
今日头条的算法架构师曾在接受采访时表示,今日头条有一个世界范围内比较大的在线训练推荐模型,包括几百亿特征和几十亿的向量特征。但因为头条目前的内容量非常大,加上小视频内容有千万级别,推荐系统不可能所有内容全部由模型预估。所以需要设计一些召回策略,从庞大内容中筛选一个模型组成内容库。
召回策略种类有很多,今日头条主要用的是倒排的思路。离线维护一个倒排,这个倒排的key可以是分类,topic,实体,来源等,排序考虑热度、新鲜度、动作等。线上召回可以迅速从倒排中根据用户兴趣标签对内容做截断,高效地从很大的内容库中筛选比较靠谱的一小部分内容。基于召回策略,把一个海量、无法把握的内容库,变成一个相对小、可以把握的内容库,再进入推荐模型。这样有效平衡了计算成本和效果。
协同过滤 (Collaborative filtering)
Collaborative filtering (CF) is, besides content-based filtering, one of two major techniques used by recommender systems. Collaborative filtering has two senses, a narrow one and a more general one.
In the newer, narrower sense, collaborative filtering is a method of making automatic predictions (filtering) about a user’s interests by utilizing preferences or taste information collected from many users (collaborating). This approach assumes that if persons A and B share similar opinions on one issue, they are more likely to agree on other issues compared to a random pairing of A with another person. For instance, a collaborative filtering system for television programming could predict which shows a user might enjoy based on a limited list of the user’s tastes (likes or dislikes). These predictions are specific to the user, but use information gleaned from many users. This differs from the simpler approach of giving an average (non-specific) score for each item of interest, for example based on its number of votes.
In the more general sense, collaborative filtering is the process of filtering information or patterns using techniques involving collaboration among multiple agents, viewpoints, data sources, etc. Applications of collaborative filtering typically involve very large data sets. Collaborative filtering methods have been applied to many kinds of data including: sensing and monitoring data, such as in mineral exploration, environmental sensing over large areas or multiple sensors; financial data, such as financial service institutions that integrate many financial sources; and user data from electronic commerce and web applications.
协同过滤(collaborative filtering)是一种在推荐系统中广泛使用的技术。该技术通过分析用户或者事物之间的相似性(“协同”),来预测用户可能感兴趣的内容并将此内容推荐给用户。这里的相似性可以是人口特征(性别、年龄、居住地等)的相似性,也可以是历史浏览内容的相似性(比如都关注过和中餐相关的内容),还可以是个人通过一定机制给予某个事物的回应(比如一些教学网站会让用户对授课人进行评分)。比如,用户A和B都是居住在北京的年龄在20-30岁的女性,并且都关注过化妆品和衣物相关的内容。这种情况下,协同过滤可能会认为,A和B相似程度很高。于是可能会把A关注B没有关注的内容推荐给B,反之亦然。
发展简史
电子商务的推荐系统
最著名的电子商务推荐系统应属亚马逊网络书店,顾客选择一本自己感兴趣的书籍,马上会在底下看到一行“Customer Who Bought This Item Also Bought”,亚马逊是在“对同样一本书有兴趣的读者们兴趣在某种程度上相近”的假设前提下提供这样的推荐,此举也成为亚马逊网络书店为人所津津乐道的一项服务,各网络书店也跟进做这样的推荐服务如台湾的博客来网络书店。另外一个例子是Facebook的广告,系统根据个人资料、周遭朋友感兴趣的广告等等对个人提供广告推销,也是一项协同过滤重要的里程碑,和前二者Tapestry、GroupLens不同的是在这里虽然商业气息浓厚同时还是带给用户很大的方便。以上为三项协同过滤发展上重要的里程碑,从早期单一系统内的邮件、文件过滤,到跨系统的新闻、电影、音乐过滤,乃至于今日横行互联网的电子商务,虽然目的不太相同,但带给用户的方便是大家都不能否定的。
推荐系统如何召回
召回策略主要包含两大类,即基于内容匹配的召回和基于系统过滤的召回。
- 基于内容匹配的召回
内容匹配即将用户画像与内容画像进行匹配,又分为基于内容标签的匹配和基于知识的匹配。
例如,A用户的用户画像中有一条标签是“杨幂的粉丝”,那么在他看了《绣春刀2》这部杨幂主演的电影后,可以为他推荐杨幂主演的其他电影或电视剧,这就是基于内容标签的匹配。
基于知识的匹配则更进一步,需要系统存储一条“知识”——《绣春刀2》是《绣春刀1》的续集,这样就可以为看过《绣春刀2》的用户推荐《绣春刀1》。基于内容匹配的召回较为简单、刻板,召回率较高,但准确率较低(因为标签匹配并不一定代表真的感兴趣),比较适用于冷启动的语义环境。
- 基于协同过滤的召回
如果仅使用上述较简单的召回策略,推荐内容会较为单一,目前业界最常用的基于协同过滤的召回,它又分为基于用户、基于项目和基于模型的协同过滤。
基于用户(User-based)的协同推荐是最基础的,它的基础假设是“相似的人会有相同的喜好”,推荐方法是,发现与用户相似的其他用户,用用户的浏览记录做相互推荐。例如,通过浏览记录发现用户一与用户二的偏好类似,就将用户一点击的内容推送给用户二。
基于项目(Item-based)的协同过滤中的“项目”可以视场景定为信息流产品中的“内容”或者电商平台中的“商品”,其基础假设是“喜欢一个物品的用户会喜欢相似的物品”计算项目之间的相似性,再根据用户的历史偏好信息将类似的物品推荐给该用户。
基于模型的协同过滤推荐(Model-based)就是基于样本的用户喜好信息,训练一个推荐模型,然后根据实时的用户喜好的信息进行预测推荐。
总体来说,基于协同过滤的召回即建立用户和内容间的行为矩阵,依据“相似性”进行分发。这种方式准确率较高,但存在一定程度的冷启动问题。
在实际运用中,采用单一召回策略的推荐结果实际会非常粗糙,通用的解决方法是将规则打散,将上述几种召回方式中提炼到的各种细小特征赋予权重,分别打分,并计算总分值,预测 CTR。
例如,根据内容匹配召回策略,用户A和内容甲的标签匹配度为0.6,同时,根据协同过滤召回策略,应该将内容甲推荐给用户A的可能性为0.7,那么就为0.6和0.7这两个数值分别赋予权重(这个权重可能会根据算法的具体情况来确定),得出总分,用它来预测用户可能点击的概率,从而决定是否返回该结果。
refer
Stable Diffusion
Stable Diffusion 是一种基于潜在扩散模型(Latent Diffusion Models, LDMs)的文图生成(text-to-image)模型,由 CompVis、Stability AI 和 LAION 研究人员实现并开源。该模型的核心思想是通过前向扩散过程和反向扩散过程来生成图像,其中前向扩散过程将高斯噪声加入到初始图像中,逐步增强噪声以达到所需的分布状态;反向扩散过程则是在这个过程中去除噪声,从而生成与文本描述相符的图像。
Stable Diffusion is a deep learning, text-to-image model released in 2022 based on diffusion techniques. The generative artificial intelligence technology is the premier product of Stability AI and is considered to be a part of the ongoing artificial intelligence boom.
It is primarily used to generate detailed images conditioned on text descriptions, though it can also be applied to other tasks such as inpainting, outpainting, and generating image-to-image translations guided by a text prompt. Its development involved researchers from the CompVis Group at Ludwig Maximilian University of Munich and Runway with a computational donation from Stability and training data from non-profit organizations.
Stable Diffusion is a latent diffusion model, a kind of deep generative artificial neural network. Its code and model weights have been released publicly, and it can run on most consumer hardware equipped with a modest GPU with at least 4 GB VRAM. This marked a departure from previous proprietary text-to-image models such as DALL-E and Midjourney which were accessible only via cloud services.
相关工具
stable-diffusion-webui
A web interface for Stable Diffusion, implemented using Gradio library.
sd-webui-controlnet
The WebUI extension for ControlNet and other injection-based SD controls.
https://github.com/AUTOMATIC1111/stable-diffusion-webui
了解如何避免过拟合,进而能够准确泛化模型外部的数据
https://www.ibm.com/cn-zh/topics/overfitting
在统计学和机器学习中,偏差和方差是两个非常重要的概念。它们都描述了预测模型的错误,但从不同的角度。
偏差(Bias):描述的是预测值(估计值)的期望与真实值之间的差距。偏差越大,表示预测模型的预测平均值与真实值越偏离,模型越偏离真实数据,也就是说模型欠拟合。
方差(Variance):描述的是预测值的变化范围,离散程度,也就是该量的离散程度或者说稳定性。方差越大,数据的分布越分散,模型的预测结果对于学习样本的扰动越敏感,模型过拟合。
偏差和方差通常存在一个权衡的关系,这被称为偏差-方差权衡(Bias-Variance Tradeoff)。如果模型的复杂度较低,拟合的能力较弱,可能会出现偏差较大,但方差较小的情况,这被称为欠拟合(Underfitting)。如果模型的复杂度较高,拟合的能力过强,可能会出现偏差较小,但方差较大的情况,这被称为过拟合(Overfitting)。理想的模型应该在偏差和方差之间找到一个好的平衡。
什么是过拟合 (overfitting)?
过拟合是一个数据科学概念,在统计模型与其训练数据完全拟合时,就会出现过拟合。在这种情况下,遗憾的是,无法对看不到的数据执行该算法,因而违背了算法的目的。通过将模型泛化至新数据,最终我们能够每天使用机器学习算法做出预测,并对数据进行分类。
在构建机器学习算法时,会利用样本数据集来训练模型。然而,当模型在样本数据上训练的时间过长或模型过于复杂时,它就会开始学习数据集中的”噪声”或不相关的信息。当模型记住”噪声”并且与训练集过于紧密地拟合时,模型就会变得过拟合,无法很好地泛化至新数据。如果模型无法很好地泛化至新数据,那么就无法执行预期的分类或预测任务。
低错误率和高方差是过拟合的明显标志。为了防止出现这种行为,通常会将部分训练数据集留作”测试集”,用来检查是否存在过拟合。如果训练数据的错误率低,测试数据的错误率高,那么就表示过拟合。
过拟合与欠拟合
如果过度训练模型或模型过于复杂导致出现过拟合,那么逻辑上的预防应对措施就是提前暂停训练过程(也称为”早停法”),或者通过消除不太相关的输入来降低模型的复杂性。但是,如果过早暂停或排除太多重要特征,就可能会走向另一个极端 - 模型欠拟合。当模型没有训练足够长的时间,或者输入变量不够显著,无法确定输入变量和输出变量之间的有意义关系时,就会发生欠拟合。
在这两种情况下,模型都无法在训练数据集中确定主导趋势。因此,在泛化到看不见的数据上时,欠拟合的表现也不佳。 但与过拟合不同,欠拟合的模型在预测时的偏差较高,方差较小。这就是偏差方差权衡,在欠拟合的模型转变为过拟合状态时,就会发生这种情况。随着模型不断学习,其偏差会减小,但在过拟合状态下,其方差可能会增加。拟合模型的目标是在欠拟合和过拟合之间找到最佳位置,以便确定主导趋势,并将其广泛应用于新数据集。
Sora (OpenAI)
Video generation models as world simulators
https://openai.com/research/video-generation-models-as-world-simulators
We explore large-scale training of generative models on video data. Specifically, we train text-conditional diffusion models jointly on videos and images of variable durations, resolutions and aspect ratios. We leverage a transformer architecture that operates on spacetime patches of video and image latent codes. Our largest model, Sora, is capable of generating a minute of high fidelity video. Our results suggest that scaling video generation models is a promising path towards building general purpose simulators of the physical world.
这是一项关于大规模生成模型在视频数据上训练的研究。具体来说,作者在不同持续时间、分辨率和宽高比的视频和图像上,共同训练了基于文本条件的扩散模型。在这个研究中,作者使用了一种基于Transformer架构的方法,该方法在视频和图像的潜在编码的时空块上进行操作。作者提出的最大模型,名为Sora,能够生成高保真度的长达一分钟的视频。
这项研究的结果表明,扩大视频生成模型的规模是一条有前景的道路,有望构建通用的物理世界模拟器。这意味着,通过继续发展和扩大这种方法,我们可能会开发出能够以更高质量和更广泛的应用来生成和模拟视频的模型,从而为各种任务提供更强大的工具。