CPP Lab
- Prepare
- 编译器
- Data Struct
- C++11
- std::numeric_limits
- In-class initialization
- auto
- move
- Fixed width integer types
- enum class
- final specifier
- lambda
- std::hash
- std::function
- std::thread
- thread-local storage (线程本地存储)
- inline namespace
- std::vector<T,Allocator>::shrink_to_fit
- std::map<Key,T,Compare,Allocator>::emplace
- std::enable_shared_from_this
- std::this_thread::sleep_for
- std::mem_fn
- std::uniform_int_distribution
- std::bind
- override specifier (覆盖)
- std::abort
- std::is_class
- decltype specifier
- std::declval
- std::is_convertible
- std::is_union
- std::next
- std::distance
- std::has_virtual_destructor
- std::align
- std::priority_queue (heap)
- std::tie
- std::is_integral
- std::is_floating_point
- std::remove / std::remove_if
- std::enable_if
- std::atomic (代替 volatile)
- std::is_base_of
- std::begin / std::end
- std::sort
- std::extent
- std::error_code
- C++14
- C++17
- C++20
- C++23
- Algorithm
- Others
- Alignment and Bit Fields
- offsetof (macro)
- aligned_alloc
- operator«
- Unsigned overflow
- gethostbyname
- What is time_t ultimately a typedef to?
- Copy elision
- Zero initialization
- Argument-dependent lookup (ADL)
- Difference between auto and auto* when storing a pointer
- What’s the difference between constexpr and const?
- Color print
- Printf alignment
- _attribute__ ((format (printf, 2, 3)))
- attribute((deprecated))
- 空值类型转换
- 禁止函数内敛
- 多继承的指针偏移
- delete-non-virtual-dtor warning
- Static Members of a C++ Class
- inline
- 数组传参
- placement new
- Why doesn’t ANSI C have namespaces?
- 指向 const 的指针 / const 指针
- C++’s extern-“C” functionality to languages other than C
- AlignUpTo8 (参考 protobuf/arena_impl.h)
- Variable-length array (C99)
- gcc throwing error relocation truncated to fit: R_X86_64_32 against `.bss’
- push_back vs emplace_back
- Default arguments
- What is the difference between new/delete and malloc/free?
- array 初始化性能差异
- operator overloading
- When is it necessary to use the flag -stdlib=libstdc++?
- Use new operator to initialise an array
- 空指针类型转换,执行函数
- C++ 异常
- 开发框架
- basic_string 相关
- abi Namespace Reference
- Refer
- TODO
- Refer
Prepare
- 编译器对标准的支持情况:https://en.cppreference.com/w/cpp/compiler_support
- C++ Standards Support in GCC
- 模版实例化工具:https://cppinsights.io/
- 编译运行工具:https://wandbox.org/
查看当前环境C++版本:
$ ls -l /lib64/libstdc++.so.6
lrwxrwxrwx 1 root root 19 Aug 18 2020 /lib64/libstdc++.so.6 -> libstdc++.so.6.0.25
$ rpm -qf /lib64/libstdc++.so.6
libstdc++-8.3.1-5.el8.0.2.x86_64
编译器
How to printf uint64_t?
I wrote a very simple test code of printf uint64_t:
#include <inttypes.h>
#include <stdio.h>
int main()
{
uint64_t ui64 = 90;
printf("test uint64_t : %" PRIu64 "\n", ui64);
return 0;
}
I use ubuntu 11.10 (64 bit) and gcc version 4.6.1 to compile it, but failed:
main.cpp: In function ‘int main()’:
main.cpp:9:30: error: expected ‘)’ before ‘PRIu64’
main.cpp:9:47: warning: spurious trailing ‘%’ in format [-Wformat]
Answers:
The ISO C99 standard specifies that these macros must only be defined if explicitly requested.
#define __STDC_FORMAT_MACROS
#include <inttypes.h>
... now PRIu64 will work
Hm, just including the header should suffice. The __STDC_FORMAT_MACROS macro is only required for inclusion in C++.
Data Struct
std::forward_list
std::forward_list is a container that supports fast insertion and removal of elements from anywhere in the container. Fast random access is not supported. It is implemented as a singly-linked list (单向链表). Compared to std::list this container provides more space efficient storage when bidirectional iteration is not needed.
- https://en.cppreference.com/w/cpp/container/forward_list
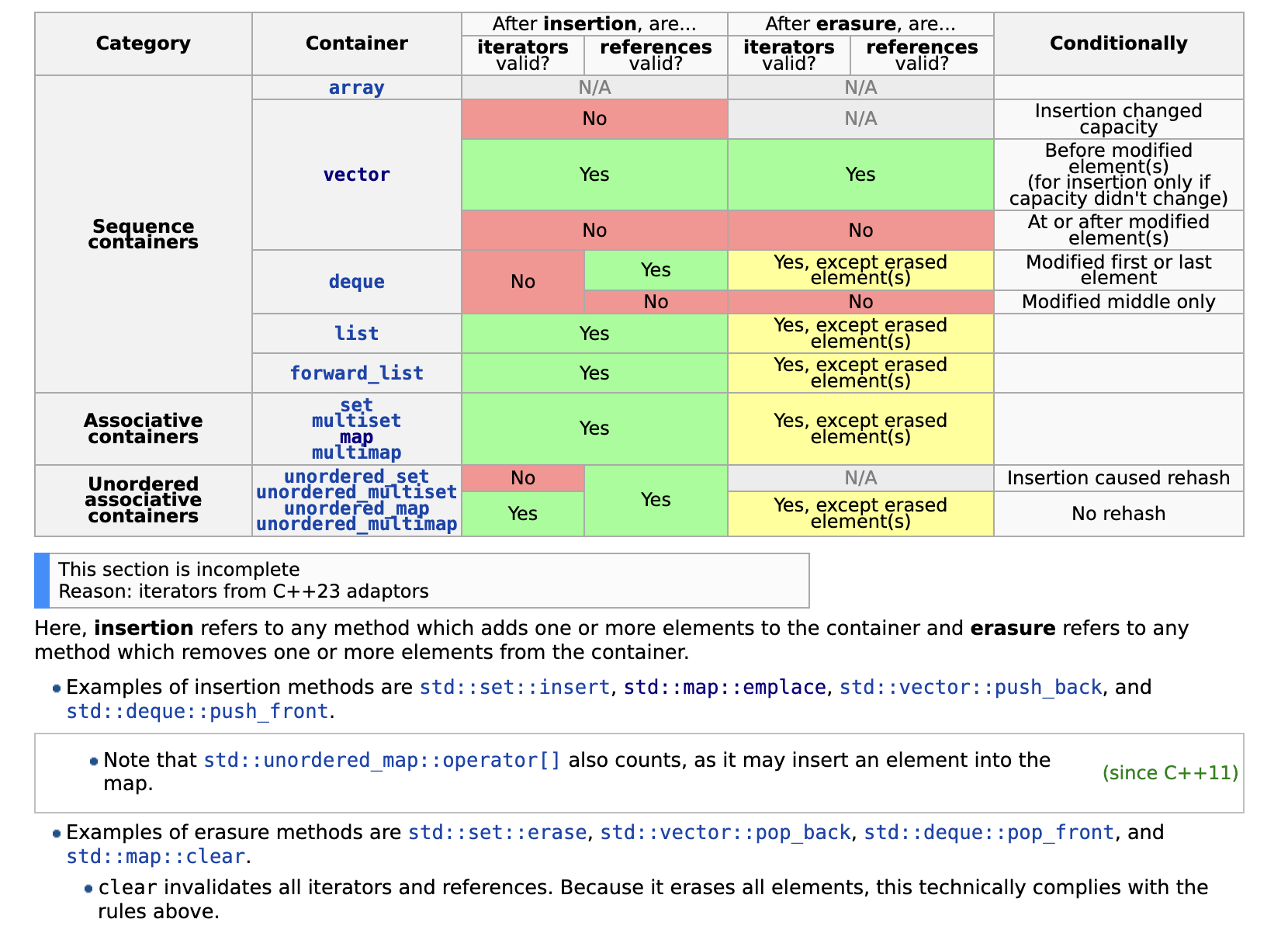
Iterator invalidation
https://en.cppreference.com/w/cpp/container
Read-only methods never invalidate iterators or references. Methods which modify the contents of a container may invalidate iterators and/or references, as summarized in this table.
#include <iostream>
#include <map>
int main() {
std::map<int, int> m = { {1,1},{2,2},{3,3},{4,4,},{6,6} };
auto iter1 = m.find(1);
auto iter3 = m.find(3);
auto iter6 = m.find(6);
m[5] = 5;
auto iter2 = m.find(2);
{
std::cout << "find 2 to delete it\n";
m.erase(iter2);
}
std::cout << iter1->first << "," << iter1->second << std::endl;
std::cout << iter3->first << "," << iter3->second << std::endl;
std::cout << iter6->first << "," << iter6->second << std::endl;
}
std::map (自定义 Key 比较)
当节点键大于等于所要查找或插入的键时,返回 0 (false),反之为 1 (true),这是由内部源代码所决定的。
std::map is a sorted associative container that contains key-value pairs with unique keys. Keys are sorted by using the comparison function Compare. Search, removal, and insertion operations have logarithmic complexity. Maps are usually implemented as Red–black trees.
Everywhere the standard library uses the Compare requirements, uniqueness is determined by using the equivalence relation. In imprecise terms, two objects a and b are considered equivalent (not unique) if neither compares less than the other: !comp(a, b) && !comp(b, a).
关于 C++ STL 中比较函数的要求和容器中元素唯一性的说明。
在 C++ STL 中,比较函数是用于比较容器中元素大小关系的函数。比较函数需要满足一定的要求,即它必须是一个严格弱序关系(strict weak ordering),也就是说,它必须满足以下三个条件:
- 反自反性(irreflexivity):对于任意元素 x,comp(x, x) 必须返回 false。
- 反对称性(antisymmetry):对于任意元素 x 和 y,如果 comp(x, y) 返回 true,则 comp(y, x) 必须返回 false。
- 传递性(transitivity):对于任意元素 x、y 和 z,如果 comp(x, y) 返回 true,comp(y, z) 返回 true,则 comp(x, z) 必须返回 true。
在使用等价关系判断元素唯一性时,两个元素 a 和 b 被认为是等价的(不唯一),当且仅当它们满足以下条件:!comp(a, b) && !comp(b, a)。也就是说,如果 a 和 b 之间不存在大小关系,它们就被认为是等价的,不唯一。
- https://en.cppreference.com/w/cpp/container/map
- https://en.cppreference.com/w/cpp/named_req/Compare
- STL中改变map的默认比较方式
#include <iostream>
#include <map>
struct S
{
S(int i, int j) : a(i), b(j) {}
int a;
int b;
// ok, use operator< to sort
bool operator<(const S& rhs) const
{
if (a < rhs.a)
{
return true;
}
else if (a == rhs.a)
{
if (b < rhs.b)
{
return true;
}
return false;
}
else
{
return false;
}
}
};
// ok, use operator< to sort
bool operator<(const S& lhs, const S& rhs)
{
if (lhs.a < rhs.a)
{
return true;
}
else if (lhs.a == rhs.a)
{
if (lhs.b < rhs.b)
{
return true;
}
return false;
}
else
{
return false;
}
}
// ok
struct SCompare
{
bool operator()(const S& lhs, const S& rhs) const
{
if (lhs.a < rhs.a)
{
return true;
}
else if (lhs.a == rhs.a)
{
if (lhs.b < rhs.b)
{
return true;
}
return false;
}
else
{
return false;
}
}
};
// ok
namespace std
{
template<>
struct less<S>
{
bool operator()(const S& lhs, const S& rhs) const
{
if (lhs.a < rhs.a)
{
return true;
}
else if (lhs.a == rhs.a)
{
if (lhs.b < rhs.b)
{
return true;
}
return false;
}
else
{
return false;
}
}
};
}
//using Map = std::map<S, std::string, SCompare>;
using Map = std::map<S, std::string>;
int main()
{
Map m;
auto f1 = [](bool b) { b ? std::cout << "true\n" : std::cout << "false\n"; };
f1(m.emplace(std::make_pair(S(1, 1), "a")).second);
f1(m.emplace(std::make_pair(S(1, 2), "b")).second);
f1(m.emplace(std::make_pair(S(2, 1), "c")).second);
auto f2 = [&m]()
{
for (auto& n : m)
{
std::cout << n.second << " ";
}
};
f2();
// find 操作会对每个元素交换位置比较两次,两次比较结果都是 false 则认为相等
// an expression-equivalent to !comp(a, b) && !comp(b, a)
S k(1, 2);
auto iter = m.find(k);
if (iter != m.end()) {
printf("find\n");
} else {
printf("no find\n");
}
return 0;
}
/*
true
true
true
a b c
find
*/
C++11
std::numeric_limits
template< class T > class numeric_limits;
The std::numeric_limits class template provides a standardized way to query various properties of arithmetic types (e.g. the largest possible value for type int is std::numeric_limits<int>::max()).
This information is provided via specializations of the std::numeric_limits template. The standard library makes available specializations for all arithmetic types (only lists the specializations for cv-unqualified arithmetic types)
#include <iostream>
#include <limits>
int main()
{
std::cout << "type\t│ lowest()\t│ min()\t\t│ max()\n"
<< "bool\t│ "
<< std::numeric_limits<bool>::lowest() << "\t\t│ "
<< std::numeric_limits<bool>::min() << "\t\t│ "
<< std::numeric_limits<bool>::max() << '\n'
<< "uchar\t│ "
<< +std::numeric_limits<unsigned char>::lowest() << "\t\t│ "
<< +std::numeric_limits<unsigned char>::min() << "\t\t│ "
<< +std::numeric_limits<unsigned char>::max() << '\n'
<< "int\t│ "
<< std::numeric_limits<int>::lowest() << "\t│ "
<< std::numeric_limits<int>::min() << "\t│ "
<< std::numeric_limits<int>::max() << '\n'
<< "float\t│ "
<< std::numeric_limits<float>::lowest() << "\t│ "
<< std::numeric_limits<float>::min() << "\t│ "
<< std::numeric_limits<float>::max() << '\n'
<< "double\t│ "
<< std::numeric_limits<double>::lowest() << "\t│ "
<< std::numeric_limits<double>::min() << "\t│ "
<< std::numeric_limits<double>::max() << '\n';
}
Possible output:
type │ lowest() │ min() │ max()
bool │ 0 │ 0 │ 1
uchar │ 0 │ 0 │ 255
int │ -2147483648 │ -2147483648 │ 2147483647
float │ -3.40282e+38 │ 1.17549e-38 │ 3.40282e+38
double │ -1.79769e+308 │ 2.22507e-308 │ 1.79769e+308
https://en.cppreference.com/w/cpp/types/numeric_limits
In-class initialization
If you use a constructor that doesn’t specify any other value, then the 1234 would be used to initialize a, but if you use a constructor that specifies some other value, then the 1234 is basically ignored.
#include <iostream>
class X {
int a = 1234;
public:
X() = default;
X(int z) : a(z) {}
friend std::ostream &operator<<(std::ostream &os, X const &x) {
return os << x.a;
}
};
int main() {
X x;
X y{5678};
std::cout << x << "\n" << y;
return 0;
}
/*
1234
5678
*/
- C++11 allows in-class initialization of non-static and non-const members. What changed?
- How do I define an in-class constant?
auto
auto没有指定&时,会推导为值拷贝。例如,auto s : vec
#include <cstdio>
#include <string>
#include <vector>
int main()
{
std::vector<std::string> vec = {"1", "2"};
for (auto s : vec) {
printf("%s\n", s.c_str());
}
}
使用https://cppinsights.io/翻译可以得到:
#include <cstdio>
#include <string>
#include <vector>
int main()
{
std::vector<std::string> vec = std::vector<std::basic_string<char>, std::allocator<std::basic_string<char> > >{std::initializer_list<std::basic_string<char> >{std::basic_string<char>("1", std::allocator<char>()), std::basic_string<char>("2", std::allocator<char>())}, std::allocator<std::basic_string<char> >()};
{
std::vector<std::basic_string<char>, std::allocator<std::basic_string<char> > > & __range1 = vec;
__gnu_cxx::__normal_iterator<std::basic_string<char> *, std::vector<std::basic_string<char>, std::allocator<std::basic_string<char> > > > __begin1 = __range1.begin();
__gnu_cxx::__normal_iterator<std::basic_string<char> *, std::vector<std::basic_string<char>, std::allocator<std::basic_string<char> > > > __end1 = __range1.end();
for(; __gnu_cxx::operator!=(__begin1, __end1); __begin1.operator++()) {
std::basic_string<char> s = std::basic_string<char>(__begin1.operator*()); // 存在值拷贝
printf("%s\n", s.c_str());
}
}
}
若将auto s : vec改为auto& s : vec,则会变为引用:
std::basic_string<char> & s = __begin1.operator*();
move
例子:
#include <functional>
#include <iostream>
class A
{
public:
A() { printf("A::A()\n"); }
~A() { printf("A::~A()\n"); }
A(A&&) { printf("A::A(&&)\n"); } // move ctor
A& operator=(A&& a) // move assgin
{
printf("A::operator=A(&&)\n");
if (this != &a)
{
x = a.x;
}
return *this;
}
void print() { printf("A::print x(%d)\n", x); }
int x = 0;
};
A a2;
void f(A&& a)
{
a2 = std::move(a);
}
int main()
{
A a;
a.x = 1;
f(std::move(a));
a2.print();
}
/*
A::A()
A::A()
A::operator=A(&&)
A::print x(1)
A::~A()
A::~A()
*/
注意:
- 使用
gcc 4.9.4编译,被移动的右值并没有被清空,而高版本的编译器符合预期。可见测试代码
#include <string>
#include <iostream>
#include <utility>
struct A
{
std::string s;
A() : s("test") { }
A(const A& o) : s(o.s) { std::cout << "move failed!\n"; }
A(A&& o) : s(std::move(o.s)) { }
A& operator=(const A& other)
{
s = other.s;
std::cout << "copy assigned\n";
return *this;
}
A& operator=(A&& other)
{
s = std::move(other.s);
std::cout << "move assigned\n";
return *this;
}
};
A f(A a) { return a; }
struct B : A
{
std::string s2;
int n;
// implicit move assignment operator B& B::operator=(B&&)
// calls A's move assignment operator
// calls s2's move assignment operator
// and makes a bitwise copy of n
};
struct C : B
{
~C() { } // destructor prevents implicit move assignment
};
struct D : B
{
D() { }
~D() { } // destructor would prevent implicit move assignment
D& operator=(D&&) = default; // force a move assignment anyway
};
int main()
{
A a1, a2;
std::cout << "Trying to move-assign A from rvalue temporary\n";
a1 = f(A()); // move-assignment from rvalue temporary
std::cout << "Trying to move-assign A from xvalue\n";
a2 = std::move(a1); // move-assignment from xvalue
std::cout << "Trying to move-assign B\n";
B b1, b2;
std::cout << "Before move, b1.s = \"" << b1.s << "\"\n";
b2 = std::move(b1); // calls implicit move assignment
std::cout << "After move, b1.s = \"" << b1.s << "\"\n";
std::cout << "Trying to move-assign C\n";
C c1, c2;
c2 = std::move(c1); // calls the copy assignment operator
std::cout << "Trying to move-assign D\n";
D d1, d2;
d2 = std::move(d1);
}
refer:
Fixed width integer types
- int8_t/int16_t/int32_t/int64_t
signed integer type with width of exactly 8, 16, 32 and 64 bits respectively with no padding bits and using 2’s complement for negative values
- uint8_t/uint16_t/uint32_t/uint64_t
unsigned integer type with width of exactly 8, 16, 32 and 64 bits respectively
- intptr_t
signed integer type capable of holding a pointer
- uintptr_t
unsigned integer type capable of holding a pointer
https://en.cppreference.com/w/cpp/types/integer
enum class
Why is enum class preferred over plain enum? enum classes should be preferred because they cause fewer surprises that could potentially lead to bugs.
枚举(包括作用域枚举和非作用域枚举)的命名应当和常量保持一致而不是宏。即使用kEnumName形式命名而不是ENUM_NAME形式。对于非作用域枚举,还应当将枚举类型作为枚举名的前缀,以减少潜在的命名冲突。如果使用 C++11 之后的编译器开发,优先考虑使用 enum class,它可以提供更强的类型检测,并减少潜在的命名冲突。
enum class UrlTableErrors {
kOk = 0,
kOutOfMemory,
kMalformedInput,
};
enum UrlParseError{
kUrlParseErrorOk = 0,
kUrlParseErrorInvalidCharacter,
kUrlParseErrorOutOfMemory,
};
Forcing enum to be of unsigned long type
Is it possible to force the underlying type of an enumeration to be unsigned long type?
In C++11 and higher, you can explicitly mention what type you want:
enum MyEnumeration: unsigned long {
/* ... values go here ... */
};
This will allow you to explicitly control the underlying type.
In C++03, there is no way to force an enumerated type to have any particular underlying implementation. Quoth the C++03 spec, §7.2/5:
The underlying type of an enumeration is an integral type that can represent all the enumerator values defined in the enumeration. It is implementation-defined which integral type is used as the underlying type for an enumeration except that the underlying type shall not be larger than int unless the value of an enumerator cannot fit in an int or unsigned int. If the enumerator-list is empty, the underlying type is as if the enumeration had a single enumerator with value 0. The value of sizeof() applied to an enumeration type, an object of enumeration type, or an enumerator, is the value of sizeof() applied to the underlying type.
This is a pretty lax condition and says that not only can you not necessarily know the type, but because it’s implementation-defined there’s no guarantee that it even corresponds to one of the primitive types at all.
final specifier
Specifies that a virtual function cannot be overridden in a derived class or that a class cannot be derived from.
struct Base
{
virtual void foo();
};
struct A : Base
{
void foo() final; // Base::foo is overridden and A::foo is the final override
void bar() final; // Error: bar cannot be final as it is non-virtual
};
struct B final : A // struct B is final
{
void foo() override; // Error: foo cannot be overridden as it is final in A
};
struct C : B {}; // Error: B is final
Possible output:
main.cpp:9:10: error: 'void A::bar()' marked 'final', but is not virtual
9 | void bar() final; // Error: bar cannot be final as it is non-virtual
| ^~~
main.cpp:14:10: error: virtual function 'virtual void B::foo()' overriding final function
14 | void foo() override; // Error: foo cannot be overridden as it is final in A
| ^~~
main.cpp:8:10: note: overridden function is 'virtual void A::foo()'
8 | void foo() final; // Base::foo is overridden and A::foo is the final override
| ^~~
main.cpp:17:8: error: cannot derive from 'final' base 'B' in derived type 'C'
17 | struct C : B // Error: B is final
|
- https://en.cppreference.com/w/cpp/language/final
lambda
[captures] (params) specifiers exception -> ret { body }
- 作用域
- 捕获列表中的变量存在于两个作用域:lambda 表达式定义的函数作用域(用于捕获变量),以及 lambda 表达式函数体的作用域(用于使用变量)
- 捕获变量必须是一个自动存储类型(即,非静态的局部变量)
- 捕获值和捕获引用
- 捕获的变量默认为常量(即,捕获值),或者说 lambda 是一个常量函数(类似于常量成员函数)
- 捕获引用,可以在 lambda 的函数体中修改对应捕获的变量
- 使用 mutable 说明符移除 lambda 表达式的常量性。如果存在说明符,则形参列表不能省略
- 捕获值的变量在 lambda 表达式定义的时候就已经固定下来了,而捕获引用的变量以调用 lambda 表达式前的为准
- 特殊的捕获方法
[this]捕获this指针,可以使用this类型的成员变量和函数[=]捕获 lambda 表达式定义作用域的全部变量的值,包括this[&]捕获 lambda 表达式定义作用域的全部变量的引用,包括this
注意:新的C++20标准,不再支持
[=]或[&]隐式捕获this指针了,而是提示用户显式添加this或者*this。
#include <iostream>
class A
{
public:
void print() {
std::cout << "A::print()\n";
}
void test() {
auto foo = [this] {
x = 5;
print();
};
foo();
}
private:
int x = 0;
};
int main()
{
int x = 5;
// 捕获值
auto foo = [x](int y)->int { return x * y; };
std::cout << foo(8) << std::endl; // 40
//auto foo2 = [x](int y)->int { ++x; return x * y; }; // error: increment of read-only variable 'x'
// 捕获引用
auto foo2 = [&x](int y)->int { ++x; return x * y; };
std::cout << foo2(8) << std::endl; // 48
// 使用 mutable 说明符移除 lambda 表达式的常量性
auto foo3 = [x](int y) mutable ->int { ++x; return x * y; };
std::cout << foo3(8) << std::endl; // 56
// 捕获 this
A a;
a.test();
}
lambda 表达式与仿函数(函数对象)的区别
- 使用 lambda 表达式,不需要去显式定义一个类,在快速实现功能上比较有优势 -> 让代码短小精悍且具有良好的可读性
- 使用函数对象,可以在初始化时有更丰富的操作,即,可以使用全局或静态局部变量,而非必须为局部自动变量 -> 灵活不受限制
lambda 表达式原理
lambda 表达式在编译期会有编译器自动生成一个闭包类,在运行时由这个闭包类产生一个对象,称它为闭包。在C++中,所谓的闭包可以简单地理解为一个匿名且可以包含定义时作用域上下文的函数对象。
#include <iostream>
int main()
{
int x = 5, y = 8;
auto foo = [=] { return x * y; };
int z = foo();
}
使用https://cppinsights.io/翻译一下,生成如下代码:
#include <iostream>
int main()
{
int x = 5;
int y = 8;
class __lambda_6_14
{
public:
inline /*constexpr */ int operator()() const
{
return x * y;
}
private:
int x;
int y;
public:
__lambda_6_14(int & _x, int & _y)
: x{_x}
, y{_y}
{}
};
__lambda_6_14 foo = __lambda_6_14{x, y};
int z = foo.operator()();
}
因此,从某种程度上说,lambda 表达式是C++11提供的一种语法糖,让代码编写更加轻松。
关于生命周期的错误用法
#include <iostream>
#include <functional>
class A
{
public:
A() { printf("A::A()\n"); }
~A() { printf("A::~A()\n"); }
A(A&&) { printf("A::A(&&)\n"); } // move ctor
int x = 0;
};
using Func = std::function<void()>;
int main()
{
Func f2;
{
A a1;
a1.x = 2;
Func f = [&a1](){ printf("a1.x: %d\n", a1.x); };
f2 = std::move(f);
}
f2(); // Oops! a1.x: 2, but this is error
}
对象a1通过引用的方式捕获,在调用f2()时,a1的生命周期已经结束。
验证程序:f2() 之所以输出正确,是因为编译器对堆栈没有复用,可以通过变量地址验证。
#include <iostream>
#include <functional>
class A
{
public:
A() { printf("A::A()\n"); }
~A() { printf("A::~A()\n"); }
A(A&&) { printf("A::A(&&)\n"); } // move ctor
void print() { printf("A::print x(%d)\n", x); }
int x = 0;
};
using Func = std::function<void()>;
int main()
{
Func f, f2;
{
A a1;
a1.x = 2;
f = [&a1](){ printf("&a1.x(%p) a1.x(%d)\n", &a1.x, a1.x); };
f2 = std::move(f);
a1.x = 3;
printf("&a1.x(%p)\n", &a1.x);
}
int b[1] = {0};
printf("&b(%p) b(%d)\n", b, b[0]);
f2();
}
/*
A::A()
&a1.x(0x7ffe0e1c3430)
A::~A()
&b(0x7ffe0e1c3440) b(0)
&a1.x(0x7ffe0e1c3430) a1.x(3)
*/
Move semantic with std::function
#include <functional>
#include <iostream>
//void f() {}
using Func = std::function<void()>;
Func f = [](){ printf("hello\n"); };
int main()
{
std::function<void()> h;
{
std::function<void()> g{f};
h = std::move(g);
std::cout << (g ? "not empty\n" : "empty\n"); // empty
}
h(); // hello
}
性能影响
In addition, C++ compilers optimize lambdas better than they do ordinary functions. (Page 213)
- Are lambdas inlined like functions in C++?
- Why can lambdas be better optimized by the compiler than plain functions?
在STL中使用 lambda 表达式
有了 lambda 表达式后,可以直接在STL算法函数的参数列表内实现辅助函数。
#include <iostream>
#include <vector>
#include <algorithm>
int main()
{
std::vector<int> x = {1, 2, 3, 4, 5};
std::cout << *std::find_if(x.cbegin(), x.cend(), [](int i){ return (i % 3) == 0; }) << std::endl; // 3
}
在 C++14 标准中,定义广义捕获。分为:
+ 简单捕获。例如,[identifier],[&identifier],[this]等
+ 初始化捕获。除了捕获 lambda 表达式定义上下文的变量,也可以捕获表达式结果,以及自定义捕获变量名
#include <iostream>
int main()
{
int x = 5;
// c++14 初始化捕获,自定义捕获变量 r
auto foo = [r = x + 1] { return r; };
std::cout << foo(); // 6
}
泛型 lambda 表达式 (C++14)
C++14标准让 lambda 表达式具备了模板函数的能力,称为泛型 lambda 表达式。虽然具备模板函数的能力,但是它的定义却用不到template关键字。
#include <iostream>
int main()
{
auto foo = [](auto a) { return a; };
int b = foo(3);
const char* c = foo("hello");
std::cout << b << " " << c << std::endl;// 3 hello
}
lambda 展开实现
#include <iostream>
#include <functional>
using Func = std::function<void(void)>;
void h(Func* pf)
{
(*pf)();
}
void g(Func&& f)
{
h(&f);
}
int main()
{
g( [](){ std::cout << "hello\n";} );
}
展开后:
#include <iostream>
#include <functional>
using Func = std::function<void(void)>;
void h(std::function<void()>* pf)
{
(*pf).operator()();
std::cout << "h()\n";
}
void g(std::function<void()>&& f)
{
h(&f);
std::cout << "g()\n";
}
class CLambda
{
public:
inline void operator()() const
{
std::operator<<(std::cout, "hello\n");
}
// ctor
CLambda()
{
std::cout << "CLambda()\n";
}
CLambda(const CLambda&)
{
std::cout << "CLambda(CLambda)\n";
}
CLambda& operator=(const CLambda&)
{
std::cout << "CLambda& operator=(const CLambda&) \n";
return *this;
}
CLambda(CLambda&&)
{
std::cout << "CLambda(CLambda&&)\n";
}
CLambda& operator=(CLambda&&)
{
std::cout << "CLambda& operator=(CLambda&&)\n";
return *this;
}
// dtor
~CLambda()
{
std::cout << "~CLambda()\n";
}
};
int main()
{
g(std::function<void()>(CLambda()));
}
输出:
CLambda()
CLambda(CLambda&&)
hello
h()
g()
~CLambda()
~CLambda()
示例
#include <iostream>
#include <ctime>
int main()
{
while (false) {
thread_local time_t tLastTime = 0;
time_t tNow = time(nullptr);
if (tLastTime + 1 <= tNow) {
tLastTime = tNow;
std::cout << "tick\n";
}
}
auto freq = [](int t) -> bool {
thread_local time_t tLastTime = 0;
time_t tNow = time(nullptr);
if (tLastTime + t <= tNow) {
tLastTime = tNow;
return true;
}
return false;
};
while (true) {
if (freq(1)) {
std::cout << "tick\n";
}
}
}
std::hash
// functional header
// for hash<class template> class
#include <functional>
#include <iostream>
#include <string>
int main()
{
// Get the string to get its hash value
std::string hashing = "Geeks";
// Instantiation of Object
std::hash<std::string> mystdhash;
// Using operator() to get hash value
std::cout << "String hash values: "
<< mystdhash(hashing)
<< std::endl;
int hashing2 = 12345;
std::hash<int> mystdhash2;
std::cout << "Int hash values: "
<< mystdhash2(hashing2)
<< std::endl;
}
/*
String hash values: 4457761756728957899
Int hash values: 12345
*/
https://en.cppreference.com/w/cpp/utility/hash
std::function
template< class R, class... Args >
class function<R(Args...)>
Class template std::function is a general-purpose polymorphic function wrapper. Instances of std::function can store, copy, and invoke any Callable target – functions, lambda expressions, bind expressions, or other function objects, as well as pointers to member functions and pointers to data members.
#include <functional>
#include <iostream>
struct Foo {
Foo(int num) : num_(num) {}
void print_add(int i) const { std::cout << num_+i << '\n'; }
int num_;
};
void print_num(int i)
{
std::cout << i << '\n';
}
struct PrintNum {
void operator()(int i) const
{
std::cout << i << '\n';
}
};
int main()
{
// store a free function
std::function<void(int)> f_display = print_num;
f_display(-9);
// store a lambda
std::function<void()> f_display_42 = []() { print_num(42); };
f_display_42();
// store the result of a call to std::bind
std::function<void()> f_display_31337 = std::bind(print_num, 31337);
f_display_31337();
// store a call to a member function
std::function<void(const Foo&, int)> f_add_display = &Foo::print_add;
const Foo foo(314159);
f_add_display(foo, 1);
// store a call to a member function and object
using std::placeholders::_1;
std::function<void(int)> f_add_display2= std::bind( &Foo::print_add, foo, _1 );
f_add_display2(2);
// store a call to a member function and object ptr
std::function<void(int)> f_add_display3= std::bind( &Foo::print_add, &foo, _1 );
f_add_display3(3);
// store a call to a function object
std::function<void(int)> f_display_obj = PrintNum();
f_display_obj(18);
}
/*
-9
42
31337
314160
314161
314162
18
*/
- https://www.enseignement.polytechnique.fr/informatique/INF478/docs/Cpp/en/cpp/utility/functional/function.html
std::thread
#include <iostream> // std::cout
#include <thread> // std::thread
void foo()
{
std::cout << "foo()\n";
}
void bar(int x)
{
std::cout << "bar(" << x << ")\n";
}
int main()
{
std::thread first (foo); // spawn new thread that calls foo()
std::thread second (bar, 0); // spawn new thread that calls bar(0)
std::cout << "main, foo and bar now execute concurrently...\n";
// synchronize threads:
first.join(); // pauses until first finishes
second.join(); // pauses until second finishes
std::cout << "foo and bar completed.\n";
return 0;
}
/*
main, foo and bar now execute concurrently...
foo()
bar(0)
foo and bar completed.
*/
- https://www.cplusplus.com/reference/thread/thread/
thread-local storage (线程本地存储)
Thread-local storage (TLS) provides a mechanism allocating distinct objects for different threads. It is the usual implementation for GCC extension
__thread, C11_Thread_local, and C++11thread_local, which allow the use of the declared name to refer to the entity associated with the current thread.
An example usage of thread-local storage is POSIX errno:
Each thread has its own thread ID, scheduling priority and policy, errno value, floating point environment, thread-specific key/value bindings, and the required system resources to support a flow of control.
Different threads have different errno copies. errno is typically defined as a function which returns a thread-local variable.
Thread-Local Storage
Thread-local storage (TLS) is a mechanism by which variables are allocated such that there is one instance of the variable per extant thread. The run-time model GCC uses to implement this originates in the IA-64 processor-specific ABI, but has since been migrated to other processors as well. It requires significant support from the linker (ld), dynamic linker (ld.so), and system libraries (libc.so and libpthread.so), so it is not available everywhere.
At the user level, the extension is visible with a new storage class keyword: __thread. For example:
__thread int i;
extern __thread struct state s;
static __thread char *p;
The __thread specifier may be used alone, with the extern or static specifiers, but with no other storage class specifier. When used with extern or static, __thread must appear immediately after the other storage class specifier.
thread_local (C++11)
The thread_local keyword is only allowed for objects declared at namespace scope, objects declared at block scope, and static data members. It indicates that the object has thread storage duration. It can be combined with static or extern to specify internal or external linkage (except for static data members which always have external linkage), respectively, but that additional static doesn’t affect the storage duration.
#include <iostream>
class foo
{
public:
static thread_local int a;
};
thread_local int foo::a = 1;
int main()
{
std::cout << foo::a; // 1
}
#include <iostream>
#include <cstdint>
#include <unistd.h>
#define N 2
__thread int myVar;
int *commonVar;
void *th(void *arg)
{
int myid = *((int *)arg);
myVar = myid;
printf("thread %d set myVar=%d, &myVar=%p\n", myid, myVar, &myVar);
sleep(1);
printf("thread %d now has myVar=%d\n", myid, myVar);
sleep(1 + myid);
printf("thread %d sees this value at *commonVar=%d, commonVar=%p\n", myid, *commonVar, commonVar);
commonVar = &myVar;
printf("thread %d sets commonVar pointer to his myVar and now *commonVar=%d, commonVar=%p\n", myid, *commonVar, commonVar);
return 0;
}
int main()
{
int a = 123;
pthread_t t[N];
int arg[N];
commonVar = &a;
printf("size of pointer: %lu bits\n", 8UL * sizeof(&a));
for (int i = 0; i < N; i++)
{
arg[i] = i;
pthread_create(&t[i], 0, th, arg + i);
}
for (int i = 0; i < N; i++)
pthread_join(t[i], 0);
printf("all done\n");
}
/*
size of pointer: 64 bits
thread 0 set myVar=0, &myVar=0x7f8fea8556fc
thread 1 set myVar=1, &myVar=0x7f8fea0546fc
thread 0 now has myVar=0
thread 1 now has myVar=1
thread 0 sees this value at *commonVar=123, commonVar=0x7fff95aa1a3c
thread 0 sets commonVar pointer to his myVar and now *commonVar=0, commonVar=0x7f8fea8556fc
thread 1 sees this value at *commonVar=0, commonVar=0x7f8fea8556fc
thread 1 sets commonVar pointer to his myVar and now *commonVar=1, commonVar=0x7f8fea0546fc
all done
*/
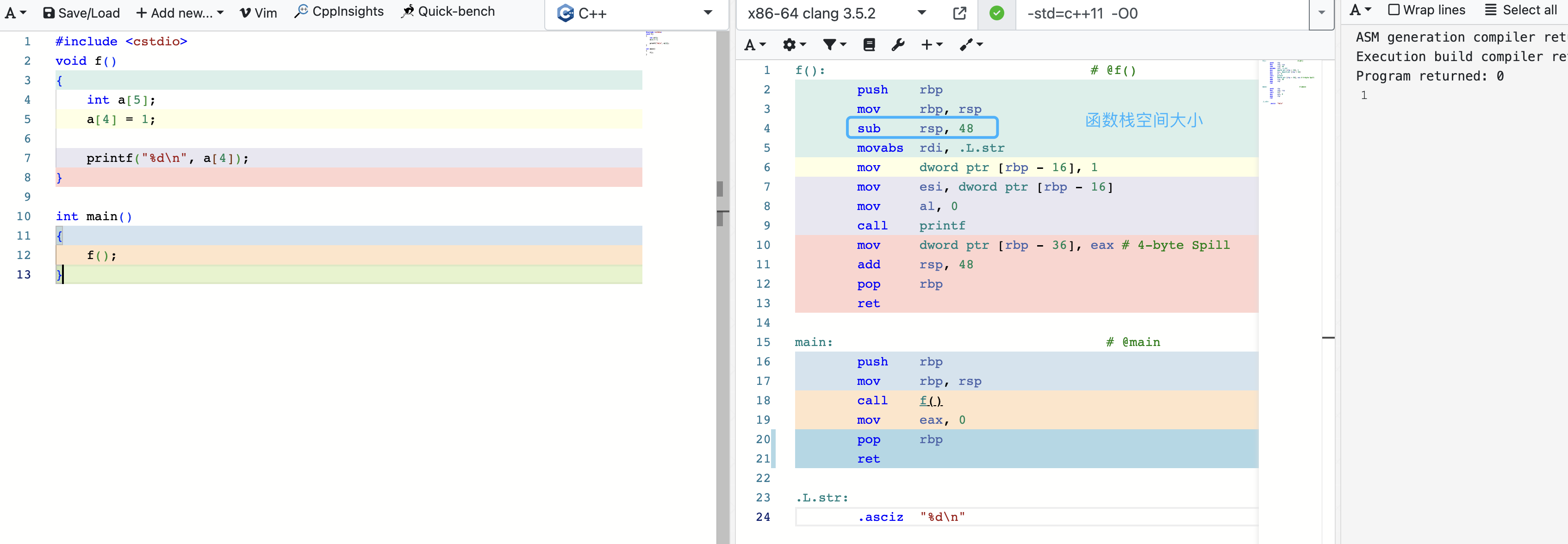
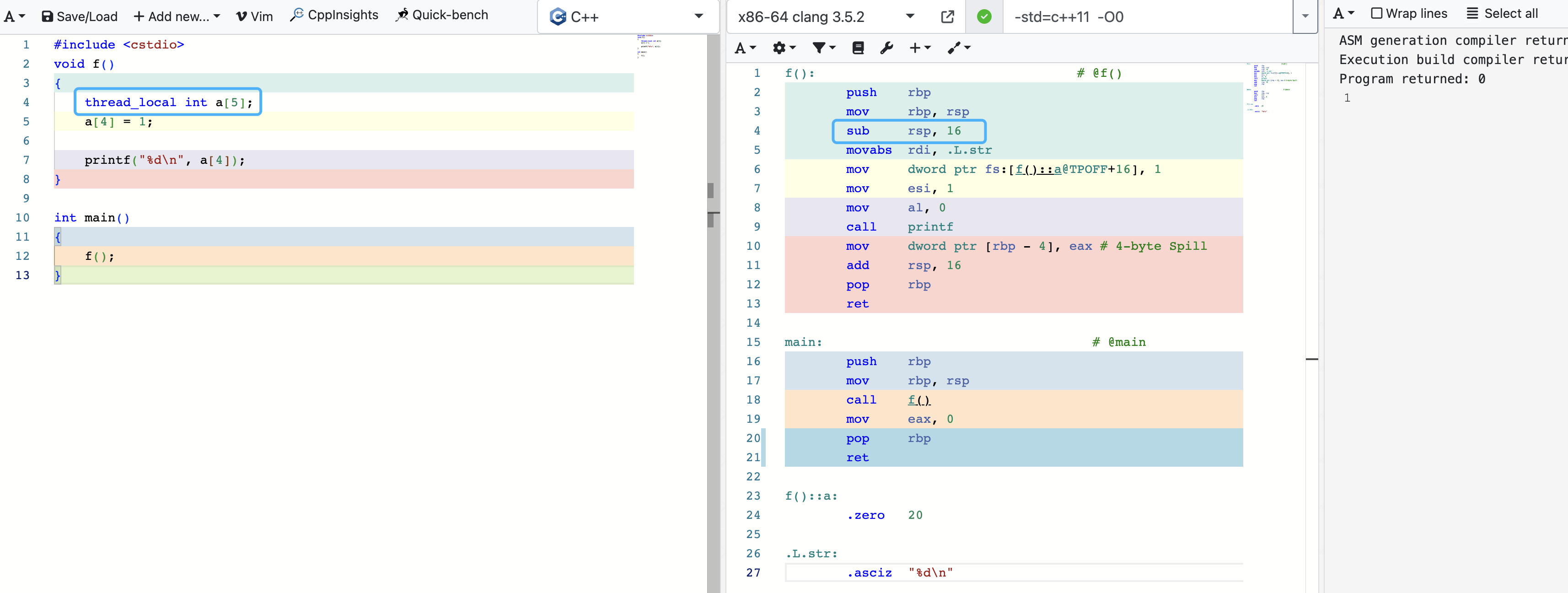
使用 thread_local 减少栈空间
#include <cstdio>
void f()
{
int a[5];
a[4] = 1;
printf("%d\n", a[4]);
}
int main()
{
f();
}
将栈变量改为 thread_local 后:
More
- All about thread-local storage
- Storage class specifiers
- Can you use thread local variables inside a class or structure
- Are C++11 thread_local variables automatically static?
- What does the thread_local mean in C++11?
- GDB support for thread-local storage
inline namespace
#include <iostream>
using namespace std;
namespace xyz {
inline namespace v2 {
void foo() { cout << "xyz::v2::foo()" << endl; }
} // namespace v2
namespace v1 {
void foo() { cout << "xyz::v1::foo()" << endl; }
} // namespace v1
} // namespace xyz
int main() {
xyz::foo(); // 直接调用 xyz::v2::foo(),而不用 using
}
std::vector<T,Allocator>::shrink_to_fit
Requests the removal of unused capacity. It is a non-binding request to reduce capacity() to size(). It depends on the implementation whether the request is fulfilled. If reallocation occurs, all iterators, including the past the end iterator, and all references to the elements are invalidated. If no reallocation takes place, no iterators or references are invalidated.
#include <iostream>
#include <vector>
int main()
{
std::vector<int> v;
std::cout << "Default-constructed capacity is " << v.capacity() << '\n';
v.resize(100);
std::cout << "Capacity of a 100-element vector is " << v.capacity() << '\n';
v.resize(50);
std::cout << "Capacity after resize(50) is " << v.capacity() << '\n';
v.shrink_to_fit();
std::cout << "Capacity after shrink_to_fit() is " << v.capacity() << '\n';
v.clear(); // Erases all elements from the container. After this call, size() returns zero. But capacity() is not !
std::cout << "Capacity after clear() is " << v.capacity() << '\n';
v.shrink_to_fit();
std::cout << "Capacity after shrink_to_fit() is " << v.capacity() << '\n';
for (int i = 1000; i < 1300; ++i)
v.push_back(i);
std::cout << "Capacity after adding 300 elements is " << v.capacity() << '\n';
v.shrink_to_fit();
std::cout << "Capacity after shrink_to_fit() is " << v.capacity() << '\n';
}
/*
Default-constructed capacity is 0
Capacity of a 100-element vector is 100
Capacity after resize(50) is 100
Capacity after shrink_to_fit() is 50
Capacity after clear() is 50
Capacity after shrink_to_fit() is 0
Capacity after adding 300 elements is 512
Capacity after shrink_to_fit() is 300
*/
- https://en.cppreference.com/w/cpp/container/vector/shrink_to_fit
std::map<Key,T,Compare,Allocator>::emplace
template< class... Args >
std::pair<iterator,bool> emplace( Args&&... args );
Inserts a new element into the container constructed in-place with the given args if there is no element with the key in the container.
#include <iostream>
#include <utility>
#include <string>
#include <map>
int main()
{
std::map<std::string, std::string> m;
// uses pair's move constructor
m.emplace(std::make_pair(std::string("a"), std::string("a")));
// uses pair's converting move constructor
m.emplace(std::make_pair("b", "abcd"));
// uses pair's template constructor
m.emplace("d", "ddd");
// uses pair's piecewise constructor
m.emplace(std::piecewise_construct,
std::forward_as_tuple("c"),
std::forward_as_tuple(10, 'c'));
// as of C++17, m.try_emplace("c", 10, 'c'); can be used
for (const auto &p : m) {
std::cout << p.first << " => " << p.second << '\n';
}
}
/*
a => a
b => abcd
c => cccccccccc
d => ddd
*/
std::enable_shared_from_this
std::enable_shared_from_thisallows an objecttthat is currently managed by astd::shared_ptrnamedptto safely generate additionalstd::shared_ptrinstances pt1, pt2, … that all share ownership oftwithpt.- Publicly inheriting from
std::enable_shared_from_this<T>provides the type T with a member functionshared_from_this. If an object t of typeTis managed by astd::shared_ptr<T>namedpt, then callingT::shared_from_thiswill return a newstd::shared_ptr<T>that shares ownership of t withpt.
#include <memory>
#include <iostream>
struct Good: public std::enable_shared_from_this<Good> // note: public inheritance
{
std::shared_ptr<Good> getptr() {
return shared_from_this();
}
};
struct Bad
{
std::shared_ptr<Bad> getptr() {
return std::shared_ptr<Bad>(this);
}
~Bad() { std::cout << "Bad::~Bad() called\n"; }
};
int main()
{
// Good: the two shared_ptr's share the same object
std::shared_ptr<Good> gp1 = std::make_shared<Good>();
std::shared_ptr<Good> gp2 = gp1->getptr();
std::cout << "gp2.use_count() = " << gp2.use_count() << '\n';
// Bad: shared_from_this is called without having std::shared_ptr owning the caller
try {
Good not_so_good;
std::shared_ptr<Good> gp1 = not_so_good.getptr();
} catch(std::bad_weak_ptr& e) {
// undefined behavior (until C++17) and std::bad_weak_ptr thrown (since C++17)
std::cout << e.what() << '\n';
}
// Bad, each shared_ptr thinks it's the only owner of the object
std::shared_ptr<Bad> bp1 = std::make_shared<Bad>();
std::shared_ptr<Bad> bp2 = bp1->getptr();
std::cout << "bp2.use_count() = " << bp2.use_count() << '\n';
} // UB: double-delete of Bad
/*
gp2.use_count() = 2
bad_weak_ptr
bp2.use_count() = 1
Bad::~Bad() called
Bad::~Bad() called
*** glibc detected *** ./test: double free or corruption
*/
https://en.cppreference.com/w/cpp/memory/enable_shared_from_this
std::this_thread::sleep_for
#include <iostream>
#include <chrono>
#include <thread>
int main()
{
std::cout << "Hello waiter\n" << std::flush;
auto start = std::chrono::high_resolution_clock::now();
//using namespace std::chrono_literals;
//std::this_thread::sleep_for(2000ms); // 2000ms for C++14
std::chrono::nanoseconds ns(500 * 1000 * 1000);
std::this_thread::sleep_for(ns);
auto end = std::chrono::high_resolution_clock::now();
std::chrono::duration<double, std::milli> elapsed = end-start;
std::cout << "Waited " << elapsed.count() << " ms\n";
}
- https://en.cppreference.com/w/cpp/thread/sleep_for
- https://en.cppreference.com/w/cpp/chrono/duration
std::mem_fn
- Function template
std::mem_fngenerates wrapper objects for pointers to members, which can store, copy, and invoke a pointer to member. Both references and pointers (including smart pointers) to an object can be used when invoking astd::mem_fn.
#include <functional>
#include <iostream>
struct Foo {
void display_greeting() {
std::cout << "Hello, world.\n";
}
void display_number(int i) {
std::cout << "number: " << i << '\n';
}
int data = 7;
};
int main() {
Foo f;
auto greet = std::mem_fn(&Foo::display_greeting);
greet(f);
auto print_num = std::mem_fn(&Foo::display_number);
print_num(f, 42);
auto access_data = std::mem_fn(&Foo::data);
std::cout << "data: " << access_data(f) << '\n';
}
- https://en.cppreference.com/w/cpp/utility/functional/mem_fn
std::uniform_int_distribution
- Produces random integer values
i, uniformly distributed on the closed interval[a, b], that is, distributed according to the discrete probability functionP(i|a,b) = 1/(b - a + 1)
#include <random>
#include <iostream>
int main()
{
std::random_device rd; //Will be used to obtain a seed for the random number engine
std::mt19937 gen(rd()); //Standard mersenne_twister_engine seeded with rd()
std::uniform_int_distribution<> distrib(1, 6);
for (int n=0; n<10; ++n)
//Use `distrib` to transform the random unsigned int generated by gen into an int in [1, 6]
std::cout << distrib(gen) << ' ';
std::cout << '\n';
}
/*
3 6 5 6 1 2 2 4 3 3
*/
- https://en.cppreference.com/w/cpp/numeric/random/uniform_int_distribution
std::bind
The function template bind generates a forwarding call wrapper for f. Calling this wrapper is equivalent to invoking f with some of its arguments bound to args.
f- Callable object (function object,pointer to function,reference to function,pointer to member function, orpointer to data member) that will be bound to some argumentsargs- list of arguments to bind, with the unbound arguments replaced by the placeholders_1,_2,_3… of namespacestd::placeholders- As described in
Callable, when invoking apointer to non-static member functionorpointer to non-static data member, the first argument has to be a reference or pointer (including, possibly, smart pointer such as std::shared_ptr and std::unique_ptr) to an object whose member will be accessed. - The arguments to bind are copied or moved, and are never passed by reference unless wrapped in
std::reforstd::cref. - Duplicate placeholders in the same bind expression (multiple
_1’s for example) are allowed, but the results are only well defined if the corresponding argument (u1) is anlvalueornon-movable rvalue.
#include <random>
#include <iostream>
#include <memory>
#include <functional>
void f(int n1, int n2, int n3, const int& n4, int n5)
{
std::cout << n1 << ' ' << n2 << ' ' << n3 << ' ' << n4 << ' ' << n5 << '\n';
}
int g(int n1)
{
return n1;
}
struct Foo {
void print_sum(int n1, int n2)
{
std::cout << n1+n2 << '\n';
}
int data = 10;
};
int main()
{
using namespace std::placeholders; // for _1, _2, _3...
std::cout << "demonstrates argument reordering and pass-by-reference:\n";
int n = 7;
// (_1 and _2 are from std::placeholders, and represent future
// arguments that will be passed to f1)
auto f1 = std::bind(f, _2, 42, _1, std::cref(n), n);
n = 10;
f1(1, 2, 1001); // 1 is bound by _1, 2 is bound by _2, 1001 is unused
// makes a call to f(2, 42, 1, n, 7)
std::cout << "achieving the same effect using a lambda:\n";
auto lambda = [ncref=std::cref(n), n=n](auto a, auto b, auto /*unused*/) {
f(b, 42, a, ncref, n);
};
lambda(1, 2, 1001); // same as a call to f1(1, 2, 1001)
std::cout << "nested bind subexpressions share the placeholders:\n";
auto f2 = std::bind(f, _3, std::bind(g, _3), _3, 4, 5);
f2(10, 11, 12); // makes a call to f(12, g(12), 12, 4, 5);
std::cout << "bind to a pointer to member function:\n";
Foo foo;
auto f3 = std::bind(&Foo::print_sum, &foo, 95, _1);
f3(5);
std::cout << "bind to a pointer to data member:\n";
auto f4 = std::bind(&Foo::data, _1);
std::cout << f4(foo) << '\n';
std::cout << "use smart pointers to call members of the referenced objects:\n";
std::cout << f4(std::make_shared<Foo>(foo)) << ' '
<< f4(std::make_unique<Foo>(foo)) << '\n';
}
/*
demonstrates argument reordering and pass-by-reference:
2 42 1 10 7
achieving the same effect using a lambda:
2 42 1 10 10
nested bind subexpressions share the placeholders:
12 12 12 4 5
bind to a pointer to member function:
100
bind to a pointer to data member:
10
use smart pointers to call members of the referenced objects:
10 10
*/
- https://en.cppreference.com/w/cpp/utility/functional/bind
override specifier (覆盖)
Specifies that a virtual function overrides another virtual function.
The override keyword serves two purposes:
- It shows the reader of the code that “this is a virtual method, that is overriding a virtual method of the base class.”
- The compiler also knows that it’s an override, so it can “check” that you are not altering/adding new methods that you think are overrides.
class base
{
public:
virtual int foo(float x) = 0;
};
class derived: public base
{
public:
int foo(float x) override { ... } // OK
}
class derived2: public base
{
public:
int foo(int x) override { ... } // ERROR
};
In derived2 the compiler will issue an error for “changing the type”. Without override, at most the compiler would give a warning for “you are hiding virtual method by same name”.
- https://en.cppreference.com/w/cpp/language/override
- https://stackoverflow.com/questions/18198314/what-is-the-override-keyword-in-c-used-for
std::abort
Causes abnormal program termination unless SIGABRT is being caught by a signal handler passed to std::signal and the handler does not return.
#include <csignal>
#include <iostream>
#include <cstdlib>
class Tester {
public:
Tester() { std::cout << "Tester ctor\n"; }
~Tester() { std::cout << "Tester dtor\n"; }
};
Tester static_tester; // Destructor not called
void signal_handler(int signal)
{
if (signal == SIGABRT) {
std::cerr << "SIGABRT received\n";
} else {
std::cerr << "Unexpected signal " << signal << " received\n";
}
std::_Exit(EXIT_FAILURE);
}
int main()
{
Tester automatic_tester; // Destructor not called
// Setup handler
auto previous_handler = std::signal(SIGABRT, signal_handler);
if (previous_handler == SIG_ERR) {
std::cerr << "Setup failed\n";
return EXIT_FAILURE;
}
std::abort(); // Raise SIGABRT
std::cout << "This code is unreachable\n";
}
/*
Tester ctor
Tester ctor
SIGABRT received
*/
std::is_class
Checks whether T is a non-union class type. Provides the member constant value which is equal to true, if T is a class type (but not union). Otherwise, value is equal to false.
How does this implementation of std::is_class work?
#include <iostream>
#include <type_traits>
struct A {};
class B {};
enum class C {};
union D { class E {}; };
static_assert(not std::is_class_v<D>);
int main()
{
std::cout << std::boolalpha;
std::cout << std::is_class<A>::value << '\n';
std::cout << std::is_class_v<B> << '\n'; // C++17 helper
std::cout << std::is_class<C>::value << '\n';
std::cout << std::is_class_v<int> << '\n';
}
/*
true
true
false
false
*/
decltype specifier
Inspects the declared type of an entity or the type and value category of an expression.
#include <iostream>
#include <type_traits>
struct A { double x; };
const A* a;
decltype(a->x) y; // type of y is double (declared type)
decltype((a->x)) z = y; // type of z is const double& (lvalue expression)
template<typename T, typename U>
auto add(T t, U u) -> decltype(t + u) // return type depends on template parameters
// return type can be deduced since C++14
{
return t + u;
}
const int& getRef(const int* p) { return *p; }
static_assert(std::is_same_v<decltype(getRef), const int&(const int*)>);
auto getRefFwdBad(const int* p) { return getRef(p); }
static_assert(std::is_same_v<decltype(getRefFwdBad), int(const int*)>,
"Just returning auto isn't perfect forwarding.");
decltype(auto) getRefFwdGood(const int* p) { return getRef(p); }
static_assert(std::is_same_v<decltype(getRefFwdGood), const int&(const int*)>,
"Returning decltype(auto) perfectly forwards the return type.");
// Alternatively:
auto getRefFwdGood1(const int* p) -> decltype(getRef(p)) { return getRef(p); }
static_assert(std::is_same_v<decltype(getRefFwdGood1), const int&(const int*)>,
"Returning decltype(return expression) also perfectly forwards the return type.");
int main()
{
int i = 33;
decltype(i) j = i * 2;
std::cout << "i and j are the same type? " << std::boolalpha
<< std::is_same_v<decltype(i), decltype(j)> << '\n';
std::cout << "i = " << i << ", "
<< "j = " << j << '\n';
auto f = [](int a, int b) -> int
{
return a * b;
};
decltype(f) g = f; // the type of a lambda function is unique and unnamed
i = f(2, 2);
j = g(3, 3);
std::cout << "i = " << i << ", "
<< "j = " << j << '\n';
}
/*
i and j are the same type? true
i = 33, j = 66
i = 4, j = 9
*/
https://en.cppreference.com/w/cpp/language/decltype
std::declval
Converts any type T to a reference type, making it possible to use member functions in the operand of the decltype specifier without the need to go through constructors.
std::declval is commonly used in templates where acceptable template parameters may have no constructor in common, but have the same member function whose return type is needed.
Note that std::declval can only be used in unevaluated contexts and is not required to be defined; it is an error to evaluate an expression that contains this function. Formally, the program is ill-formed if this function is odr-used.
Possible implementation:
template<typename T>
constexpr bool always_false = false;
template<typename T>
typename std::add_rvalue_reference<T>::type declval() noexcept
{
static_assert(always_false<T>, "declval not allowed in an evaluated context");
}
Example:
#include <utility>
#include <iostream>
struct Default
{
int foo() const { return 1; }
};
struct NonDefault
{
NonDefault() = delete;
int foo() const { return 1; }
};
int main()
{
decltype(Default().foo()) n1 = 1; // type of n1 is int
// decltype(NonDefault().foo()) n2 = n1; // error: no default constructor
decltype(std::declval<NonDefault>().foo()) n2 = n1; // type of n2 is int
std::cout << "n1 = " << n1 << '\n'
<< "n2 = " << n2 << '\n';
}
/*
n1 = 1
n2 = 1
*/
https://en.cppreference.com/w/cpp/utility/declval
std::is_convertible
https://en.cppreference.com/w/cpp/types/is_convertible
std::is_union
Checks whether T is a union type. Provides the member constant value, which is equal to true if T is a union type. Otherwise, value is equal to false.
#include <iostream>
#include <type_traits>
struct A {};
typedef union {
int a;
float b;
} B;
struct C {
B d;
};
int main()
{
std::cout << std::boolalpha;
std::cout << std::is_union<A>::value << '\n';
std::cout << std::is_union<B>::value << '\n';
std::cout << std::is_union<C>::value << '\n';
std::cout << std::is_union<int>::value << '\n';
}
/*
false
true
false
false
*/
std::next
Return the nth successor of iterator it.
#include <iostream>
#include <iterator>
#include <vector>
int main()
{
std::vector<int> v{ 4, 5, 6 };
auto it = v.begin();
auto nx = std::next(it, 2);
std::cout << *it << ' ' << *nx << '\n';
it = v.end();
nx = std::next(it, -2);
std::cout << ' ' << *nx << '\n';
}
/*
4 6
5
*/
- https://en.cppreference.com/w/cpp/iterator/next
std::distance
Returns the number of hops from first to last.
#include <iostream>
#include <iterator>
#include <vector>
int main()
{
std::vector<int> v{ 3, 1, 4 };
std::cout << "distance(first, last) = "
<< std::distance(v.begin(), v.end()) << '\n'
<< "distance(last, first) = "
<< std::distance(v.end(), v.begin()) << '\n';
//the behavior is undefined (until C++11)
static constexpr auto il = { 3, 1, 4 };
// Since C++17 `distance` can be used in constexpr context.
static_assert(std::distance(il.begin(), il.end()) == 3);
static_assert(std::distance(il.end(), il.begin()) == -3);
}
/*
distance(first, last) = 3
distance(last, first) = -3
*/
- https://en.cppreference.com/w/cpp/iterator/distance
std::has_virtual_destructor
If T is a type with a virtual destructor, provides the member constant value equal to true. For any other type, value is false.
#include <iostream>
#include <type_traits>
#include <string>
#include <stdexcept>
int main()
{
std::cout << std::boolalpha
<< "std::string has a virtual destructor? "
<< std::has_virtual_destructor<std::string>::value << '\n'
<< "std::runtime_error has a virtual destructor? "
<< std::has_virtual_destructor<std::runtime_error>::value << '\n';
}
/*
std::string has a virtual destructor? false
std::runtime_error has a virtual destructor? true
*/
- https://en.cppreference.com/w/cpp/types/has_virtual_destructor
std::align
void* align( std::size_t alignment,
std::size_t size,
void*& ptr,
std::size_t& space );
alignment: the desired alignment
size: the size of the storage to be aligned
ptr: pointer to contiguous storage (a buffer) of at least space bytes
space: the size of the buffer in which to operate
Given a pointer ptr to a buffer of size space, returns a pointer aligned by the specified alignment for size number of bytes and decreases space argument by the number of bytes used for alignment. The first aligned address is returned.
The function modifies the pointer only if it would be possible to fit the wanted number of bytes aligned by the given alignment into the buffer. If the buffer is too small, the function does nothing and returns nullptr.
The behavior is undefined if alignment is not a power of two.
Example: demonstrates the use of std::align to place objects of different type in memory
#include <iostream>
#include <memory>
template <std::size_t N>
struct MyAllocator
{
char data[N];
void* p;
std::size_t sz;
MyAllocator() : p(data), sz(N) {}
template <typename T>
T* aligned_alloc(std::size_t a = alignof(T))
{
if (std::align(a, sizeof(T), p, sz))
{
T* result = reinterpret_cast<T*>(p);
p = (char*)p + sizeof(T);
sz -= sizeof(T);
return result;
}
return nullptr;
}
};
int main()
{
MyAllocator<64> a;
std::cout << "allocated a.data at " << (void*)a.data
<< " (" << sizeof a.data << " bytes)\n";
// allocate a char
if (char* p = a.aligned_alloc<char>()) {
*p = 'a';
std::cout << "allocated a char at " << (void*)p << '\n';
}
// allocate an int
if (int* p = a.aligned_alloc<int>()) {
*p = 1;
std::cout << "allocated an int at " << (void*)p << '\n';
}
// allocate an int, aligned at 32-byte boundary
if (int* p = a.aligned_alloc<int>(32)) {
*p = 2;
std::cout << "allocated an int at " << (void*)p << " (32 byte alignment)\n";
}
}
/*
allocated a.data at 0x7ffd8d5dd980 (64 bytes)
allocated a char at 0x7ffd8d5dd980
allocated an int at 0x7ffd8d5dd984
allocated an int at 0x7ffd8d5dd9a0 (32 byte alignment)
*/
- https://en.cppreference.com/w/cpp/memory/align
std::priority_queue (heap)
A priority queue is a container adaptor that provides constant time lookup of the largest (by default) element, at the expense of logarithmic insertion and extraction.
A user-provided Compare can be supplied to change the ordering, e.g. using std::greater<T> would cause the smallest element to appear as the top().
Working with a priority_queue is similar to managing a heap in some random access container, with the benefit of not being able to accidentally invalidate the heap.
#include <functional>
#include <queue>
#include <vector>
#include <iostream>
template<typename T>
void print_queue(T q) { // NB: pass by value so the print uses a copy
while(!q.empty()) {
std::cout << q.top() << ' ';
q.pop();
}
std::cout << '\n';
}
int main() {
std::priority_queue<int> q;
const auto data = {1,8,5,6,3,4,0,9,7,2};
for(int n : data)
q.push(n);
print_queue(q);
std::priority_queue<int, std::vector<int>, std::greater<int>>
q2(data.begin(), data.end());
print_queue(q2);
// Using lambda to compare elements.
auto cmp = [](int left, int right) { return (left ^ 1) < (right ^ 1); };
std::priority_queue<int, std::vector<int>, decltype(cmp)> q3(cmp);
for(int n : data)
q3.push(n);
print_queue(q3);
}
/*
9 8 7 6 5 4 3 2 1 0
0 1 2 3 4 5 6 7 8 9
8 9 6 7 4 5 2 3 0 1
*/
- https://en.cppreference.com/w/cpp/container/priority_queue
- https://blog.csdn.net/fengbingchun/article/details/70505628
std::tie
#include <iostream>
#include <string>
#include <set>
#include <tuple>
struct S {
int n;
std::string s;
float d;
bool operator<(const S& rhs) const
{
// compares n to rhs.n,
// then s to rhs.s,
// then d to rhs.d
return std::tie(n, s, d) < std::tie(rhs.n, rhs.s, rhs.d);
}
};
int main()
{
std::set<S> set_of_s; // S is LessThanComparable
S value{42, "Test", 3.14};
std::set<S>::iterator iter;
bool inserted;
// unpacks the return value of insert into iter and inserted
std::tie(iter, inserted) = set_of_s.insert(value);
if (inserted)
std::cout << "Value was inserted successfully\n";
}
// Value was inserted successfully
- https://en.cppreference.com/w/cpp/utility/tuple/tie
std::is_integral
template< class T >
struct is_integral;
// since C++17
template< class T >
inline constexpr bool is_integral_v = is_integral<T>::value;
Checks whether T is an integral type. Provides the member constant value which is equal to true, if T is the type bool, char, char8_t (since C++20), char16_t, char32_t, wchar_t, short, int, long, long long, or any implementation-defined extended integer types, including any signed, unsigned, and cv-qualified variants. Otherwise, value is equal to false.
#include <iostream>
#include <iomanip>
#include <type_traits>
class A {};
enum E : int {};
template <class T>
T f(T i)
{
static_assert(std::is_integral<T>::value, "Integral required.");
return i;
}
#define SHOW(...) std::cout << std::setw(29) << #__VA_ARGS__ << " == " << __VA_ARGS__ << '\n'
int main()
{
std::cout << std::boolalpha;
SHOW( std::is_integral<A>::value );
SHOW( std::is_integral_v<E> );
SHOW( std::is_integral_v<float> );
SHOW( std::is_integral_v<int> );
SHOW( std::is_integral_v<const int> );
SHOW( std::is_integral_v<bool> );
SHOW( f(123) );
}
/*
std::is_integral<A>::value == false
std::is_integral_v<E> == false
std::is_integral_v<float> == false
std::is_integral_v<int> == true
std::is_integral_v<const int> == true
std::is_integral_v<bool> == true
f(123) == 123
*/
https://en.cppreference.com/w/cpp/types/is_integral
std::is_floating_point
template< class T >
struct is_floating_point;
// since C++17
template< class T >
inline constexpr bool is_floating_point_v = is_floating_point<T>::value;
// Possible implementation
template< class T >
struct is_floating_point
: std::integral_constant<
bool,
std::is_same<float, typename std::remove_cv<T>::type>::value ||
std::is_same<double, typename std::remove_cv<T>::type>::value ||
std::is_same<long double, typename std::remove_cv<T>::type>::value
> {};
Checks whether T is a floating-point type. Provides the member constant value which is equal to true, if T is the type float, double, long double, including any cv-qualified variants. Otherwise, value is equal to false.
#include <iostream>
#include <type_traits>
class A {};
int main()
{
std::cout << std::boolalpha;
std::cout << " A: " << std::is_floating_point<A>::value << '\n';
std::cout << " float: " << std::is_floating_point<float>::value << '\n';
std::cout << " float&: " << std::is_floating_point<float&>::value << '\n';
std::cout << " double: " << std::is_floating_point<double>::value << '\n';
std::cout << "double&: " << std::is_floating_point<double&>::value << '\n';
std::cout << " int: " << std::is_floating_point<int>::value << '\n';
}
/*
A: false
float: true
float&: false
double: true
double&: false
int: false
*/
https://en.cppreference.com/w/cpp/types/is_floating_point
std::remove / std::remove_if
#include <algorithm>
#include <cctype>
#include <iostream>
#include <string>
#include <string_view>
int main()
{
std::string str1 {"Text with some spaces"};
auto noSpaceEnd = std::remove(str1.begin(), str1.end(), ' ');
// The spaces are removed from the string only logically.
// Note, we use view, the original string is still not shrunk:
std::cout << std::string_view(str1.begin(), noSpaceEnd)
<< " size: " << str1.size() << '\n';
str1.erase(noSpaceEnd, str1.end());
// The spaces are removed from the string physically.
std::cout << str1 << " size: " << str1.size() << '\n';
std::string str2 = "Text\n with\tsome \t whitespaces\n\n";
str2.erase(std::remove_if(str2.begin(),
str2.end(),
[](unsigned char x) { return std::isspace(x); }),
str2.end());
std::cout << str2 << '\n';
}
/*
Textwithsomespaces size: 23
Textwithsomespaces size: 18
Textwithsomewhitespaces
*/
https://en.cppreference.com/w/cpp/algorithm/remove
std::enable_if
template< bool B, class T = void >
struct enable_if;
If B is true, std::enable_if has a public member typedef type, equal to T; otherwise, there is no member typedef.
https://en.cppreference.com/w/cpp/types/enable_if
std::atomic (代替 volatile)
Question:
In C++11 standard the machine model changed from a single thread machine to a multi threaded machine.
Does this mean that the typical static int x; void func() { x = 0; while (x == 0) {} } example of optimized out read will no longer happen in C++11?
EDIT: for those who don’t know this example (I’m seriously astonished), please read this: https://en.wikipedia.org/wiki/Volatile_variable
EDIT2: OK, I was really expecting that everyone who knew what volatile is has seen this example.
If you use the code in the example the variable read in the cycle will be optimized out, making the cycle endless.
The solution of course is to use volatile which will force the compiler to read the variable on each access.
My question is if this is a deprecated problem in C++11, since the machine model is multi-threaded, therefore the compiler should consider concurrent access to variable to be present in the system.
Answer:
Let’s look at the code you cite, with respect to the standard. Section 1.10, p8 speaks of the ability of certain library calls to cause a thread to “synchronize with” another thread. Most of the other paragraphs explain how synchronization (and other things) build an order of operations between threads. Of course, your code doesn’t invoke any of this. There is no synchronization point, no dependency ordering, nothing.
It does rely on ordering and atomicity. The change from the other thread must become visible to this one. Which means it must become ordered before some operation in this thread. Since volatile doesn’t deal with ordering, there is no guarantee that it will become visible.
#include <iostream>
#include <chrono>
#include <thread>
#include <atomic>
using namespace std;
// int notify;
// volatile int notify;
atomic<int> notify;
void watcher()
{
this_thread::sleep_for(chrono::seconds(2));
notify = 1;
cout << "Notification sent." << endl;
}
int main()
{
thread(watcher).detach();
notify = 0;
while (!notify)
{
cout << "Waiting." << endl;
this_thread::sleep_for(chrono::seconds(1));
}
cout << "Notification received." << endl;
return 0;
}
编译:
g++ volatile.cc -std=c++11 -lpthread
执行:
Waiting.
Waiting.
Notification sent.
Notification received.
Without such protection, without some form of synchronization or ordering, 1.10 p21 comes in:
The execution of a program contains a data race if it contains two conflicting actions in different threads, at least one of which is not atomic, and neither happens before the other. Any such data race results in undefined behavior.
Your program contains two conflicting actions (reading from x and writing to x). Neither is atomic, and neither is ordered by synchronization to happen before the other.
Thus, you have achieved undefined behavior.
So the only case where you get guaranteed multithreaded behavior by the C++11 memory model is if you use a proper mutex or std::atomic<int> x with the proper atomic load/store calls.
Oh, and you don’t need to make x volatile too. Anytime you call a (non-inline) function, that function or something it calls could modify a global variable. So it cannot optimize away the read of x in the while loop. And every C++11 mechanism to synchronize requires calling a function. That just so happens to invoke a memory barrier.
template< class T >
struct atomic;
template< class U >
struct atomic<U*>;
Each instantiation and full specialization of the std::atomic template defines an atomic type. If one thread writes to an atomic object while another thread reads from it, the behavior is well-defined (see memory model for details on data races).
In addition, accesses to atomic objects may establish inter-thread synchronization and order non-atomic memory accesses as specified by std::memory_order.
std::atomic is neither copyable nor movable.
// std::atomic<T>::load
T load( std::memory_order order = std::memory_order_seq_cst ) const noexcept;
T load( std::memory_order order = std::memory_order_seq_cst ) const volatile noexcept;
Atomically loads and returns the current value of the atomic variable. Memory is affected according to the value of order.
order must be one of std::memory_order_relaxed, std::memory_order_consume, std::memory_order_acquire or std::memory_order_seq_cst. Otherwise the behavior is undefined.
Floating point atomics are only supported by the C++ library in g++ 10.1 and later. See https://gcc.gnu.org/onlinedocs/libstdc++/manual/status.html and search for P0020R6.
Your code compiles fine with g++ 10.2: Try on godbolt
参考:https://en.cppreference.com/w/cpp/atomic/atomic/fetch_add
member only of
atomic<Integral>(C++11) andatomic<Floating>(C++20) template specializations
参考:https://stackoverflow.com/questions/58680928/c20-stdatomicfloat-stdatomicdouble-specializations
atomic<float> and atomic<double> have existed since C++11. The atomic<T> template works for arbitrary trivially-copyable T. Everything you could hack up with legacy pre-C++11 use of volatile for shared variables can be done with C++11 atomic<double> with std::memory_order_relaxed.
What doesn’t exist until C++20 are atomic RMW operations like x.fetch_add(3.14); or for short x += 3.14. (Why isn’t atomic double fully implemented wonders why not). Those member functions were only available in the atomic integer specializations, so you could only load, store, exchange, and CAS on float and double, like for arbitrary T like class types.
测试代码:
#include <iostream>
#include <atomic>
struct Foo
{
int baz;
int bar;
};
int main () {
std::atomic<Foo> atomic_foo {Foo {1, 2}};
auto foo {atomic_foo.load()};
return 0;
}
- int 使用 x86-64 gcc 4.8.5 编译正常
- int 使用 x86-64 clang 3.5.2,编译提示:undefined reference to __atomic_load_8 错误,编译需要额外链接
-latomic - 如果将 int 改为 long,使用 x86-64 gcc 4.8.5,编译提示:undefined reference to __atomic_load_16 错误,编译需要额外链接
-latomic
参考:To use 16-byte atomics with gcc you need -latomic
Just like
-lmif you use any math.h functions, use-latomicif you use any<atomic>functions. The difference is that many math library functions won’t inline, but most stuff you use from<atomic>will be lock-free and inline so you don’t normally actually need any functions from the shared library. So you can go a long time before hitting a case where you actually do need-latomic. GCC7 changed 16-byte atomics to not inline even with -mcx16 (cmpxchg16b), and not to call them lock-free. (Even though they actually are; only the earlier AMD64 were missing cmpxchg16b.On my Arch Linux system, /usr/lib/libatomic.so is owned by gcc-libs 9.1.0-2 according to pacman (Arch’s equivalent of rpm). On an Ubuntu system, /usr/lib/x86_64-linux-gnu/libatomic.so.1 seems to be packaged in the libatomic1 package, which gcc dev packages depend on. And there are
.astatic versions of it in gcc directories, according to locate libatomic.
How To Install libatomic on CentOS 7
What is libatomic ?
This package contains the GNU Atomic library which is a GCC support runtime library for atomic operations not supported by hardware. This package contains the GNU Atomic library which is a GCC support runtime library for atomic operations not supported by hardware.
在 CentOS 上安装 libatomic 库:
# 安装
sudo yum install libatomic
# 查看版本信息
rpm -qa | grep libatomic
# 查看所在目录
ldconfig -p | grep libatomic
参考问题:C++ 11 undefined reference to _atomic*
Atomic API is not complete in GCC 4.7
When lock free instructions are not available (either through hardware or OS support) atomic operations are left as function calls to be resolved by a library. Due to time constraints and an API which is not finalized, there is no libatomic supplied with GCC 4.7. This is easily determined by encountering unsatisfied external symbols beginning with
__atomic_*.
Since there is no libatomic shipped with GCC 4.7 you need to use another compiler which actually supports the features you want or provide the missing features.
refer:
- https://en.cppreference.com/w/cpp/atomic/atomic
- https://en.cppreference.com/w/cpp/atomic/atomic/load
std::is_base_of
template< class Base, class Derived >
struct is_base_of;
If Derived is derived from Base or if both are the same non-union class (in both cases ignoring cv-qualification), the base characteristic is std::true_type. Otherwise the base characteristic is std::false_type.
#include <type_traits>
class A {};
class B : A {};
class C : B {};
class D {};
union E {};
using I = int;
static_assert
(
std::is_base_of_v<A, A> == true &&
std::is_base_of_v<A, B> == true &&
std::is_base_of_v<A, C> == true &&
std::is_base_of_v<A, D> != true &&
std::is_base_of_v<B, A> != true &&
std::is_base_of_v<E, E> != true &&
std::is_base_of_v<I, I> != true
);
int main() {}
std::begin / std::end
在 C++11 及更高版本的标准中使用 std::begin 和 std::end 函数处理 C 风格数组(例如 uint64 auTime[TEST_CNT])。这是因为 C++11 标准库提供了针对 C 风格数组的 std::begin 和 std::end 函数模板特化,这些特化允许您使用这些函数处理 C 风格数组。
uint64 auTime[kTestCount];
std::sort(std::begin(auTime), std::end(auTime)); // [frist, last)
#include <iostream>
#include <iterator>
#include <vector>
int main()
{
std::vector<int> v = {3, 1, 4};
auto vi = std::begin(v);
std::cout << std::showpos << *vi << '\n';
int a[] = {-5, 10, 15};
auto ai = std::begin(a);
std::cout << *ai << '\n';
}
/*
+3
-5
*/
std::sort
#include <algorithm>
#include <array>
#include <functional>
#include <iostream>
#include <string_view>
int main()
{
std::array<int, 10> s {5, 7, 4, 2, 8, 6, 1, 9, 0, 3};
auto print = [&s](std::string_view const rem)
{
for (auto a : s)
std::cout << a << ' ';
std::cout << ": " << rem << '\n';
};
std::sort(s.begin(), s.end());
print("sorted with the default operator<");
std::sort(s.begin(), s.end(), std::greater<int>());
print("sorted with the standard library compare function object");
struct
{
bool operator()(int a, int b) const { return a < b; }
}
customLess;
std::sort(s.begin(), s.end(), customLess);
print("sorted with a custom function object");
std::sort(s.begin(), s.end(), [](int a, int b)
{
return a > b;
});
print("sorted with a lambda expression");
}
/*
0 1 2 3 4 5 6 7 8 9 : sorted with the default operator<
9 8 7 6 5 4 3 2 1 0 : sorted with the standard library compare function object
0 1 2 3 4 5 6 7 8 9 : sorted with a custom function object
9 8 7 6 5 4 3 2 1 0 : sorted with a lambda expression
*/
std::extent
template< class T, unsigned N = 0 >
struct extent;
std::extent 是 C++ 标准库中的一个模板类,用于获取数组的维度和大小。它接受一个数组类型和一个可选的非负整数常量作为参数,返回指定维度的数组大小。如果 T 是数组类型,则提供成员常量 value,该成员常量等于数组第 N 维的元素数量(如果 N 位于 [0, std::rank<T>::value) 中)。对于任何其他类型,或者如果 T 是沿其第一维度未知边界的数组,并且 N 是 0,则 value 是 0。
#include <iostream>ch
#include <type_traits>
int main()
{
static_assert(
std::extent_v<int[3]> == 3 && //< default dimension is 0
std::extent_v<int[3], 0> == 3 && //< the same as above
std::extent_v<int[3][4], 0> == 3 &&
std::extent_v<int[3][4], 1> == 4 &&
std::extent_v<int[3][4], 2> == 0 &&
std::extent_v<int[]> == 0
);
const auto ext = std::extent<int['*']>{};
std::cout << ext << '\n'; //< implicit conversion to std::size_t
const int ints[]{1, 2, 3, 4};
static_assert(std::extent_v<decltype(ints)> == 4); //< array size
[[maybe_unused]] int ary[][3] = {{1, 2, 3}};
// ary[0] is type of reference of 'int[3]', so, extent
// cannot calculate correctly and return 0
static_assert(std::is_same_v<decltype(ary[0]), int(&)[3]>);
static_assert(std::extent_v<decltype(ary[0])> == 0);
// removing reference will give correct extent value 3
static_assert(std::extent_v<std::remove_cvref_t<decltype(ary[0])>> == 3);
}
/*
42
*/
https://en.cppreference.com/w/cpp/types/extent
std::error_code
std::error_code represents a platform-dependent error code value. Each std::error_code object holds an error code value originating from the operating system or some low-level interface and a pointer to an object of type std::error_category, which corresponds to the said interface. The error code values are not required to be unique across different error categories.
#include <system_error>
#include <iostream>
#include <fstream>
int main()
{
// 创建文件,可能失败
std::ifstream file("nonexistent_file.txt");
if (!file) {
// 从 errno 创建 error_code
std::error_code ec(errno, std::generic_category());
std::cout << "Error value: " << ec.value() << std::endl;
std::cout << "Error message: " << ec.message() << std::endl;
std::cout << "Error category: " << ec.category().name() << std::endl;
}
}
/*
Error value: 2
Error message: No such file or directory
Error category: generic
*/
C++14
C++ attribute: deprecated
Indicates that the name or entity declared with this attribute is deprecated, that is, the use is allowed, but discouraged for some reason.
[[deprecated]]
// string-literal - an unevaluated string literal that could be used to explain the rationale for deprecation and/or to suggest a replacing entity
[[deprecated( string-literal )]]
Indicates that the use of the name or entity declared with this attribute is allowed, but discouraged for some reason. Compilers typically issue warnings on such uses. The string-literal, if specified, is usually included in the warnings.
This attribute is allowed in declarations of the following names or entities:
- class/struct/union
struct [[deprecated]] S;
- typedef-name, including those declared by alias declaration
[[deprecated]] typedef S* PS;
using PS [[deprecated]] = S*;
- (non-member) variable
[[deprecated]] int x;
- static data member
struct S { [[deprecated]] static constexpr char CR{13}; };
- non-static data member
union U { [[deprecated]] int n; };
- function
[[deprecated]] void f();
- namespace
namespace [[deprecated]] NS { int x; }
- enumeration
enum [[deprecated]] E {};
- template specialization
template<> struct [[deprecated]] X<int> {};
代码示例:
#include <iostream>
[[deprecated]]
void TriassicPeriod()
{
std::clog << "Triassic Period: [251.9 - 208.5] million years ago.\n";
}
[[deprecated("Use NeogenePeriod() instead.")]]
void JurassicPeriod()
{
std::clog << "Jurassic Period: [201.3 - 152.1] million years ago.\n";
}
[[deprecated("Use calcSomethingDifferently(int).")]]
int calcSomething(int x)
{
return x * 2;
}
int main()
{
TriassicPeriod();
JurassicPeriod();
}
输出:
<source>:23:5: warning: 'TriassicPeriod' is deprecated [-Wdeprecated-declarations]
TriassicPeriod();
^
<source>:3:3: note: 'TriassicPeriod' has been explicitly marked deprecated here
[[deprecated]]
^
<source>:24:5: warning: 'JurassicPeriod' is deprecated: Use NeogenePeriod() instead. [-Wdeprecated-declarations]
JurassicPeriod();
^
<source>:9:3: note: 'JurassicPeriod' has been explicitly marked deprecated here
[[deprecated("Use NeogenePeriod() instead.")]]
^
2 warnings generated.
ASM generation compiler returned: 0
<source>:23:5: warning: 'TriassicPeriod' is deprecated [-Wdeprecated-declarations]
TriassicPeriod();
^
<source>:3:3: note: 'TriassicPeriod' has been explicitly marked deprecated here
[[deprecated]]
^
<source>:24:5: warning: 'JurassicPeriod' is deprecated: Use NeogenePeriod() instead. [-Wdeprecated-declarations]
JurassicPeriod();
^
<source>:9:3: note: 'JurassicPeriod' has been explicitly marked deprecated here
[[deprecated("Use NeogenePeriod() instead.")]]
^
2 warnings generated.
Execution build compiler returned: 0
Program returned: 0
Triassic Period: [251.9 - 208.5] million years ago.
Jurassic Period: [201.3 - 152.1] million years ago.
老的实现方式:
#if defined(__GNUC__) || defined(__clang__)
#define DEPRECATED(func) func __attribute__ ((deprecated))
#elif defined(_MSC_VER)
#define DEPRECATED(func) __declspec(deprecated) func
#else
#pragma message("WARNING: You need to implement DEPRECATED for this compiler")
#define DEPRECATED(func) func
#endif
https://en.cppreference.com/w/cpp/language/attributes/deprecated
std::for_each
#include <map>
#include <algorithm>
int main()
{
std::map<int, int> m { {1,1}, {2,2}, {3,3} };
std::cout << m.size() << std::endl; // 3
for (auto cur = m.begin(); cur != m.end();) {
if (cur->first == 1 || cur->first == 3) {
cur = m.erase(cur);
} else {
++cur;
}
}
std::cout << m.size() << std::endl; // 1
std::for_each(m.begin(), m.end(), [](const auto& pair) {std::cout << pair.first << std::endl;}); // 2
}
- https://en.cppreference.com/w/cpp/algorithm/for_each
Integer literal (1’000’000)
// This feature is introduced since C++14. It uses single quote (') as digit separator
int i = 1'000'000;
- https://en.cppreference.com/w/cpp/language/integer_literal
C++17
std::scoped_lock
template< class... MutexTypes >
class scoped_lock;
The class scoped_lock is a mutex wrapper that provides a convenient RAII-style mechanism for owning zero or more mutexes for the duration of a scoped block.
When a scoped_lock object is created, it attempts to take ownership of the mutexes it is given. When control leaves the scope in which the scoped_lock object was created, the scoped_lock is destructed and the mutexes are released. If several mutexes are given, deadlock avoidance algorithm is used as if by std::lock.
The following example uses std::scoped_lock to lock pairs of mutexes without deadlock and is RAII-style.
#include <chrono>
#include <functional>
#include <iostream>
#include <mutex>
#include <string>
#include <thread>
#include <vector>
using namespace std::chrono_literals;
struct Employee
{
std::vector<std::string> lunch_partners;
std::string id;
std::mutex m;
Employee(std::string id) : id(id) {}
std::string partners() const
{
std::string ret = "Employee " + id + " has lunch partners: ";
for (int count{}; const auto& partner : lunch_partners)
ret += (count++ ? ", " : "") + partner;
return ret;
}
};
void send_mail(Employee&, Employee&)
{
// Simulate a time-consuming messaging operation
std::this_thread::sleep_for(1s);
}
void assign_lunch_partner(Employee& e1, Employee& e2)
{
static std::mutex io_mutex;
{
std::lock_guard<std::mutex> lk(io_mutex);
std::cout << e1.id << " and " << e2.id << " are waiting for locks" << std::endl;
}
{
// Use std::scoped_lock to acquire two locks without worrying about
// other calls to assign_lunch_partner deadlocking us
// and it also provides a convenient RAII-style mechanism
std::scoped_lock lock(e1.m, e2.m);
// Equivalent code 1 (using std::lock and std::lock_guard)
// std::lock(e1.m, e2.m);
// std::lock_guard<std::mutex> lk1(e1.m, std::adopt_lock);
// std::lock_guard<std::mutex> lk2(e2.m, std::adopt_lock);
// Equivalent code 2 (if unique_locks are needed, e.g. for condition variables)
// std::unique_lock<std::mutex> lk1(e1.m, std::defer_lock);
// std::unique_lock<std::mutex> lk2(e2.m, std::defer_lock);
// std::lock(lk1, lk2);
{
std::lock_guard<std::mutex> lk(io_mutex);
std::cout << e1.id << " and " << e2.id << " got locks" << std::endl;
}
e1.lunch_partners.push_back(e2.id);
e2.lunch_partners.push_back(e1.id);
}
send_mail(e1, e2);
send_mail(e2, e1);
}
int main()
{
Employee alice("Alice"), bob("Bob"), christina("Christina"), dave("Dave");
// Assign in parallel threads because mailing users about lunch assignments
// takes a long time
std::vector<std::thread> threads;
threads.emplace_back(assign_lunch_partner, std::ref(alice), std::ref(bob));
threads.emplace_back(assign_lunch_partner, std::ref(christina), std::ref(bob));
threads.emplace_back(assign_lunch_partner, std::ref(christina), std::ref(alice));
threads.emplace_back(assign_lunch_partner, std::ref(dave), std::ref(bob));
for (auto& thread : threads)
thread.join();
std::cout << alice.partners() << '\n' << bob.partners() << '\n'
<< christina.partners() << '\n' << dave.partners() << '\n';
}
Possible output:
Alice and Bob are waiting for locks
Alice and Bob got locks
Christina and Bob are waiting for locks
Christina and Alice are waiting for locks
Dave and Bob are waiting for locks
Dave and Bob got locks
Christina and Alice got locks
Christina and Bob got locks
Employee Alice has lunch partners: Bob, Christina
Employee Bob has lunch partners: Alice, Dave, Christina
Employee Christina has lunch partners: Alice, Bob
Employee Dave has lunch partners: Bob
https://en.cppreference.com/w/cpp/thread/scoped_lock
std::shared_mutex
std::shared_mutex 是 C++17 标准中引入的一种同步原语,用于保护共享数据不被多个线程同时访问。与传统的互斥锁(如 std::mutex)不同,std::shared_mutex 提供了两种访问模式:共享模式和独占模式。
- 共享模式(Shared Mode)
在共享模式下,多个线程可以同时持有该互斥锁的所有权,这使得多个读线程可以同时访问同一资源而不引发数据竞争。这种机制特别适用于读多写少的场景,例如多个客户端同时读取服务器上的数据结构。
- 独占模式(Exclusive Mode)
在独占模式下,只有一个线程可以持有该互斥锁的所有权,其他所有尝试获取该互斥锁的线程将被阻塞,直到独占模式的线程释放锁为止。这种模式类似于传统的互斥锁,确保了写操作的原子性。
性能优势
相比于传统的 std::mutex,std::shared_mutex 在读多写少的场景下具有显著的性能优势。这是因为 std::shared_mutex 可以让多个读线程同时访问共享资源,而不需要像 std::mutex 那样每次只能有一个线程访问。
The shared_mutex class is a synchronization primitive that can be used to protect shared data from being simultaneously accessed by multiple threads. In contrast to other mutex types which facilitate exclusive access, a shared_mutex has two levels of access:
- shared - several threads can share ownership of the same mutex.
- exclusive - only one thread can own the mutex.
#include <iostream>
#include <mutex>
#include <shared_mutex>
#include <syncstream>
#include <thread>
class ThreadSafeCounter
{
public:
ThreadSafeCounter() = default;
// Multiple threads/readers can read the counter's value at the same time.
unsigned int get() const
{
std::shared_lock lock(mutex_);
return value_;
}
// Only one thread/writer can increment/write the counter's value.
void increment()
{
std::unique_lock lock(mutex_);
++value_;
}
// Only one thread/writer can reset/write the counter's value.
void reset()
{
std::unique_lock lock(mutex_);
value_ = 0;
}
private:
mutable std::shared_mutex mutex_;
unsigned int value_{};
};
int main()
{
ThreadSafeCounter counter;
auto increment_and_print = [&counter]()
{
for (int i{}; i != 3; ++i)
{
counter.increment();
std::osyncstream(std::cout)
<< std::this_thread::get_id() << ' ' << counter.get() << '\n';
}
};
std::thread thread1(increment_and_print);
std::thread thread2(increment_and_print);
thread1.join();
thread2.join();
}
clang16 -std=c++20 编译:
123550899889728 2
123550899889728 3
123550899889728 4
123550908282432 4
123550908282432 5
123550908282432 6
https://en.cppreference.com/w/cpp/thread/shared_mutex
std::shared_timed_mutex (C++14)
The shared_timed_mutex class is a synchronization primitive that can be used to protect shared data from being simultaneously accessed by multiple threads. In contrast to other mutex types which facilitate exclusive access, a shared_timed_mutex has two levels of access:
- exclusive - only one thread can own the mutex.
- shared - several threads can share ownership of the same mutex.
Shared mutexes are usually used in situations when multiple readers can access the same resource at the same time without causing data races, but only one writer can do so.
In a manner similar to timed_mutex, shared_timed_mutex provides the ability to attempt to claim ownership of a shared_timed_mutex with a timeout via the try_lock_for(), try_lock_until(), try_lock_shared_for(), try_lock_shared_until() member functions.
The shared_timed_mutex class satisfies all requirements of SharedTimedMutex and StandardLayoutType.
#include <chrono>
#include <iostream>
#include <shared_mutex>
#include <syncstream>
#include <thread>
std::shared_timed_mutex m;
int i = 10;
void read_shared_var(int id)
{
// both the threads get access to the integer i
std::shared_lock<std::shared_timed_mutex> slk(m);
const int ii = i; // reads global i
std::osyncstream(std::cout) << '#' << id << " read i as " << ii << "...\n";
std::this_thread::sleep_for(std::chrono::milliseconds(10));
std::osyncstream(std::cout) << '#' << id << " woke up..." << std::endl;
}
int main()
{
std::thread r1{read_shared_var, 1};
std::thread r2{read_shared_var, 2};
r1.join();
r2.join();
}
Possible output:
#2 read i as 10...
#1 read i as 10...
#2 woke up...
#1 woke up...
https://en.cppreference.com/w/cpp/thread/shared_timed_mutex
std::unique_lock (C++11)
The class unique_lock is a general-purpose mutex ownership wrapper allowing deferred locking, time-constrained attempts at locking, recursive locking, transfer of lock ownership, and use with condition variables.
#include <iostream>
#include <mutex>
#include <thread>
struct Box
{
explicit Box(int num) : num_things{num} {}
int num_things;
std::mutex m;
};
void transfer(Box& from, Box& to, int num)
{
// don't actually take the locks yet
std::unique_lock lock1{from.m, std::defer_lock};
std::unique_lock lock2{to.m, std::defer_lock};
// lock both unique_locks without deadlock
std::lock(lock1, lock2);
from.num_things -= num;
to.num_things += num;
// “from.m” and “to.m” mutexes unlocked in unique_lock dtors
}
int main()
{
Box acc1{100};
Box acc2{50};
std::thread t1{transfer, std::ref(acc1), std::ref(acc2), 10};
std::thread t2{transfer, std::ref(acc2), std::ref(acc1), 5};
t1.join();
t2.join();
std::cout << "acc1: " << acc1.num_things << "\n"
"acc2: " << acc2.num_things << '\n';
}
/*
acc1: 95
acc2: 55
*/
https://en.cppreference.com/w/cpp/thread/unique_lock
std::shared_lock (C++14)
The class shared_lock is a general-purpose shared mutex ownership wrapper allowing deferred locking, timed locking and transfer of lock ownership. Locking a shared_lock locks the associated shared mutex in shared mode (to lock it in exclusive mode, std::unique_lock can be used).
https://en.cppreference.com/w/cpp/thread/shared_lock
What’s the difference between unique_lock and shared_lock in C++
Its pretty simple, really. unique_lock calls lock() on the mutex. shared_lock calls shared_lock().
The difference between them is that shared_lock is designed to support readers in a read/write lock. You can have multiple threads all acquire the shared lock and reading the same data, but if anyone wants to write to the data, they need to use lock to get permission to write to the data.
Which one you should use depends on the pattern you are looking for. There are plenty of times where a read/write lock is desired (which is why the standard includes support for them). There are also times where a simple unique mutex is called for. In general, if reading and writing are meaningful concepts to you, there’s a decent chance that a read/write mutex like shared_timed_mutex is the right approach.
When to use C++11 mutex, lock, unique_lock, and shared_lock?
Understanding std::unique_lock and std::shared_lock in C++
std::lock (C++11)
template< class Lockable1, class Lockable2, class... LockableN >
void lock( Lockable1& lock1, Lockable2& lock2, LockableN&... lockn );
Locks the given Lockable objects lock1, lock2, …, lockn using a deadlock avoidance algorithm to avoid deadlock.
The objects are locked by an unspecified series of calls to lock, try_lock, and unlock. If a call to lock or unlock results in an exception, unlock is called for any locked objects before rethrowing.
The following example uses std::lock to lock pairs of mutexes without deadlock.
#include <chrono>
#include <functional>
#include <iostream>
#include <mutex>
#include <string>
#include <thread>
#include <vector>
struct Employee
{
Employee(std::string id) : id(id) {}
std::string id;
std::vector<std::string> lunch_partners;
std::mutex m;
std::string output() const
{
std::string ret = "Employee " + id + " has lunch partners: ";
for (auto n{lunch_partners.size()}; const auto& partner : lunch_partners)
ret += partner + (--n ? ", " : "");
return ret;
}
};
void send_mail(Employee&, Employee&)
{
// Simulate a time-consuming messaging operation
std::this_thread::sleep_for(std::chrono::milliseconds(696));
}
void assign_lunch_partner(Employee& e1, Employee& e2)
{
static std::mutex io_mutex;
{
std::lock_guard<std::mutex> lk(io_mutex);
std::cout << e1.id << " and " << e2.id << " are waiting for locks" << std::endl;
}
// Use std::lock to acquire two locks without worrying about
// other calls to assign_lunch_partner deadlocking us
{
std::lock(e1.m, e2.m);
std::lock_guard<std::mutex> lk1(e1.m, std::adopt_lock);
std::lock_guard<std::mutex> lk2(e2.m, std::adopt_lock);
// Equivalent code (if unique_locks are needed, e.g. for condition variables)
// std::unique_lock<std::mutex> lk1(e1.m, std::defer_lock);
// std::unique_lock<std::mutex> lk2(e2.m, std::defer_lock);
// std::lock(lk1, lk2);
// Superior solution available in C++17
// std::scoped_lock lk(e1.m, e2.m);
{
std::lock_guard<std::mutex> lk(io_mutex);
std::cout << e1.id << " and " << e2.id << " got locks" << std::endl;
}
e1.lunch_partners.push_back(e2.id);
e2.lunch_partners.push_back(e1.id);
}
send_mail(e1, e2);
send_mail(e2, e1);
}
int main()
{
Employee alice("Alice"), bob("Bob"), christina("Christina"), dave("Dave");
// Assign in parallel threads because mailing users about lunch assignments
// takes a long time
std::vector<std::thread> threads;
threads.emplace_back(assign_lunch_partner, std::ref(alice), std::ref(bob));
threads.emplace_back(assign_lunch_partner, std::ref(christina), std::ref(bob));
threads.emplace_back(assign_lunch_partner, std::ref(christina), std::ref(alice));
threads.emplace_back(assign_lunch_partner, std::ref(dave), std::ref(bob));
for (auto& thread : threads)
thread.join();
std::cout << alice.output() << '\n'
<< bob.output() << '\n'
<< christina.output() << '\n'
<< dave.output() << '\n';
}
Possible output:
Alice and Bob are waiting for locks
Alice and Bob got locks
Christina and Bob are waiting for locks
Christina and Bob got locks
Christina and Alice are waiting for locks
Dave and Bob are waiting for locks
Dave and Bob got locks
Christina and Alice got locks
Employee Alice has lunch partners: Bob, Christina
Employee Bob has lunch partners: Alice, Christina, Dave
Employee Christina has lunch partners: Bob, Alice
Employee Dave has lunch partners: Bob
https://en.cppreference.com/w/cpp/thread/lock
std::size
// Returns c.size(), converted to the return type if necessary.
// c - a container or view with a size member function
// May throw implementation-defined exceptions.
template< class C >
constexpr auto size( const C& c ) -> decltype(c.size());
// Returns N
// array - an array of arbitrary type
template< class T, std::size_t N >
constexpr std::size_t size( const T (&array)[N] ) noexcept;
Returns the size of the given range.
代码示例:
#include <cassert>
#include <cstring>
#include <iostream>
#include <vector>
int main()
{
// Works with containers
std::vector<int> v{3, 1, 4};
assert(std::size(v) == 3);
// And works with built-in arrays too
int a[]{-5, 10, 15};
// Returns the number of elements (not bytes) as opposed to sizeof
assert(std::size(a) == 3);
std::cout << "size of a[]: " << sizeof a << '\n'; // 12, if sizeof(int) == 4
// Provides a safe way (compared to sizeof) of getting string buffer size
const char str[] = "12345";
// These are fine and give the correct result
assert(std::size(str) == 6);
assert(sizeof(str) == 6);
// But use of sizeof here is a common source of bugs
const char* str_decayed = "12345";
// std::cout << std::size(str_decayed) << '\n'; // Usefully fails to compile
std::cout << sizeof(str_decayed) << '\n'; // Prints the size of the pointer!
// Since C++20 the signed size (std::ssize) is available
auto i = std::ssize(v);
for (--i; i != -1; --i)
std::cout << v[i] << (i ? ' ' : '\n');
assert(i == -1);
// Note that the string literal includes the ending null character, which
// will be part of the constructed characters array. This makes std::size
// behave differently from std::strlen and std::string::size:
constexpr char symbols[] = "0123456789";
static_assert(std::size(symbols) == 11);
static_assert(std::string(symbols).size() == 10);
assert(std::strlen(symbols) == 10);
}
/*
size of a[]: 12
8
4 1 3
*/
https://en.cppreference.com/w/cpp/iterator/size
std::string_view
A typical implementation holds only two members: a pointer to constant CharT and a size. Several typedefs for common character types are provided:
// std::basic_string_view<char> == std::string_view
template<
class CharT,
class Traits = std::char_traits<CharT>
> class basic_string_view;
It is the programmer’s responsibility to ensure that std::string_view does not outlive the pointed-to character array:
std::string_view good{"a string literal"};
// "Good" case: `good` points to a static array (string literals are usually
// resided in persistent data segments).
std::string_view bad{"a temporary string"s};
// "Bad" case: `bad` holds a dangling pointer since the std::string temporary,
// created by std::operator""s, will be destroyed at the end of the statement.
#include <iostream>
#include <string>
#include <string_view>
#include <iomanip> // std::quoted
int main()
{
char array[3] = {'B', 'a', 'r'};
// constexpr basic_string_view( const CharT* s, size_type count )
std::string_view array_v(array, std::size(array));
std::cout << "array_v: " << std::quoted( array_v ) << '\n';
std::string cppstr = "Foo";
// constexpr basic_string_view( const CharT* s )
std::string_view cppstr_v(cppstr);
std::cout << "cppstr_v: " << std::quoted( cppstr_v ) << '\n';
const char* s = "hello";
std::string_view s_v(s);
std::cout << "s_v: " << std::quoted( s_v ) << '\n';
}
/*
array_v: "Bar"
cppstr_v: "Foo"
s_v: "hello"
*/
- https://en.cppreference.com/w/cpp/string/basic_string_view
std::variant_alternative_t
Provides compile-time indexed access to the types of the alternatives of the possibly cv-qualified variant, combining cv-qualifications of the variant (if any) with the cv-qualifications of the alternative.
// Helper template alias
template <size_t I, class T>
using variant_alternative_t = typename variant_alternative<I, T>::type;
#include <variant>
#include <iostream>
using my_variant = std::variant<int, float>;
static_assert(std::is_same_v<int, std::variant_alternative_t<0, my_variant>>);
static_assert(std::is_same_v<float, std::variant_alternative_t<1, my_variant>>);
// cv-qualification on the variant type propagates to the extracted alternative type.
static_assert(std::is_same_v<const int, std::variant_alternative_t<0, const my_variant>>);
int main()
{
std::cout << "All static assertions passed.\n";
}
/*
All static assertions passed.
*/
- https://en.cppreference.com/w/cpp/utility/variant/variant_alternative
std::visit
Applies the visitor vis (a Callable that can be called with any combination of types from variants) to the variants vars.
// gcc 14.2
#include <iomanip>
#include <iostream>
#include <string>
#include <type_traits>
#include <variant>
#include <vector>
// the variant to visit
using var_t = std::variant<int, long, double, std::string>;
// helper type for the visitor #4
template<class... Ts>
struct overloaded : Ts... { using Ts::operator()...; };
// explicit deduction guide (not needed as of C++20)
template<class... Ts>
overloaded(Ts...) -> overloaded<Ts...>;
int main()
{
std::vector<var_t> vec = {10, 15l, 1.5, "hello"};
for (auto& v: vec)
{
// 1. void visitor, only called for side-effects (here, for I/O)
std::visit([](auto&& arg){ std::cout << arg; }, v);
// 2. value-returning visitor, demonstrates the idiom of returning another variant
var_t w = std::visit([](auto&& arg) -> var_t { return arg + arg; }, v);
// 3. type-matching visitor: a lambda that handles each type differently
std::cout << ". After doubling, variant holds ";
std::visit([](auto&& arg)
{
using T = std::decay_t<decltype(arg)>;
if constexpr (std::is_same_v<T, int>)
std::cout << "int with value " << arg << '\n';
else if constexpr (std::is_same_v<T, long>)
std::cout << "long with value " << arg << '\n';
else if constexpr (std::is_same_v<T, double>)
std::cout << "double with value " << arg << '\n';
else if constexpr (std::is_same_v<T, std::string>)
std::cout << "std::string with value " << std::quoted(arg) << '\n';
else
static_assert(false, "non-exhaustive visitor!");
}, w);
}
for (auto& v: vec)
{
// 4. another type-matching visitor: a class with 3 overloaded operator()'s
// Note: The `(auto arg)` template operator() will bind to `int` and `long`
// in this case, but in its absence the `(double arg)` operator()
// *will also* bind to `int` and `long` because both are implicitly
// convertible to double. When using this form, care has to be taken
// that implicit conversions are handled correctly.
std::visit(overloaded{
[](auto arg) { std::cout << arg << ' '; },
[](double arg) { std::cout << std::fixed << arg << ' '; },
[](const std::string& arg) { std::cout << std::quoted(arg) << ' '; }
}, v);
}
}
/*
10. After doubling, variant holds int with value 20
15. After doubling, variant holds long with value 30
1.5. After doubling, variant holds double with value 3
hello. After doubling, variant holds std::string with value "hellohello"
10 15 1.500000 "hello"
*/
- https://en.cppreference.com/w/cpp/utility/variant/visit
maybe_unused
#include <cassert>
[[maybe_unused]] void f([[maybe_unused]] bool thing1,
[[maybe_unused]] bool thing2)
{
[[maybe_unused]] bool b = thing1 && thing2;
assert(b); // in release mode, assert is compiled out, and b is unused
// no warning because it is declared [[maybe_unused]]
} // parameters thing1 and thing2 are not used, no warning
int main() {;}
- https://en.cppreference.com/w/cpp/language/attributes/maybe_unused
C++20
std::source_location
The source_location class represents certain information about the source code, such as file names, line numbers, and function names. Previously, functions that desire to obtain this information about the call site (for logging, testing, or debugging purposes) must use macros so that predefined macros like __LINE__ and __FILE__ are expanded in the context of the caller. The source_location class provides a better alternative.
gcc 11.1.0
#include <iostream>
#include <string_view>
#include <source_location>
void log(const std::string_view message,
const std::source_location location =
std::source_location::current())
{
std::cout << "file: "
<< location.file_name() << "("
<< location.line() << ":"
<< location.column() << ") `"
<< location.function_name() << "`: "
<< message << '\n';
}
template <typename T> void fun(T x)
{
log(x);
}
int main(int, char*[])
{
log("Hello world!");
fun("Hello C++20!");
}
/*
file: prog.cc(24:8) `int main(int, char**)`: Hello world!
file: prog.cc(19:8) `void fun(T) [with T = const char*]`: Hello C++20!
*/
- https://en.cppreference.com/w/cpp/utility/source_location
Text formatting
#include <format>
#include <iostream>
#include <string>
#include <string_view>
template <typename... Args>
std::string dyna_print(std::string_view rt_fmt_str, Args&&... args) {
return std::vformat(rt_fmt_str, std::make_format_args(args...));
}
int main() {
std::cout << std::format("Hello {}!\n", "world");
std::string fmt;
for (int i{}; i != 3; ++i) {
fmt += "{} "; // constructs the formatting string
std::cout << fmt << " : ";
std::cout << dyna_print(fmt, "alpha", 'Z', 3.14, "unused");
std::cout << '\n';
}
}
/*
Hello world!
{} : alpha
{} {} : alpha Z
{} {} {} : alpha Z 3.14
*/
- https://en.cppreference.com/w/cpp/utility/format
- https://github.com/fmtlib/fmt
C++23
std::flat_map
flat_map 是一种关联容器适配器,它提供了包含唯一键的键值对的关联容器功能。键使用比较函数 Compare 进行排序。
flat_map 类模板作为两个底层容器(分别为类型 KeyContainer 和 MappedContainer)的包装器。第一个容器是有序的,对于每个键,其对应的值在第二个容器中具有相同的索引(偏移量)。两个容器中的元素数量相同。
flat_map 的使用场景:
- 数据量较小:由于 flat_map 底层使用两个连续存储的容器(通常为 vector)存储键和值,因此在数据量较小的情况下,其插入、删除和查找性能相对较好。但是,当数据量较大时,插入和删除操作的性能可能会降低,因为需要移动大量元素以保持容器的有序性。
- 高缓存局部性:由于 flat_map 使用连续存储的容器,其缓存局部性较好,这有助于提高查找性能。在需要频繁查找的场景中,flat_map 可能比其他关联容器(如 std::map)更高效。
- 空间效率:flat_map 通常比其他关联容器(如 std::map)更节省空间,因为它不需要为每个节点分配额外的内存以维护树结构。
需要注意的是,flat_map 通常不适用于需要频繁插入和删除操作的场景,特别是当数据量较大时。在这种情况下,可以考虑使用其他关联容器,如 std::map 或 std::unordered_map。
https://en.cppreference.com/w/cpp/container/flat_map
std::unordered_map
- https://en.cppreference.com/w/cpp/container/unordered_map
- C++ unordered_map using a custom class type as the key
- Quick and Simple Hash Code Combinations
To be able to use std::unordered_map (or one of the other unordered associative containers) with a user-defined key-type, you need to define two things:
- A hash function; this must be a class that overrides
operator()and calculates the hash value given an object of thekey-type. One particularly straight-forward way of doing this is to specialize thestd::hashtemplate for yourkey-type. - A comparison function for equality; this is required because the hash cannot rely on the fact that the hash function will always provide a unique hash value for every distinct key (i.e., it needs to be able to deal with collisions), so it needs a way to compare two given keys for an exact match. You can implement this either as a class that overrides
operator(), or as a specialization ofstd::equal, or - easiest of all - by overloadingoperator==()for your key type (as you did already).
The difficulty with the hash function is that if your key type consists of several members, you will usually have the hash function calculate hash values for the individual members, and then somehow combine them into one hash value for the entire object. For good performance (i.e., few collisions) you should think carefully about how to combine the individual hash values to ensure you avoid getting the same output for different objects too often.
A fairly good starting point for a hash function is one that uses bit shifting and bitwise XOR to combine the individual hash values. For example, assuming a key-type like this:
struct Key
{
std::string first;
std::string second;
int third;
bool operator==(const Key &other) const
{ return (first == other.first
&& second == other.second
&& third == other.third);
}
};
Here is a simple hash function (adapted from the one used in the cppreference example for user-defined hash functions):
template <>
struct std::hash<Key>
{
std::size_t operator()(const Key& k) const
{
using std::size_t;
using std::hash;
using std::string;
// Compute individual hash values for first,
// second and third and combine them using XOR
// and bit shifting:
return ((hash<string>()(k.first)
^ (hash<string>()(k.second) << 1)) >> 1)
^ (hash<int>()(k.third) << 1);
}
};
With this in place, you can instantiate a std::unordered_map for the key-type:
int main()
{
std::unordered_map<Key,std::string> m6 = {
{ {"John", "Doe", 12}, "example"},
{ {"Mary", "Sue", 21}, "another"}
};
}
It will automatically use std::hash<Key> as defined above for the hash value calculations, and the operator== defined as member function of Key for equality checks.
If you don’t want to specialize template inside the std namespace (although it’s perfectly legal in this case), you can define the hash function as a separate class and add it to the template argument list for the map:
struct KeyHasher
{
std::size_t operator()(const Key& k) const
{
using std::size_t;
using std::hash;
using std::string;
return ((hash<string>()(k.first)
^ (hash<string>()(k.second) << 1)) >> 1)
^ (hash<int>()(k.third) << 1);
}
};
int main()
{
std::unordered_map<Key,std::string,KeyHasher> m6 = {
{ {"John", "Doe", 12}, "example"},
{ {"Mary", "Sue", 21}, "another"}
};
}
How to define a better hash function? As said above, defining a good hash function is important to avoid collisions and get good performance. For a real good one you need to take into account the distribution of possible values of all fields and define a hash function that projects that distribution to a space of possible results as wide and evenly distributed as possible.
This can be difficult; the XOR/bit-shifting method above is probably not a bad start. For a slightly better start, you may use the hash_value and hash_combine function template from the Boost library. The former acts in a similar way as std::hash for standard types (recently also including tuples and other useful standard types); the latter helps you combine individual hash values into one. Here is a rewrite of the hash function that uses the Boost helper functions:
#include <boost/functional/hash.hpp>
struct KeyHasher
{
std::size_t operator()(const Key& k) const
{
using boost::hash_value;
using boost::hash_combine;
// Start with a hash value of 0 .
std::size_t seed = 0;
// Modify 'seed' by XORing and bit-shifting in
// one member of 'Key' after the other:
hash_combine(seed,hash_value(k.first));
hash_combine(seed,hash_value(k.second));
hash_combine(seed,hash_value(k.third));
// Return the result.
return seed;
}
};
And here’s a rewrite that doesn’t use boost, yet uses good method of combining the hashes:
template <>
struct std::hash<Key>
{
std::size_t operator()( const Key& k ) const
{
// Compute individual hash values for first, second and third
// http://stackoverflow.com/a/1646913/126995
std::size_t res = 17;
res = res * 31 + hash<string>()( k.first );
res = res * 31 + hash<string>()( k.second );
res = res * 31 + hash<int>()( k.third );
return res;
}
};
Algorithm
std::find / std::find_if / std::find_if_not
findsearches for an element equal to value (using operator==)find_ifsearches for an element for which predicate p returns truefind_if_notsearches for an element for which predicate q returns false
#include <iostream>
#include <algorithm>
#include <vector>
#include <iterator>
int main()
{
std::vector<int> v{1, 2, 3, 4};
int n1 = 3;
int n2 = 5;
auto is_even = [](int i){ return i%2 == 0; };
auto result1 = std::find(begin(v), end(v), n1);
auto result2 = std::find(begin(v), end(v), n2);
auto result3 = std::find_if(begin(v), end(v), is_even);
(result1 != std::end(v))
? std::cout << "v contains " << n1 << '\n'
: std::cout << "v does not contain " << n1 << '\n';
(result2 != std::end(v))
? std::cout << "v contains " << n2 << '\n'
: std::cout << "v does not contain " << n2 << '\n';
(result3 != std::end(v))
? std::cout << "v contains an even number: " << *result3 << '\n'
: std::cout << "v does not contain even numbers\n";
}
/*
v contains 3
v does not contain 5
v contains an even number: 2
*/
std::any_of / std::all_of / std::none_of
#include <iostream>
#include <vector>
#include <algorithm>
int main()
{
std::vector<int> v{1, 2, 3, 4};
std::cout << std::any_of(v.cbegin(), v.cend(), [&](int i) { if (i > 3) {return true;} return false; }) << std::endl; // 1 任意一个大于 3
std::cout << std::all_of(v.cbegin(), v.cend(), [&](int i) { if (i > 0) {return true;} return false; }) << std::endl; // 1 全部大于 0
std::cout << std::none_of(v.cbegin(), v.cend(), [&](int i) { if (i > 0) {return true;} return false; }) << std::endl; // 0 没有一个大于 0
}
https://en.cppreference.com/w/cpp/algorithm/all_any_none_of
std::lower_bound (下界)
template< class ForwardIt, class T >
ForwardIt lower_bound( ForwardIt first, ForwardIt last, const T& value );
template< class ForwardIt, class T, class Compare >
ForwardIt lower_bound( ForwardIt first, ForwardIt last, const T& value, Compare comp );
Returns an iterator pointing to the first element in the range [first, last) that is not less than (i.e. greater or equal to) value, or last if no such element is found.
[frist, last]顺序为非严格递增- 顺序:
value <= [frist, last]
#include <algorithm>
#include <iostream>
#include <vector>
struct PriceInfo { double price; };
int main()
{
const std::vector<int> data = { 1, 2, 4, 5, 5, 6 };
for (int i = 0; i < 8; ++i) {
// Search for first element x such that i ≤ x
auto lower = std::lower_bound(data.begin(), data.end(), i);
std::cout << i << " ≤ ";
lower != data.end()
? std::cout << *lower << " at index " << std::distance(data.begin(), lower)
: std::cout << "[not found]";
std::cout << '\n';
}
std::vector<PriceInfo> prices = { {100.0}, {101.5}, {102.5}, {102.5}, {107.3} };
for(double to_find: {102.5, 110.2}) {
auto prc_info = std::lower_bound(prices.begin(), prices.end(), to_find,
[](const PriceInfo& info, double value){
return info.price < value;
});
prc_info != prices.end()
? std::cout << prc_info->price << " at index " << prc_info - prices.begin()
: std::cout << to_find << " not found";
std::cout << '\n';
}
}
/*
0 ≤ 1 at index 0
1 ≤ 1 at index 0
2 ≤ 2 at index 1
3 ≤ 4 at index 2
4 ≤ 4 at index 2
5 ≤ 5 at index 3
6 ≤ 6 at index 5
7 ≤ [not found]
102.5 at index 2
110.2 not found
*/
#include <algorithm>
#include <iostream>
#include <vector>
struct Comparer
{
inline bool operator()(const int a, const int b) const
{
//return a < b; // 从小到大
return a > b; // 从大到小
}
};
int main()
{
Comparer cmp;
const std::vector<int> data = { 2,
3,
4
};
int i = 1;
auto lower = std::lower_bound(data.begin(), data.end(), i, cmp);
if (lower != data.end())
{
std::cout << "ok\n";
}
else
{
std::cout << "end\n";
}
}
- https://www.cplusplus.com/reference/algorithm/lower_bound/
std::upper_bound (上界)
Returns an iterator pointing to the first element in the range [first, last) that is greater than value, or last if no such element is found.
[frist, last]顺序为非严格递增- 顺序:
[frist, last] <= value
#include <algorithm>
#include <iostream>
#include <vector>
struct PriceInfo { double price; };
int main()
{
const std::vector<int> data = { 1, 2, 4, 5, 5, 6 };
for (int i = 0; i < 7; ++i) {
// Search first element that is greater than i
auto upper = std::upper_bound(data.begin(), data.end(), i);
std::cout << i << " < ";
upper != data.end()
? std::cout << *upper << " at index " << std::distance(data.begin(), upper)
: std::cout << "not found";
std::cout << '\n';
}
std::vector<PriceInfo> prices = { {100.0}, {101.5}, {102.5}, {102.5}, {107.3} };
for(double to_find: {102.5, 110.2}) {
auto prc_info = std::upper_bound(prices.begin(), prices.end(), to_find,
[](double value, const PriceInfo& info){
return value < info.price;
});
prc_info != prices.end()
? std::cout << prc_info->price << " at index " << prc_info - prices.begin()
: std::cout << to_find << " not found";
std::cout << '\n';
}
}
/*
0 < 1 at index 0
1 < 2 at index 1
2 < 4 at index 2
3 < 4 at index 2
4 < 5 at index 3
5 < 6 at index 5
6 < not found
107.3 at index 4
110.2 not found
*/
- https://en.cppreference.com/w/cpp/algorithm/upper_bound
std::partition
Reorders the elements in the range [first, last) in such a way that all elements for which the predicate p returns true precede the elements for which predicate p returns false. Relative order of the elements is not preserved.
#include <algorithm>
#include <iostream>
#include <iterator>
#include <vector>
#include <forward_list>
template <class ForwardIt>
void quicksort(ForwardIt first, ForwardIt last)
{
if(first == last) return;
auto pivot = *std::next(first, std::distance(first,last)/2);
ForwardIt middle1 = std::partition(first, last,
[pivot](const auto& em){ return em < pivot; });
ForwardIt middle2 = std::partition(middle1, last,
[pivot](const auto& em){ return !(pivot < em); });
quicksort(first, middle1);
quicksort(middle2, last);
}
int main()
{
std::vector<int> v = {0,1,2,3,4,5,6,7,8,9};
std::cout << "Original vector:\n ";
for(int elem : v) std::cout << elem << ' ';
auto it = std::partition(v.begin(), v.end(), [](int i){return i % 2 == 0;});
std::cout << "\nPartitioned vector:\n ";
std::copy(std::begin(v), it, std::ostream_iterator<int>(std::cout, " "));
std::cout << " * " " ";
std::copy(it, std::end(v), std::ostream_iterator<int>(std::cout, " "));
std::forward_list<int> fl = {1, 30, -4, 3, 5, -4, 1, 6, -8, 2, -5, 64, 1, 92};
std::cout << "\nUnsorted list:\n ";
for(int n : fl) std::cout << n << ' ';
std::cout << '\n';
quicksort(std::begin(fl), std::end(fl));
std::cout << "Sorted using quicksort:\n ";
for(int fi : fl) std::cout << fi << ' ';
std::cout << '\n';
}
/*
Original vector:
0 1 2 3 4 5 6 7 8 9
Partitioned vector:
0 8 2 6 4 * 5 3 7 1 9
Unsorted list:
1 30 -4 3 5 -4 1 6 -8 2 -5 64 1 92
Sorted using quicksort:
-8 -5 -4 -4 1 1 1 2 3 5 6 30 64 92
*/
- https://en.cppreference.com/w/cpp/algorithm/partition
Others
Alignment and Bit Fields
offsetof (macro)
#define offsetof(type, member) /*implementation-defined*/
#include <iostream>
#include <cstddef>
struct S {
char m0;
double m1;
short m2;
char m3;
// private: int z; // warning: 'S' is a non-standard-layout type
};
int main()
{
std::cout
<< "offset of char m0 = " << offsetof(S, m0) << '\n'
<< "offset of double m1 = " << offsetof(S, m1) << '\n'
<< "offset of short m2 = " << offsetof(S, m2) << '\n'
<< "offset of char m3 = " << offsetof(S, m3) << '\n';
}
/*
offset of char m0 = 0
offset of double m1 = 8
offset of short m2 = 16
offset of char m3 = 18
*/
aligned_alloc
#include <stdlib.h>
void *aligned_alloc( size_t alignment, size_t size ); // since C11
Allocate size bytes of uninitialized storage whose alignment is specified by alignment. The size parameter must be an integral multiple of alignment.
aligned_alloc is thread-safe: it behaves as though only accessing the memory locations visible through its argument, and not any static storage.
Parameters
alignment- specifies the alignment. Must be a valid alignment supported by the implementation.size- number of bytes to allocate. An integral multiple of alignment
Return value
On success, returns the pointer to the beginning of newly allocated memory. To avoid a memory leak, the returned pointer must be deallocated with free or realloc.
On failure, returns a null pointer.
Example
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
int *p1 = malloc(10*sizeof *p1);
printf("default-aligned addr: %p\n", (void*)p1);
free(p1);
int *p2 = aligned_alloc(1024, 1024*sizeof *p2);
printf("1024-byte aligned addr: %p\n", (void*)p2);
free(p2);
}
Possible output:
default-aligned addr: 0x1e40c20
1024-byte aligned addr: 0x1e41000
operator«
#include <iostream>
#include <string>
#include <vector>
template<typename T>
std::ostream& operator<<(std::ostream& os, const std::vector<T>& vec)
{
for (auto& el : vec)
{
os << el << ' ';
}
return os;
}
int main()
{
std::vector<std::string> vec = {
"Hello", "from", "GCC", __VERSION__, "!"
};
std::cout << vec << std::endl;
}
Unsigned overflow
问题示例,unsigned 类型的 overflow 属于合法的 wraparound。
#include<iostream>
int main()
{
uint32_t j = 257;
for (uint8_t i = 0; i != j; ++i) {
std::cout << "a\n";
}
}
How to obtain warning for forgotten cast in arithmetic?
Unfortunately GCC only supports -fsanitize=signed-integer-overflow. There’s no unsigned version. refer: GCC Instrumentation-Options
How to get a warning in GCC for unsigned integer overflow instead of wrap-around?
gethostbyname
#include <stdio.h>
#include <netdb.h>
int main()
{
struct hostent *lh = gethostbyname("localhost");
if (lh) {
puts(lh->h_name);
printf("%u.%u.%u.%u\n", lh->h_addr_list[0][0],
lh->h_addr_list[0][1],
lh->h_addr_list[0][2],
lh->h_addr_list[0][3]);
} else {
herror("gethostbyname");
}
}
/*
localhost
127.0.0.1
*/
https://man7.org/linux/man-pages/man3/gethostbyname.3.html
What is time_t ultimately a typedef to?
Although not defined by the C standard, this is almost always an integral value holding the number of seconds (not counting leap seconds) since 00:00, Jan 1 1970 UTC, corresponding to POSIX time.
#include <stdio.h>
#include <time.h>
#include <stdint.h>
int main(void)
{
time_t epoch = 0;
printf("%jd seconds since the epoch began\n", (intmax_t)epoch);
printf("%s", asctime(gmtime(&epoch)));
}
/*
0 seconds since the epoch began
Thu Jan 1 00:00:00 1970
*/
The time_t datatype is a data type in the ISO C library defined for storing system time values. Such values are returned from the standard time() library function. This type is a typedef defined in the standard header. ISO C defines time_t as an arithmetic type, but does not specify any particular type, range, resolution, or encoding for it. Also unspecified are the meanings of arithmetic operations applied to time values.
Unix and POSIX-compliant systems implement the time_t type as a signed integer (typically 32 or 64 bits wide) which represents the number of seconds since the start of the Unix epoch: midnight UTC of January 1, 1970 (not counting leap seconds). Some systems correctly handle negative time values, while others do not. Systems using a 32-bit time_t type are susceptible to the Year 2038 problem.
#include <time.h>
int main(int argc, char** argv)
{
time_t test;
return 0;
}
/*
gcc -E time.c | grep __time_t
typedef long int __time_t;
*/
- https://en.cppreference.com/w/c/chrono/time_t
- https://stackoverflow.com/questions/471248/what-is-time-t-ultimately-a-typedef-to
Copy elision
Omits copy and move (since C++11) constructors, resulting in zero-copy pass-by-value semantics.
TODO
- https://en.cppreference.com/w/cpp/language/copy_elision
Zero initialization
TL;DR: Use the initializer - it’s never worse than memset().
It depends on your compiler. It shouldn’t be any slower than calling memset() (because calling memset() is one option available to the compiler).
The initializer is easier to read than imperatively overwriting the array; it also adapts well if the element type is changed to something where all-bit-zero isn’t what you want.
#include <string.h>
int f1()
{
int a[32] = {0};
return a[31];
}
int f2()
{
int a[32];
memset(a, 0, sizeof a);
return a[31];
}
- https://en.cppreference.com/w/cpp/language/zero_initialization
- https://en.cppreference.com/w/c/language/struct_initialization
- https://en.cppreference.com/w/cpp/language/default_initialization
- Are zero initializers faster than memset?
Argument-dependent lookup (ADL)
Argument-dependent lookup, also known as ADL, or Koenig lookup, is the set of rules for looking up the unqualified function names in function-call expressions, including implicit function calls to overloaded operators. These function names are looked up in the namespaces of their arguments in addition to the scopes and namespaces considered by the usual unqualified name lookup.
Argument-dependent lookup makes it possible to use operators defined in a different namespace. Example:
#include <iostream>
int main()
{
std::cout << "Test\n"; // There is no operator<< in global namespace, but ADL
// examines std namespace because the left argument is in
// std and finds std::operator<<(std::ostream&, const char*)
operator<<(std::cout, "Test\n"); // same, using function call notation
// however,
std::cout << endl; // Error: 'endl' is not declared in this namespace.
// This is not a function call to endl(), so ADL does not apply
endl(std::cout); // OK: this is a function call: ADL examines std namespace
// because the argument of endl is in std, and finds std::endl
(endl)(std::cout); // Error: 'endl' is not declared in this namespace.
// The sub-expression (endl) is not a function call expression
}
- https://en.cppreference.com/w/cpp/language/adl
Name lookup
Name lookup is the procedure by which a name, when encountered in a program, is associated with the declaration that introduced it.
For example, to compile std::cout << std::endl;, the compiler performs:
- unqualified name lookup for the name
std, which finds the declaration of namespacestdin the header<iostream> - qualified name lookup for the name
cout, which finds a variable declaration in the namespacestd - qualified name lookup for the name
endl, which finds a function template declaration in the namespacestd - both argument-dependent lookup for the name
operator<<which finds multiple function template declarations in the namespacestdand qualified name lookup for the namestd::ostream::operator<<which finds multiple member function declarations in classstd::ostream.
- https://en.cppreference.com/w/cpp/language/lookup
Types of lookup
If the name appears immediately to the right of the scope resolution operator :: or possibly after :: followed by the disambiguating keyword template, see Qualified name lookup. Otherwise, see Unqualified name lookup (which, for function names, includes Argument-dependent lookup)
Qualified name lookup (限定名查找)
A qualified name is a name that appears on the right hand side of the scope resolution operator :: (see also qualified identifiers). A qualified name may refer to a
- class member (including static and non-static functions, types, templates, etc)
- namespace member (including another namespace)
- enumerator
If there is nothing on the left hand side of the ::, the lookup considers only declarations made in the global namespace scope (or introduced into the global namespace by a using declaration). This makes it possible to refer to such names even if they were hidden by a local declaration:
#include <iostream>
int main()
{
struct std {};
std::cout << "fail\n"; // Error: unqualified lookup for 'std' finds the struct
::std::cout << "ok\n"; // OK: ::std finds the namespace std
}
Unqualified name lookup (无限定名查找)
For an unqualified name, that is a name that does not appear to the right of a scope resolution operator ::, name lookup examines the scopes as described below, until it finds at least one declaration of any kind, at which time the lookup stops and no further scopes are examined. (Note: lookup from some contexts skips some declarations, for example, lookup of the name used to the left of :: ignores function, variable, and enumerator declarations, lookup of a name used as a base class specifier ignores all non-type declarations)
- https://en.cppreference.com/w/cpp/language/lookup
Dependent names
问题:
#include <iostream>
void g(double) { std::cout << "g(double)\n"; }
template<class T>
struct S
{
void f(T t) const
{
g(t); // bound now ?
}
};
void g(int) { std::cout << "g(int)\n"; }
int main()
{
g(2); // g(int)
S<int> s;
s.f(2); // g(double). why?
}
使用ADL:
#include <iostream>
class A // 没有命名空间
{
};
void g(double) { std::cout << "g(double)\n"; }
template<class T>
struct S
{
void f(T t) const
{
g(t);
}
};
void g(int) { std::cout << "g(int)\n"; }
void g(A&) { std::cout << "g(A&)\n"; }
int main()
{
g(2); // g(int)
S<int> s1;
s1.f(2); // g(double). no use ADL
S<A> s2;
A a;
s2.f(a); // g(A&). use ADL
}
当使用命名空间后,ADL好像没办法生效
#include <iostream>
namespace t // 使用命名空间
{
class A
{
};
}
void g(double) { std::cout << "g(double)\n"; }
void g(t::A&) { std::cout << "g(A&)\n"; }. // 添加了命名空间后,必现在模版定义前声明
template<class T>
struct S
{
void f(T t) const
{
g(t);
}
};
void g(int) { std::cout << "g(int)\n"; }
int main()
{
g(2); // g(int)
S<int> s1;
s1.f(2); // g(double). no use ADL
S<t::A> s2;
t::A a;
s2.f(a); // g(A&). 添加了命名空间后,必现在模版定义前声明
}
Inside the definition of a template (both class template and function template), the meaning of some constructs may differ from one instantiation to another. In particular, types and expressions may depend on types of type template parameters and values of non-type template parameters.
template<typename T>
struct X : B<T> // "B<T>" is dependent on T
{
typename T::A* pa; // "T::A" is dependent on T
// (see below for the meaning of this use of "typename")
void f(B<T>* pb)
{
static int i = B<T>::i; // "B<T>::i" is dependent on T
pb->j++; // "pb->j" is dependent on T
}
};
Name lookup and binding are different for dependent names and non-dependent names
Binding rules
Non-dependent names are looked up and bound at the point of template definition. This binding holds even if at the point of template instantiation there is a better match:
#include <iostream>
void g(double) { std::cout << "g(double)\n"; }
template<class T>
struct S
{
void f() const
{
g(1); // "g" is a non-dependent name, bound now
}
};
void g(int) { std::cout << "g(int)\n"; }
int main()
{
g(1); // calls g(int)
S<int> s;
s.f(); // calls g(double)
}
Binding of dependent names is postponed until lookup takes place.
As discussed in lookup, the lookup of a dependent name used in a template is postponed until the template arguments are known, at which time
- non-ADL lookup examines function declarations with external linkage that are visible from the template definition context
- ADL examines function declarations with external linkage that are visible from either the template definition context or the template instantiation context
in other words, adding a new function declaration after template definition does not make it visible, except via ADL. The purpose of this rule is to help guard against violations of the ODR for template instantiations
To make ADL examine a user-defined namespace, either std::vector should be replaced by a user-defined class or its element type should be a user-defined class.
- https://en.cppreference.com/w/cpp/language/dependent_name
- https://stackoverflow.com/questions/64823299/why-doesnt-adl-work-with-functions-defined-outside-of-a-namespace
Difference between auto and auto* when storing a pointer
int main()
{
int a = 1;
int* pa = &a;
auto pa2 = pa; // ok, non-const
//auto* pa2 = pa; // ok, non-const
//const auto* pa2 = pa; // ok, const
std::cout << *pa2; // 1
}
- https://stackoverflow.com/questions/12773257/does-auto-type-assignments-of-a-pointer-in-c11-require
- https://stackoverflow.com/questions/36211703/difference-between-auto-and-auto-when-storing-a-pointer
What’s the difference between constexpr and const?
What’s the difference between constexpr and const?
- When can I use only one of them?
- When can I use both and how should I choose one?
constexpr creates a compile-time constant; const simply means that value cannot be changed.
Both keywords can be used in the declaration of objects as well as functions. The basic difference when applied to objects is this:
-
constdeclares an object as constant. This implies a guarantee that once initialized, the value of that object won’t change, and the compiler can make use of this fact for optimizations. It also helps prevent the programmer from writing code that modifies objects that were not meant to be modified after initialization. -
constexprdeclares an object as fit for use in what the Standard calls constant expressions. But note thatconstexpris not the only way to do this.
refer:
- https://stackoverflow.com/questions/14116003/whats-the-difference-between-constexpr-and-const?rq=1
- https://en.cppreference.com/w/cpp/language/constexpr
- https://www.zhihu.com/question/35614219
Color print
#include <cstdio>
#define kColorNrm "\x1B[0m"
#define kColorRed "\x1B[31m"
#define kColorGrn "\x1B[32m"
#define kColorYel "\x1B[33m"
#define kColorBlu "\x1B[34m"
int main()
{
printf(kColorRed"abc\n"kColorNrm);
printf("abc\n");
printf(kColorGrn"abc\n"kColorNrm);
printf("abc\n");
printf(kColorYel"abc\n"kColorNrm);
printf("abc\n");
printf(kColorBlue"abc\n"kColorNrm);
printf("abc\n");
}
- https://stackoverflow.com/questions/5412761/using-colors-with-printf
Printf alignment
printf("%-32s%-32s\n", "Type", "123");
printf("%-32s%-32s\n", "Name", "456789");
And then whatever’s printed with that field will be blank-padded to the width you indicate. The - left-justifies your text in that field.
- https://stackoverflow.com/questions/1809399/how-to-format-strings-using-printf-to-get-equal-length-in-the-output
- https://stackoverflow.com/questions/2485963/c-alignment-when-printing-cout
_attribute__ ((format (printf, 2, 3)))
The format attribute allows you to identify your own functions that take format strings as arguments, so that GCC can check the calls to these functions for errors.
format (archetype, string-index, first-to-check)
The format attribute specifies that a function takes printf, scanf, strftime or strfmon style arguments that should be type-checked against a format string. For example, the declaration:
extern int
my_printf (void *my_object, const char *my_format, ...) __attribute__ ((format (printf, 2, 3)));
causes the compiler to check the arguments in calls to my_printf for consistency with the printf style format string argument my_format.
The parameter archetype determines how the format string is interpreted, and should be printf, scanf, strftime, gnu_printf, gnu_scanf, gnu_strftime or strfmon.
The parameter string-index specifies which argument is the format string argument (starting from 1), while first-to-check is the number of the first argument to check against the format string.
For functions where the arguments are not available to be checked (such as vprintf), specify the third parameter as zero. In this case the compiler only checks the format string for consistency. For strftime formats, the third parameter is required to be zero. Since non-static C++ methods have an implicit this argument, the arguments of such methods should be counted from two, not one, when giving values for string-index and first-to-check.
In the example above, the format string (my_format) is the second argument of the function my_print, and the arguments to check start with the third argument, so the correct parameters for the format attribute are 2 and 3.
使用示例:
#include <cstdio>
#include <cstdarg>
__attribute__ ((format (printf, 1, 2))) void func(const char *fmt, ...)
{
va_list argptr;
va_start(argptr, fmt);
printf("fmt(%s)\n", fmt);
va_end(argptr);
}
int main()
{
long long a = 1; // if use int a = 1; will be ok
char b = '2';
func("a=%d&b=%c", a, b);
}
clang++ prog.cc -Wall -Wextra -I/opt/wandbox/boost-1.75.0-clang-7.1.0/include -std=gnu++11
prog.cc:17:27: warning: format specifies type 'int' but the argument has type 'long long' [-Wformat]
func("a=%d&b=%c", a, b);
~~ ^
%lld
1 warning generated.
fmt(a=%d&b=%c)
在类中使用:
#include <cstdio>
#include <cstdarg>
struct Foo
{
// static func
__attribute__ ((format (printf, 1, 2))) static void func(const char *fmt, ...) // 类的静态函数不包含 this 指针,所以和普通函数用法一样
{
va_list argptr;
va_start(argptr, fmt);
printf("fmt(%s)\n", fmt);
va_end(argptr);
}
};
int main()
{
long long a = 1; // warning: format '%d' expects argument of type 'int', but argument 2 has type 'long long int' [-Wformat=]
char b = '2';
Foo::func("a=%d&b=%c", a, b);
}
#include <cstdio>
#include <cstdarg>
struct Foo
{
// non-static
__attribute__ ((format (printf, 2, 3))) void func(const char *fmt, ...) // 类的普通成员函数第一个参数为隐式的 this 指针,也需要作为参数计数
{
va_list argptr;
va_start(argptr, fmt);
printf("fmt(%s)\n", fmt);
va_end(argptr);
}
};
int main()
{
long long a = 1; // warning: format '%d' expects argument of type 'int', but argument 2 has type 'long long int' [-Wformat=]
char b = '2';
Foo foo;
foo.func("a=%d&b=%c", a, b);
}
- How should I properly use attribute ((format (printf, x, y))) inside a class method in C++?
- https://gcc.gnu.org/onlinedocs/gcc-8.2.0/gcc/Common-Function-Attributes.html#Common-Function-Attributes
- https://gcc.gnu.org/onlinedocs/gcc/Common-Function-Attributes.html#Common-Function-Attributes
attribute((deprecated))
class foo {
public:
void my_func() __attribute__((deprecated)) {
}
void my_func2() __attribute__((noinline)) {
}
};
int main()
{
foo f;
f.my_func();
f.my_func2();
}
$ g++ -c -Wall -pedantic a.cpp
a.cpp: In function int main():
a.cpp:12:13: warning: void foo::my_func() is deprecated (declared at a.cpp:3) [-Wdeprecated-declarations]
#ifdef __GNUC__
#define DEPRECATED(func) func __attribute__ ((deprecated))
#elif defined(_MSC_VER)
#define DEPRECATED(func) __declspec(deprecated) func
#else
#pragma message("WARNING: You need to implement DEPRECATED for this compiler")
#define DEPRECATED(func) func
#endif
//don't use me any more
DEPRECATED(void OldFunc(int a, float b));
//use me instead
void NewFunc(int a, double b);
However, you will encounter problems if a function return type has a commas in its name e.g. std::pair<int, int> as this will be interpreted by the preprocesor as passing 2 arguments to the DEPRECATED macro. In that case you would have to typedef the return type.
- https://stackoverflow.com/questions/295120/c-mark-as-deprecated
空值类型转换
#include <iostream>
#include <string.h>
class A
{
public:
void test() { std::cout << "test\n"; }
};
int main()
{
auto a = (A*)10;
a->test(); // test
((A*)nullptr)->test(); // test
}
禁止函数内敛
更多参考:GCC/Clang Compilation Optimize
#include <iostream>
#include <string.h>
// clang
[[clang::optnone]] void Test1() { std::cout << "Test1\n"; }
// gcc
__attribute__((noinline)) void Test2() { std::cout << "Test2\n"; }
int main()
{
Test1();
Test2();
}
clang ignoring attribute noinline
多继承的指针偏移
#include <iostream>
struct A
{
int a1; // 4B
int a2; // 4B
};
struct B
{
int b;
};
struct C : public A, public B
{
int c;
};
int main()
{
printf("%p\n", (B*)(C*)1); // 多重继承时,对象 C 的地址 0x1 在进行类型转换 B 时,会偏移 A 的大小 = 0x1 + 4 + 4 = 0x9
}
#include <iostream>
struct A
{
int a;
};
struct B
{
int b;
};
struct C : public A, public B
{
int c;
};
int main()
{
C* pc = new C;
std::cout << "pc: " << pc << std::endl;;
B* pb = pc;
std::cout << "pb: " << pb << std::endl;
A* pa = pc;
std::cout << "pa: " << pa << std::endl;
}
/*
pc: 0xddff40
pb: 0xddff44
pa: 0xddff40
*/
delete-non-virtual-dtor warning
测试代码:
#include <iostream>
struct Foo
{
virtual void func() { }
};
struct Bar : public Foo
{
void func() override { }
};
int main()
{
Foo* f = new Bar;
f->func();
delete f;
}
编译选项:-std=c++11 -Wall
编译告警:
<source>:18:5: warning: delete called on non-final 'Foo' that has virtual functions but non-virtual destructor [-Wdelete-non-abstract-non-virtual-dtor]
delete f;
^
1 warning generated.
由于父类不是虚析构,因此在对象销毁时,只会调用父类的析构函数,而不会调用子类的析构函数。在父类定义中添加虚析构函数,可去除编译告警:
#include <iostream>
struct Foo
{
virtual void func() { }
virtual ~Foo() = default; // 在基类定义中添加虚析构函数
};
struct Bar : public Foo
{
void func() override { }
};
int main()
{
Foo* f = new Bar;
f->func();
delete f;
}
或者添加 final 去除告警:
#include <iostream>
struct Foo
{
virtual void doStuff() { }
//virtual ~Foo() = default;
};
struct Bar final : public Foo // 添加 final 去除告警
{
void doStuff() override { }
};
int main()
{
Bar* f = new Bar;
f->doStuff();
delete f;
}
参考 Bug 53596 - g++-4.7 -Wall shouldn’t complain for non-virtual protected dtor 中的例子:
#include <iostream>
class Base {
public:
virtual void foo() = 0;
protected:
~Base() { } // legal C++ code
};
class Derived : public Base {
public:
virtual void foo() { std::cout << "Derived::foo()" << std::endl; }
~Derived() { std::cout << "Derived::~Derived()" << std::endl; }
};
int main() {
Derived* derived = new Derived();
derived->foo();
delete derived; // legal, there must be no warning!
return 0;
}
问题:
g++-4.7 -Wall produces erronous -Wdelete-non-virtual-dtor warning
g++-4.7 shouldn’t complain for non-virtual protected dtor if the base class has virtual functions. Previous versions of g++ do not warn, other compilers (msvc /W4, sunCC +w2) do not warn.
解释:
The warning is valid, the fact Base is protected is irrelevant, you’re not using delete with a Base* operand.
Consider:
class MoreDerived : public Derived {
public:
~Derived() { std::cout << "MoreDerived::~MoreDerived()" << std::endl; }
};
int main() {
Derived* morederived = new MoreDerived();
morederived->foo();
delete morederived; // undefined behaviour
}
Now the warning is entirely correct, you are deleting a Derived* which is a polymorphic type without a virtual destructor, so the program has undefined behaviour. That’s substantially the same as your example, on the line:
delete derived;
the compiler doesn’t know that the Derived* points to a Derived or a MoreDerived, so it warns you it might cause undefined behaviour.
N.B. Clang (known for much better diagnostics than MSVC or Sun CC) also warns for your example.
“N.B.” means “nota bene” in Latin, which means “note well” (or “pay special attention to this”) in English.
The reason previous versions of GCC do not warn is because GCC has been improved and now issues a warning for unsafe code that it didn’t diagnose before. This is a good thing.
- Suppress delete-non-virtual-dtor warning when using a protected non-virtual destructor
- https://gcc.gnu.org/wiki/VerboseDiagnostics#delete-non-virtual-dtor
Static Members of a C++ Class
We can define class members static using static keyword. When we declare a member of a class as static it means no matter how many objects of the class are created, there is only one copy of the static member.
A static member is shared by all objects of the class. All static data is initialized to zero when the first object is created, if no other initialization is present. We can’t put it in the class definition but it can be initialized outside the class as done in the following example by redeclaring the static variable, using the scope resolution operator :: to identify which class it belongs to.
#include <iostream>
using namespace std;
class Box {
public:
static int objectCount;
// Constructor definition
Box(double l = 2.0, double b = 2.0, double h = 2.0) {
cout <<"Constructor called." << endl;
length = l;
breadth = b;
height = h;
// Increase every time object is created
objectCount++;
}
double Volume() {
return length * breadth * height;
}
static int getCount() {
return objectCount;
}
private:
double length; // Length of a box
double breadth; // Breadth of a box
double height; // Height of a box
};
// Initialize static member of class Box
int Box::objectCount = 0;
int main(void) {
// Print total number of objects before creating object.
cout << "Inital Stage Count: " << Box::getCount() << endl;
Box Box1(3.3, 1.2, 1.5); // Declare box1
Box Box2(8.5, 6.0, 2.0); // Declare box2
// Print total number of objects after creating object.
cout << "Final Stage Count: " << Box::getCount() << endl;
return 0;
}
- https://www.tutorialspoint.com/cplusplus/cpp_static_members.htm
inline
FAQ: How do you tell the compiler to make a member function inline?
When should I write the keyword ‘inline’ for a function/method?
数组传参
在C++中有了引用语法,可以把数组类型进行传递。
void f1(int (&arr)[5]) // 必须传 int[5] 类型
{
(void)arr;
}
int main()
{
int arr1[5];
int arr2[8];
f1(arr1); // ok
//f1(arr2); // err
}
一些新兴语言(例如 Go)注意到了这一点,因此将其进行了区分。在 Go 语言中,区分了“数组”和“切片”的概念,数组就是长度固定的,整体来传递;而切片则类似于首地址+长度的方式传递。
func f1(arr [5]int) {
}
func f2(arr []int) {
}
f1 就必须传递长度是5的数组类型,而 f2 则可以传递任意长度的切片类型。
而 C++ 其实也注意到了这一点,但由于兼容问题,它只能通过 STL 提供容器的方式来解决,std::array 就是定长数组,而 std::vector 就是变长数组,跟上述 Go 语言中的数组和切片的概念是基本类似的。这也是 C++ 中更加推荐使用 vector 而不是 C 风格数组的原因。
placement new
There are situations when we don’t want to rely upon Free Store for allocating memory and we want to use custom memory allocations using new. For these situations we can use Placement New, where we can tell `new’ operator to allocate memory from a pre-allocated memory location.
int a4byteInteger;
char *a4byteChar = new (&a4byteInteger) char[4];
In this example, the memory pointed by a4byteChar is 4 byte allocated to ‘stack’ via integer variable a4byteInteger.
The benefit of this kind of memory allocation is the fact that programmers control the allocation. In the example above, since a4byteInteger is allocated on stack, we don’t need to make an explicit call to delete a4byteChar.
Same behavior can be achieved for dynamic allocated memory also. For example
int *a8byteDynamicInteger = new int[2];
char *a8byteChar = new (a8byteDynamicInteger) char[8];
In this case, the memory pointer by a8byteChar will be referring to dynamic memory allocated by a8byteDynamicInteger. In this case however, we need to explicitly call delete a8byteDynamicInteger to release the memory.
Another example for C++ Class
struct ComplexType {
int a;
ComplexType() : a(0) {}
~ComplexType() {}
};
int main() {
char* dynArray = new char[256];
//Calls ComplexType's constructor to initialize memory as a ComplexType
new((void*)dynArray) ComplexType();
//Clean up memory once we're done
reinterpret_cast<ComplexType*>(dynArray)->~ComplexType();
delete[] dynArray;
//Stack memory can also be used with placement new
alignas(ComplexType) char localArray[256]; //alignas() available since C++11
new((void*)localArray) ComplexType();
//Only need to call the destructor for stack memory
reinterpret_cast<ComplexType*>(localArray)->~ComplexType();
return 0;
}
- https://en.cppreference.com/w/cpp/language/new
- https://en.cppreference.com/w/cpp/language/new#Placement_new
- https://riptutorial.com/cplusplus/example/9740/placement-new
Why doesn’t ANSI C have namespaces?
ANSI C doesn’t support it. Why not? Any plans to include it in a future standard?
Answers:
For completeness there are several ways to achieve the “benefits” you might get from namespaces, in C. One of my favorite methods is using a structure to house a bunch of method pointers which are the interface to your library/etc..
You then use an extern instance of this structure which you initialize inside your library pointing to all your functions. This allows you to keep your names simple in your library without stepping on the clients namespace (other than the extern variable at global scope, 1 variable vs possibly hundreds of methods..)
There is some additional maintenance involved but I feel that it is minimal.
Here is an example:
/* interface.h */
struct library {
const int some_value;
void (*method1)(void);
void (*method2)(int);
/* ... */
};
extern const struct library Library;
/* interface.c */
#include "interface.h"
void method1(void)
{
// ...
}
void method2(int arg)
{
// ...
}
const struct library Library = {
.method1 = method1,
.method2 = method2,
.some_value = 36
};
/* client code */
#include "interface.h"
int main(void)
{
Library.method1();
Library.method2(5);
printf("%d\n", Library.some_value);
return 0;
}
The use of . syntax creates a strong association over the classic Library_function() Library_some_value method. There are some limitations however, for one you can’t use macros as functions.
指向 const 的指针 / const 指针
// 指向 const 的指针:p 这个指针可以修改,但是指针指向地址里面的值不能改变
const int *p;
int const *p;
// const 指针:p 这个指针是常量的不能修改,因此必须初始化,但是指针所指的内容可以修改
int a;
int * const p = &a;
// 指针和内容都不可变:结合上面两种情况
int a;
const int * const p = &a;
C++’s extern-“C” functionality to languages other than C
As it is known, declaring extern "C" to C++ function makes its name have C linkage, enabling C code to link.
My question is - are there other programming languages we can make C++ function names have linkage to, something like extern "Lisp" or extern "FORTRAN"?
If not, why? What is the internal structure behind the “C”, that makes the limitations?
What are the alternatives?
Answers:
The C++ standard, 7.5.2 dcl.link, says:
Linkage between C++ and non-C++ code fragments can be achieved using a linkage-specification:
linkage-specification: extern string-literal { declaration-seqopt} extern string-literal declarationThe string-literal indicates the required language linkage. This International Standard specifies the semantics for the string-literals “C” and “C++”. Use of a string-literal other than “C” or “C++” is conditionally supported, with implementation-defined semantics. [ Note: Therefore, a linkage-specification with a string literal that is unknown to the implementation requires a diagnostic. —end note ] [ Note: It is recommended that the spelling of the string-literal be taken from the document defining that language. For example, Ada (not ADA) and Fortran or FORTRAN, depending on the vintage. —end note ]
So in principle, implementers can choose to support other linkage specifications than C and C++.
In practise however, on all modern platforms, C linkage is the lowest common denominator. As a general rule, these days, binary interop for languages other than C uses C linkage. On the widely used modern platforms, you will not see anything other than C and C++ linkage.
AlignUpTo8 (参考 protobuf/arena_impl.h)
inline size_t AlignUpTo8(size_t n) {
// Align n to next multiple of 8 (from Hacker's Delight, Chapter 3.)
return (n + 7) & static_cast<size_t>(-8);
}
Variable-length array (C99)
In computer programming, a variable-length array (VLA), also called variable-sized or runtime-sized, is an array data structure whose length is determined at run time (instead of at compile time). In C, the VLA is said to have a variably modified type that depends on a value (see Dependent type).
https://en.wikipedia.org/wiki/Variable-length_array
gcc throwing error relocation truncated to fit: R_X86_64_32 against `.bss’
Your global array takes up 40GB; you can’t put that in the program’s .data section. It doesn’t fit there.
Even if it did, you would end up with a gigantic binary, so it’s a bad idea in the first place.
If you have like 45+GB RAM installed, you can use a dynamic allocation (via std::vector) for this, otherwise, rethink your code to need less memory.
- https://stackoverflow.com/questions/38403414/gcc-throwing-error-relocation-truncated-to-fit-r-x86-64-32-against-bss
- https://stackoverflow.com/questions/57331990/c-compiling-relocation-truncated-to-fit-r-x86-64-pc32-against-symbol
push_back vs emplace_back
The real C++0x form of emplace_back is really useful: void emplace_back(Args&&…);
Instead of taking a value_type it takes a variadic list of arguments, so that means that you can now perfectly forward the arguments and construct directly an object into a container without a temporary at all.
Default arguments
默认参数不是函数原型的一部分
The default arguments are not part of the function type
int f(int = 0);
void h()
{
int j = f(1);
int k = f(); // calls f(0);
}
int (*p1)(int) = &f;
int (*p2)() = &f; // Error: the type of f is int(int)
What is the difference between new/delete and malloc/free?
new / delete
Allocate / release memory
- Memory allocated from ‘Free Store’.
- Returns a fully typed pointer.
new(standard version) never returns aNULL(will throw on failure).- Are called with Type-ID (compiler calculates the size).
- Has a version explicitly to handle arrays.
- Reallocating (to get more space) not handled intuitively (because of copy constructor).
- Whether they call
malloc/freeis implementation defined. - Can add a new memory allocator to deal with low memory (
std::set_new_handler). operator new/operator deletecan be overridden legally.- Constructor / destructor used to initialize / destroy the object.
malloc / free
Allocate / release memory
- Memory allocated from ‘Heap’.
- Returns a
void*. - Returns
NULLon failure. - Must specify the size required in bytes.
- Allocating array requires manual calculation of space.
- Reallocating larger chunk of memory simple (no copy constructor to worry about).
- They will NOT call
new/delete. - No way to splice user code into the allocation sequence to help with low memory.
malloc/freecan NOT be overridden legally.
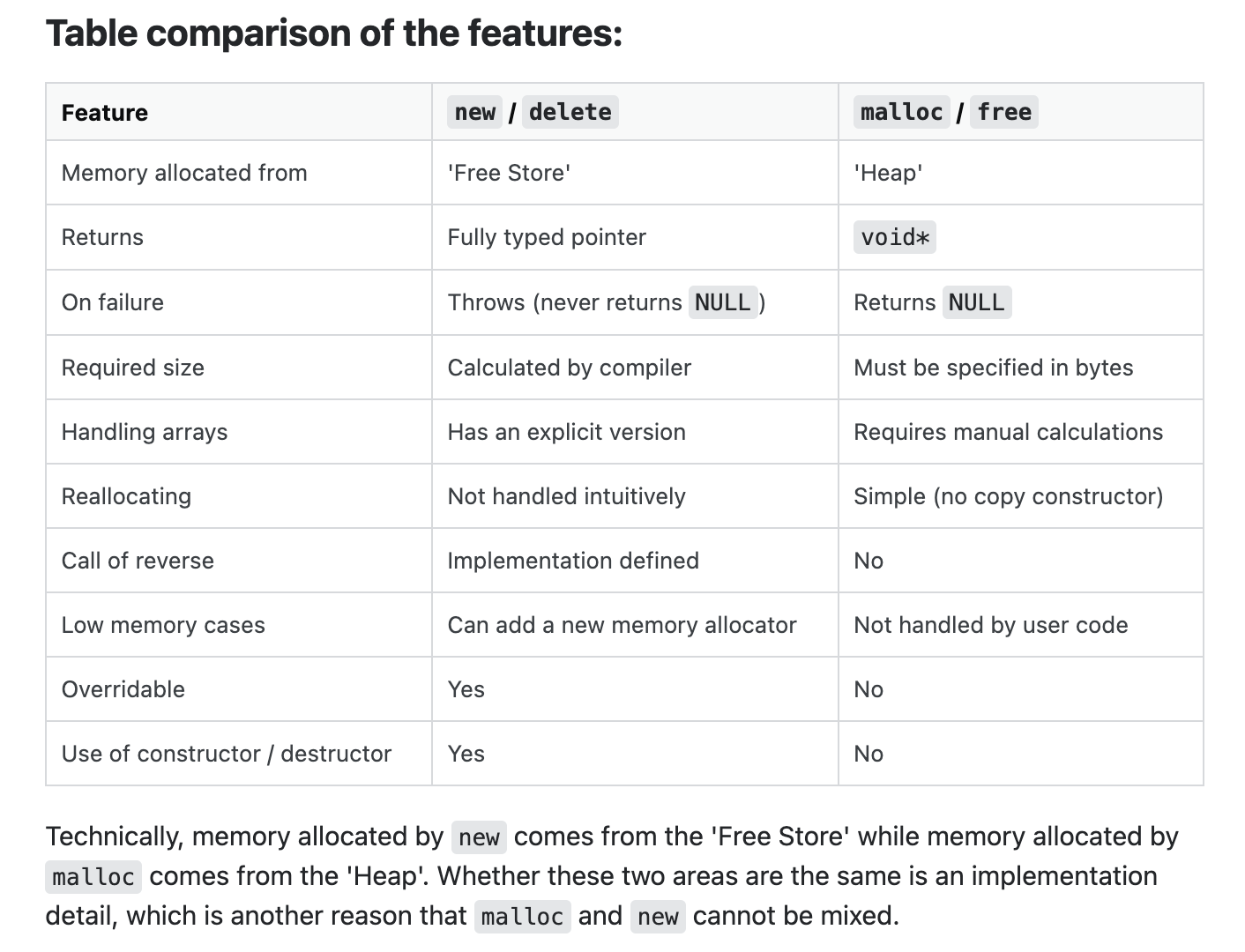
https://en.cppreference.com/w/cpp/language/new
array 初始化性能差异
Really can’t understand how gcc initialize array
My example is very simple:
extern int fun(int arr[]);
int foo(void)
{
int arr[64] = {0};
return fun(arr);
}
When I compile it using clang, the asm code is very straightforward:
foo: # @foo
.cfi_startproc
# %bb.0:
subq $264, %rsp # imm = 0x108
.cfi_def_cfa_offset 272
xorps %xmm0, %xmm0
movaps %xmm0, 240(%rsp)
movaps %xmm0, 224(%rsp)
movaps %xmm0, 208(%rsp)
movaps %xmm0, 192(%rsp)
movaps %xmm0, 176(%rsp)
movaps %xmm0, 160(%rsp)
movaps %xmm0, 144(%rsp)
movaps %xmm0, 128(%rsp)
movaps %xmm0, 112(%rsp)
movaps %xmm0, 96(%rsp)
movaps %xmm0, 80(%rsp)
movaps %xmm0, 64(%rsp)
movaps %xmm0, 48(%rsp)
movaps %xmm0, 32(%rsp)
movaps %xmm0, 16(%rsp)
movaps %xmm0, (%rsp)
movq %rsp, %rdi
callq fun
addq $264, %rsp # imm = 0x108
.cfi_def_cfa_offset 8
retq
Though gcc generate shorter asm code, I can’t really understand it.Here is the code from gcc:
foo:
.LFB0:
.cfi_startproc
subq $264, %rsp
.cfi_def_cfa_offset 272
xorl %eax, %eax
movl $32, %ecx
movq %rsp, %rdi
rep stosq
movq %rsp, %rdi
call fun@PLT
addq $264, %rsp
.cfi_def_cfa_offset 8
ret
I am an asm code novice. Sorry about that if my question is stupid. But any guidance is welcome.
Answers:
rep stosq = memset(rdi, rax, rcx*8).
Neither of these are obviously great choices; that’s maybe too much unrolling from clang, and ERMSB doesn’t make rep stos that great. But a medium-sized memset is a hard problem on modern x86; it’s small enough that rep stos startup overhead matters.
It is clear if “req stosq” means “call memset” ?
It doesn’t actually call memset, there’s no call instruction. It invokes the optimized microcode inside the CPU that implements rep stos. (And leaves RDI and RCX modified.)
测试汇编代码:
- https://gcc.godbolt.org/z/r4z6n6az8 (clang 11)
- https://gcc.godbolt.org/z/x6K8h95Te (gcc 4.8.5)
int main() {
char s[256] = {0};
s[0] = '1';
printf("%s\n", s);
return 0;
}
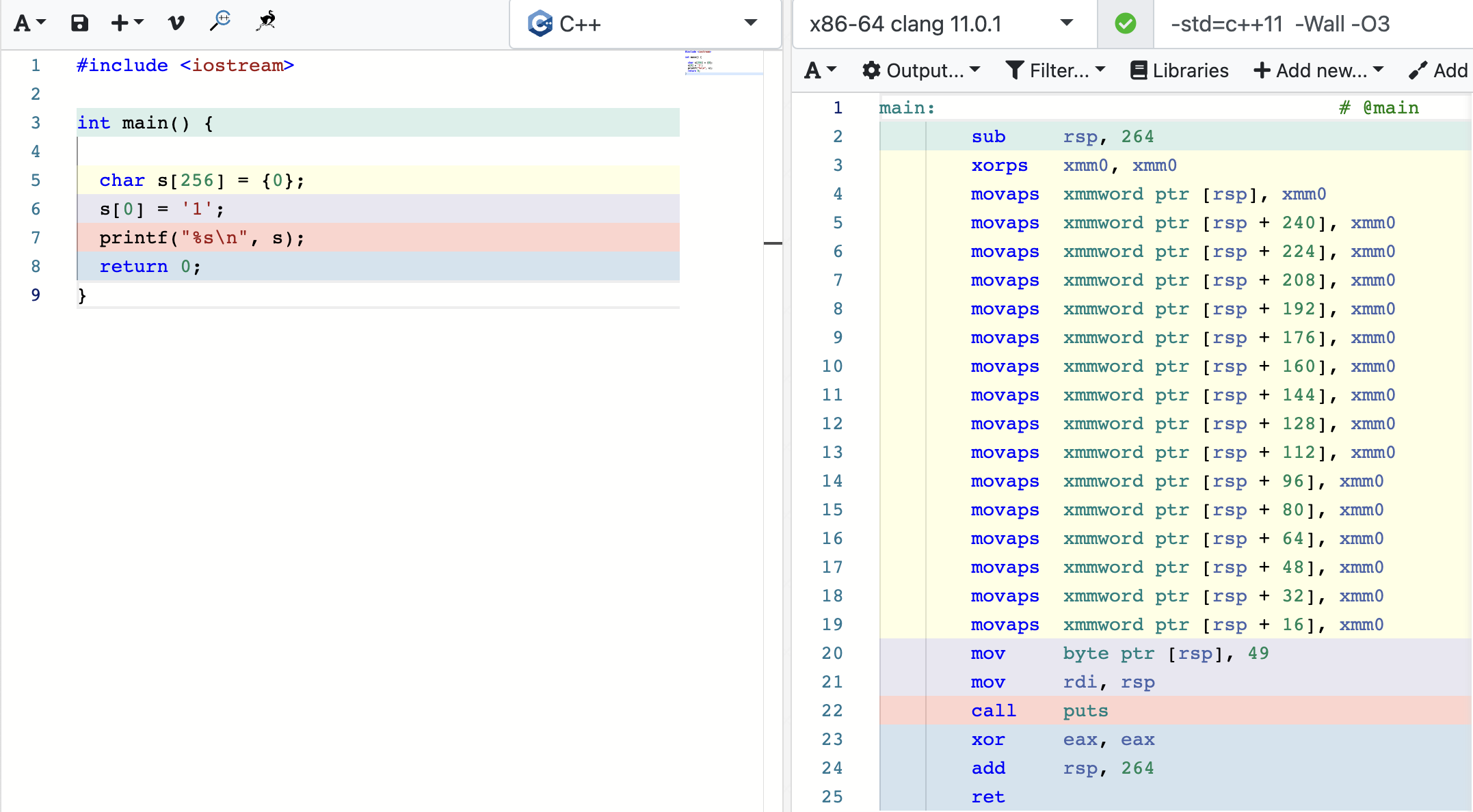
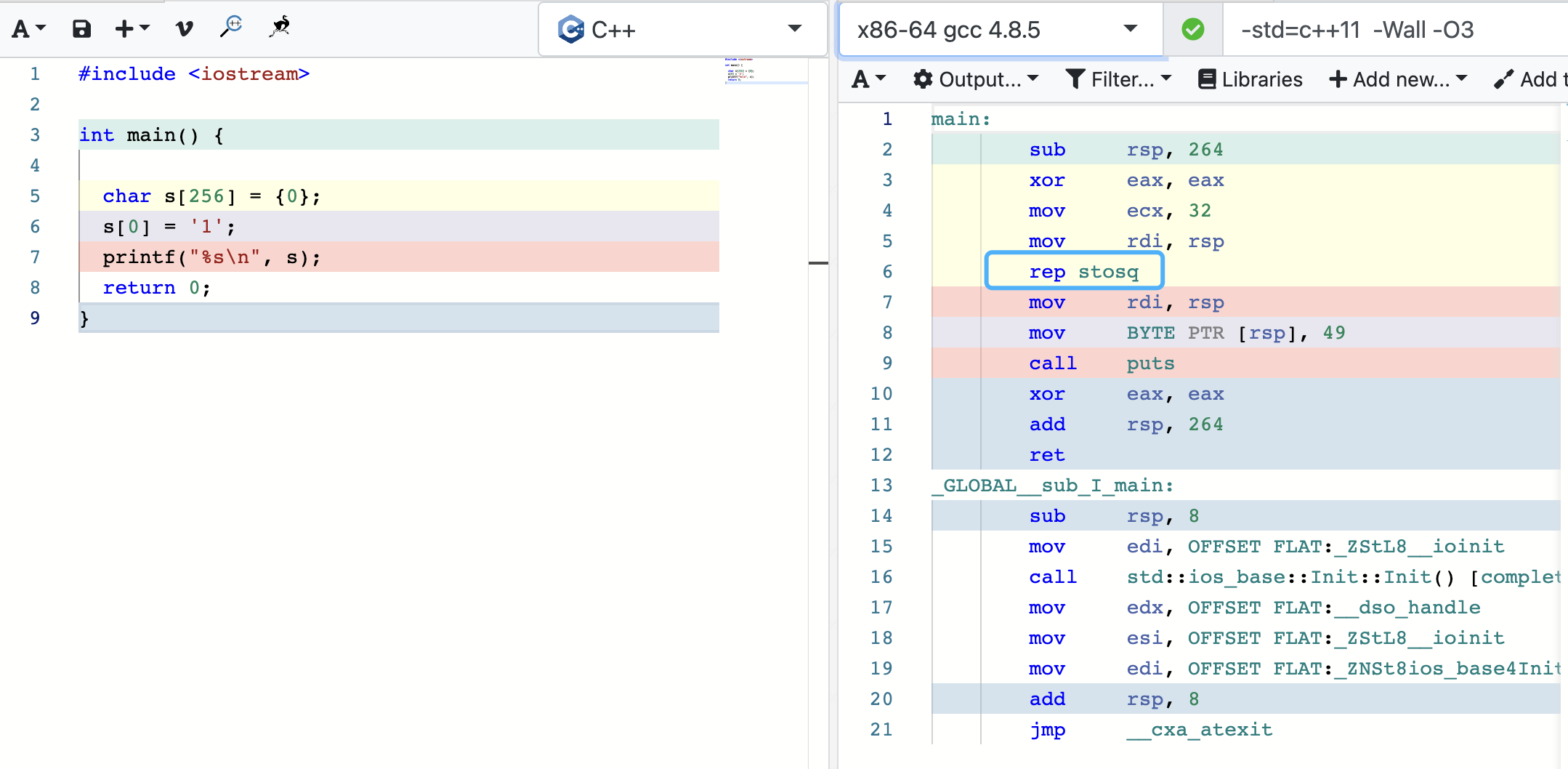
性能测试对比:https://quick-bench.com/q/E4CUT5V18h-B2n0B_Q6ML59GbjU
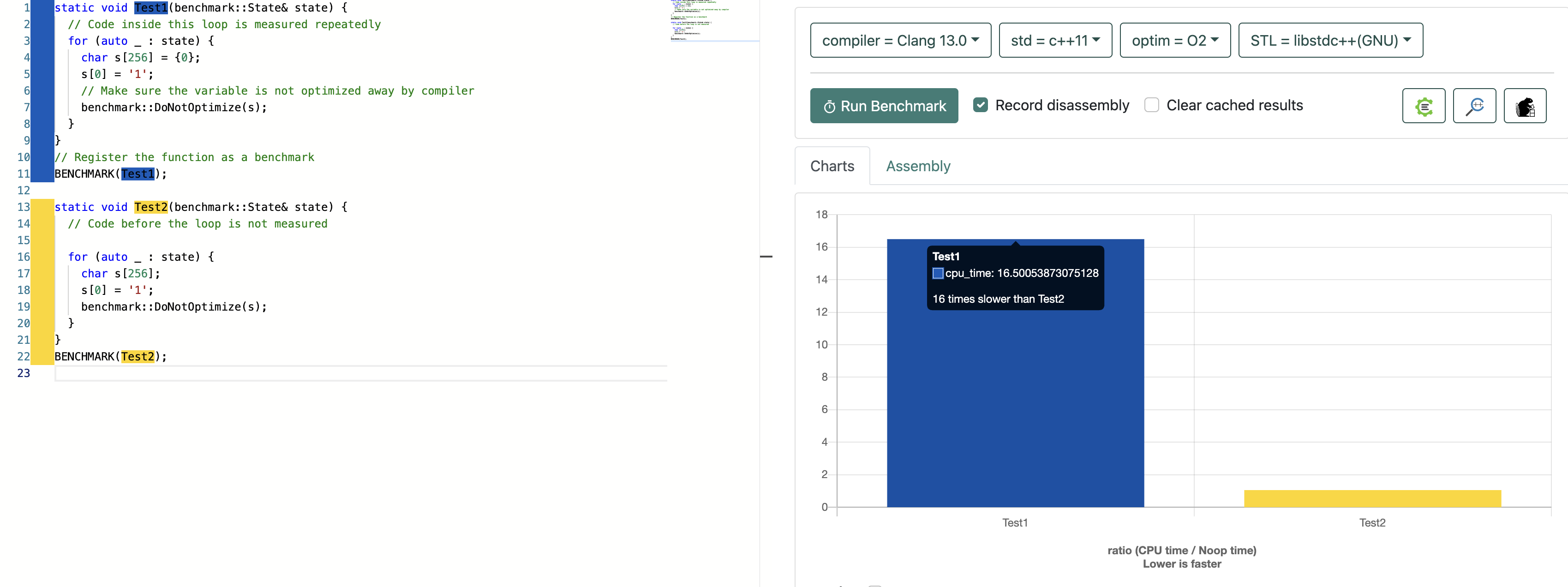
see: REP/REPE/REPZ/REPNE/REPNZ — Repeat String Operation Prefix
operator overloading
Customizes the C++ operators for operands of user-defined types.
When an operator appears in an expression, and at least one of its operands has a class type or an enumeration type, then overload resolution is used to determine the user-defined function to be called among all the functions whose signatures match the following:

When is it necessary to use the flag -stdlib=libstdc++?
When is it necessary to use use the flag
-stdlib=libstdc++for the compiler and linker when compiling with gcc?
Short answer: never
Longer answer: -stdlib is a Clang flag and will not work with any version of GCC ever released. On Mac OS X sometimes the gcc and g++ commands are actually aliases for Clang not GCC, and the version of libstdc++ that Apple ships is ancient (circa 2008) so of course it doesn’t support C++11. This means that on OS X when using Clang-pretending-to-be-GCC, you can use -stdlib=libc++ to select Clang’s new C++11-compatible library, or you can use -stdlib=libstdc++ to select the pre-C++11 antique version of libstdc++ that belongs in a museum. But on GNU/Linux gcc and g++ really are GCC not Clang, and so the -stdlib option won’t work at all.
Does the compiler automatically use libstdc++?
Yes, GCC always uses libstdc++ unless you tell it to use no standard library at all with the -nostdlib option (in which case you either need to avoid using any standard library features, or use -I and -L and -l flags to point it to an alternative set of header and library files).
I am using gcc4.8.2 on Ubuntu 13.10 and I would like to use the c++11 standard. I already pass -std=c++11 to the compiler.
You don’t need to do anything else. GCC comes with its own implementation of the C++ standard library (libstdc++) which is developed and tested alongside GCC itself so the version of GCC and the version of libstdc++ are 100% compatible. If you compile with -std=c++11 then that enables the C++11 features in g++ compiler and also the C++11 features in the libstdc++ headers.
Use new operator to initialise an array
In the new Standard for C++ (C++11), you can do this:
int* a = new int[10] { 1,2,3,4,5,6,7,8,9,10 };
It’s called an initializer list. But in previous versions of the standard that was not possible.
The relevant online reference with further details (and very hard to read) is here. I also tried it using GCC and the --std=c++0x option and confirmed that it works indeed.
空指针类型转换,执行函数
#include <cstdio>
struct X
{
void test()
{
puts("123");
}
virtual void test2()
{
puts("456");
}
};
int main()
{
X* x = (X*)nullptr;
x->test(); // ok, print "123"
x->test2(); // error, Segmentation fault
}
C++ 异常
- https://en.cppreference.com/w/cpp/language/throw
- https://en.cppreference.com/w/cpp/language/try_catch
- https://wiki.sei.cmu.edu/confluence/display/cplusplus/ERR61-CPP.+Catch+exceptions+by+lvalue+reference
#include <iostream>
#include <stdexcept>
void f()
{
std::cout << "f\n";
throw std::runtime_error("err");
}
int main()
{
f();
}
(gdb) bt
#0 0x00007f1b122862e7 in __GI_raise (sig=sig@entry=6) at ../nptl/sysdeps/unix/sysv/linux/raise.c:56
#1 0x00007f1b122876c8 in __GI_abort () at abort.c:89
#2 0x00007f1b12b75a95 in __gnu_cxx::__verbose_terminate_handler() () from /lib64/libstdc++.so.6
#3 0x00007f1b12b73a06 in ?? () from /lib64/libstdc++.so.6
#4 0x00007f1b12b73a33 in std::terminate() () from /lib64/libstdc++.so.6
#5 0x00007f1b12b73c53 in __cxa_throw () from /lib64/libstdc++.so.6
#6 0x0000000000400bbe in f() ()
#7 0x0000000000400bfa in main ()
abort (异常没有捕获触发系统 abort 产生 core-dump)
即使捕获了 SIGABRT 信号,glibc 在执行完信号 handler 后会将其移出,再次执行 raise 调用,然后产生 core-dump
参考 glibc-2.18/stdlib/abort.c 代码:
/* Cause an abnormal program termination with core-dump. */
void
abort (void)
{
struct sigaction act;
sigset_t sigs;
/* First acquire the lock. */
__libc_lock_lock_recursive (lock);
/* Now it's for sure we are alone. But recursive calls are possible. */
/* Unlock SIGABRT. */
if (stage == 0)
{
++stage;
if (__sigemptyset (&sigs) == 0 &&
__sigaddset (&sigs, SIGABRT) == 0)
__sigprocmask (SIG_UNBLOCK, &sigs, (sigset_t *) NULL);
}
/* Flush all streams. We cannot close them now because the user
might have registered a handler for SIGABRT. */
if (stage == 1)
{
++stage;
fflush (NULL);
}
/* Send signal which possibly calls a user handler. */
if (stage == 2)
{
/* This stage is special: we must allow repeated calls of
`abort' when a user defined handler for SIGABRT is installed.
This is risky since the `raise' implementation might also
fail but I don't see another possibility. */
int save_stage = stage;
stage = 0;
__libc_lock_unlock_recursive (lock);
raise (SIGABRT);
__libc_lock_lock_recursive (lock);
stage = save_stage + 1;
}
/* There was a handler installed. Now remove it. */
if (stage == 3)
{
++stage;
memset (&act, '\0', sizeof (struct sigaction));
act.sa_handler = SIG_DFL;
__sigfillset (&act.sa_mask);
act.sa_flags = 0;
__sigaction (SIGABRT, &act, NULL);
}
/* Now close the streams which also flushes the output the user
defined handler might has produced. */
if (stage == 4)
{
++stage;
__fcloseall ();
}
/* Try again. */
if (stage == 5)
{
++stage;
raise (SIGABRT);
}
/* Now try to abort using the system specific command. */
if (stage == 6)
{
++stage;
ABORT_INSTRUCTION;
}
/* If we can't signal ourselves and the abort instruction failed, exit. */
if (stage == 7)
{
++stage;
_exit (127);
}
/* If even this fails try to use the provided instruction to crash
or otherwise make sure we never return. */
while (1)
/* Try for ever and ever. */
ABORT_INSTRUCTION;
}
异常产生 core 但无法显示正确的函数调用栈信息
- https://blog.csdn.net/u013272009/article/details/101458409
- Bug 55917 - Impossible to find/debug unhandled exceptions in an std::thread
- 我们是怎么发现C++异常从堆栈追踪中消失的原因的
rethrow
When rethrowing exceptions, the second form must be used to avoid object slicing in the (typical) case where exception objects use inheritance:
try
{
std::string("abc").substr(10); // throws std::length_error
}
catch (const std::exception& e)
{
std::cout << e.what() << '\n';
// throw e; // copy-initializes a new exception object of type std::exception
throw; // rethrows the exception object of type std::length_error
}
Stack unwinding
If the exception is thrown from a constructor that is invoked by a new-expression, the matching deallocation function is called, if available.
This process is called stack unwinding.
#include <iostream>
#include <stdexcept>
struct A
{
int n;
A(int n = 0): n(n) { std::cout << "A(" << n << ") constructed successfully\n"; }
~A() { std::cout << "A(" << n << ") destroyed\n"; }
};
int foo()
{
throw std::runtime_error("error");
}
struct B
{
A a1, a2, a3;
B() try : a1(1), a2(foo()), a3(3)
{
std::cout << "B constructed successfully\n";
}
catch(...)
{
std::cout << "B::B() exiting with exception\n";
}
~B() { std::cout << "B destroyed\n"; }
};
struct C : A, B
{
C() try
{
std::cout << "C::C() completed successfully\n";
}
catch(...)
{
std::cout << "C::C() exiting with exception\n";
}
~C() { std::cout << "C destroyed\n"; }
};
int main () try
{
// creates the A base subobject
// creates the a1 member of B
// fails to create the a2 member of B
// unwinding destroys the a1 member of B
// unwinding destroys the A base subobject
C c;
}
catch (const std::exception& e)
{
std::cout << "main() failed to create C with: " << e.what();
}
Output:
A(0) constructed successfully
A(1) constructed successfully
A(1) destroyed
B::B() exiting with exception
A(0) destroyed
C::C() exiting with exception
main() failed to create C with: error
异常性能测试
当平凡触发异常的时候,性能开销非常大。测试代码 https://quick-bench.com/q/OvaL3gUmfugz1YfSjwelTEimCho
static void A(benchmark::State& state) {
int a = -1;
auto f = [](int& a)
{
try {
if (a < 0) throw std::invalid_argument( "test" );
}
catch (const std::exception& e)
{
}
};
// Code inside this loop is measured repeatedly
for (auto _ : state) {
f(a);
// Make sure the variable is not optimized away by compiler
benchmark::DoNotOptimize(f);
}
}
// Register the function as a benchmark
BENCHMARK(A);
static void B(benchmark::State& state) {
// Code before the loop is not measured
int a = 1;
auto f = [](int a)
{
if (a < 0) a += 1;
};
for (auto _ : state) {
f(a + 1);
// Make sure the variable is not optimized away by compiler
benchmark::DoNotOptimize(f);
}
}
BENCHMARK(B);
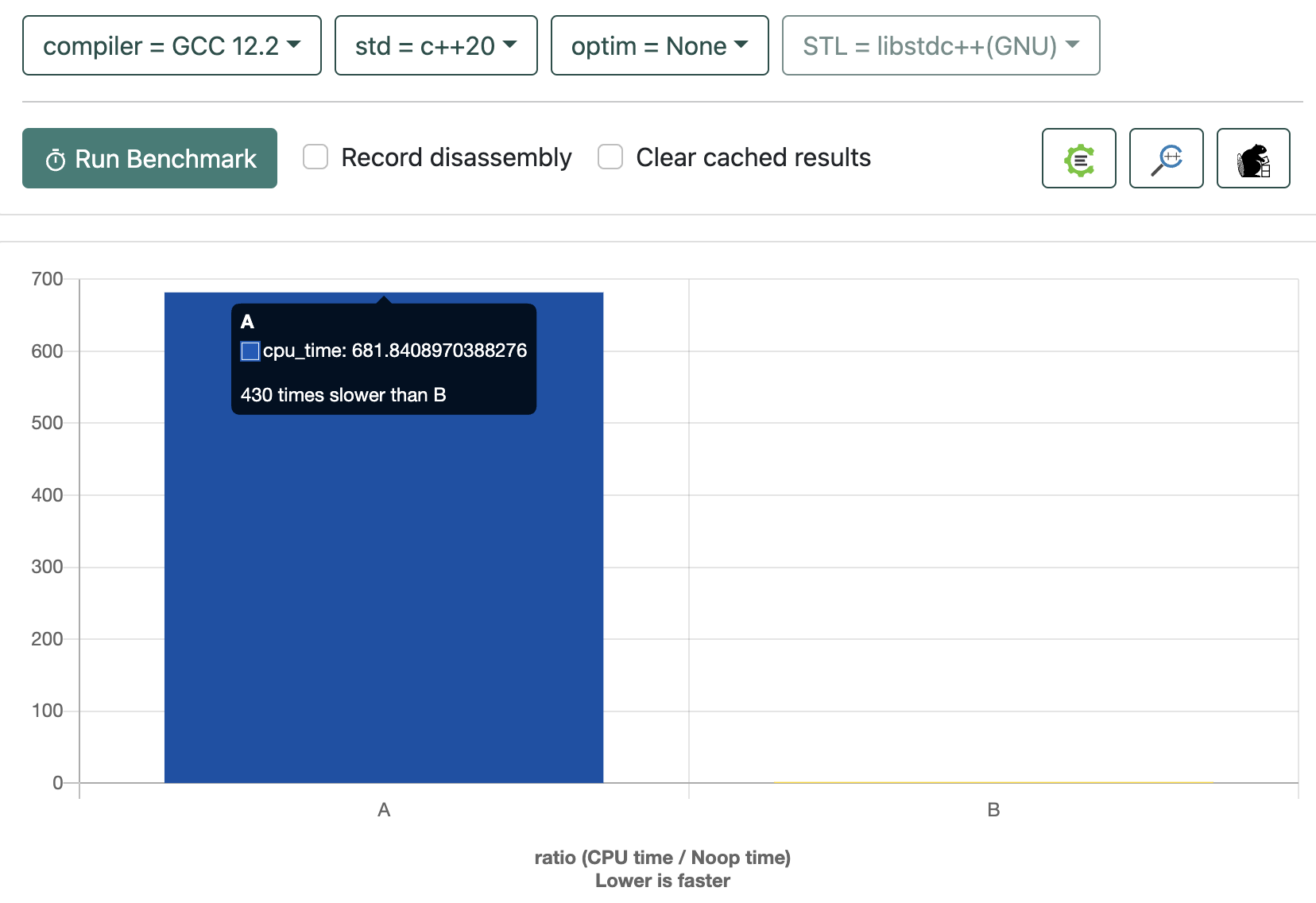
noexcept
// Returns a prvalue of type bool.
noexcept( expression )
The noexcept operator performs a compile-time check that returns true if an expression is declared to not throw any exceptions.
It can be used within a function template’s noexcept specifier to declare that the function will throw exceptions for some types but not others.
When should I really use noexcept?
#include <iostream>
#include <utility>
#include <vector>
void may_throw();
void no_throw() noexcept;
auto lmay_throw = []{};
auto lno_throw = []() noexcept {};
class T
{
public:
~T(){} // dtor prevents move ctor
// copy ctor is noexcept
};
class U
{
public:
~U(){} // dtor prevents move ctor
// copy ctor is noexcept(false)
std::vector<int> v;
};
class V
{
public:
std::vector<int> v;
};
int main()
{
T t;
U u;
V v;
std::cout << std::boolalpha
<< "Is may_throw() noexcept? " << noexcept(may_throw()) << '\n'
<< "Is no_throw() noexcept? " << noexcept(no_throw()) << '\n'
<< "Is lmay_throw() noexcept? " << noexcept(lmay_throw()) << '\n'
<< "Is lno_throw() noexcept? " << noexcept(lno_throw()) << '\n'
<< "Is ~T() noexcept? " << noexcept(std::declval<T>().~T()) << '\n'
// note: the following tests also require that ~T() is noexcept because
// the expression within noexcept constructs and destroys a temporary
<< "Is T(rvalue T) noexcept? " << noexcept(T(std::declval<T>())) << '\n'
<< "Is T(lvalue T) noexcept? " << noexcept(T(t)) << '\n'
<< "Is U(rvalue U) noexcept? " << noexcept(U(std::declval<U>())) << '\n'
<< "Is U(lvalue U) noexcept? " << noexcept(U(u)) << '\n'
<< "Is V(rvalue V) noexcept? " << noexcept(V(std::declval<V>())) << '\n'
<< "Is V(lvalue V) noexcept? " << noexcept(V(v)) << '\n';
}
/*
Is may_throw() noexcept? false
Is no_throw() noexcept? true
Is lmay_throw() noexcept? false
Is lno_throw() noexcept? true
Is ~T() noexcept? true
Is T(rvalue T) noexcept? true
Is T(lvalue T) noexcept? true
Is U(rvalue U) noexcept? false
Is U(lvalue U) noexcept? false
Is V(rvalue V) noexcept? true
Is V(lvalue V) noexcept? false
*/
setjmp / longjmp (Thread safety)
setjmp, sigsetjmp, longjmp, siglongjmp - performing a nonlocal goto, refer setjmp(3) — Linux manual page
#include <setjmp.h>
int setjmp(jmp_buf env);
[[noreturn]] void longjmp(jmp_buf env, int val);
The functions described on this page are used for performing “nonlocal gotos”: transferring execution from one function to a predetermined location in another function. The setjmp() function dynamically establishes the target to which control will later be transferred, and longjmp() performs the transfer of execution.
The setjmp() function saves various information about the calling environment (typically, the stack pointer, the instruction pointer, possibly the values of other registers and the signal mask) in the buffer env for later use by longjmp(). In this case, setjmp() returns 0.
The longjmp() function uses the information saved in env to transfer control back to the point where setjmp() was called and to restore (“rewind”) the stack to its state at the time of the setjmp() call. In addition, and depending on the implementation (see NOTES), the values of some other registers and the process signal mask may be restored to their state at the time of the setjmp() call.
Following a successful longjmp(), execution continues as if setjmp() had returned for a second time. This “fake” return can be distinguished from a true setjmp() call because the “fake” return returns the value provided in val. If the programmer mistakenly passes the value 0 in val, the “fake” return will instead return 1.
RETURN VALUE:
setjmp() returns 0 when called directly; on the “fake” return that occurs after longjmp(), the nonzero value specified in val is returned.
NOTES:
setjmp() and longjmp() can be useful for dealing with errors inside deeply nested function calls or to allow a signal handler to pass control to a specific point in the program, rather than returning to the point where the handler interrupted the main program.
示例代码:
#include <setjmp.h>
#include <stdio.h>
#include <sanitizer/asan_interface.h>
static jmp_buf buf;
void my_exception_handler() {
printf("Exception occurred!\n");
// 使用__asan_unpoison_memory_region取消标记栈上的内存区域
//__asan_unpoison_memory_region((void *)&buf, sizeof(buf));
// 使用longjmp跳出异常处理程序
longjmp(buf, 1);
}
void my_function() {
char buffer[32];
if (setjmp(buf)) {
// 如果从longjmp返回,取消标记栈上的内存区域
//__asan_unpoison_memory_region((void *)buffer, sizeof(buffer));
printf("Returned from exception handler\n");
} else {
// 正常执行时,触发异常处理程序
my_exception_handler();
}
}
int main() {
my_function();
return 0;
}
输出:
Exception occurred!
Returned from exception handler
开发框架
libatbus
用于搭建高性能、全异步(a)、树形结构(t)的BUS消息系统的跨平台框架库
PhotonLibOS (阿里)
Photon is a high-efficiency LibOS framework, based on a set of carefully selected C++ libs.
The role of LibOS is to connect user apps and the OS. Following the principle of Least Astonishment, we designed Photon’s API to be as consistent as possible with C++ std and POSIX semantics. This flattens the learning curve for lib users and brings convenience when migrating legacy codebases.
Photon’s runtime is driven by a coroutine lib. Out tests show that it has the best I/O performance in the open source world by the year of 2022, even among different programing languages.
As to the project vision, we hope that Photon would help programs run as fast and agile as the photon particle, which exactly is the naming came from.
Coost
coost is an elegant and efficient cross-platform C++ base library. Its goal is to create a sword of C++ to make C++ programming easy and enjoyable.
The original name of coost is co or cocoyaxi. It is like boost, but more lightweight, the static library built on linux or mac is only about 1MB in size. However, it still provides enough powerful features.
Libgo
Libgo is a stackful coroutine library for collaborative scheduling written in C++11, and it is also a powerful and easy-to-use parallel programming library.
asyncio
Asyncio is a C++20 coroutine library to write concurrent code using the await syntax, and imitate python asyncio library.
boost::asio
Asio is a cross-platform C++ library for network and low-level I/O programming that provides developers with a consistent asynchronous model using a modern C++ approach.
basic_string 相关
构造函数
#include <cassert>
#include <cctype>
#include <iomanip>
#include <iostream>
#include <iterator>
#include <string>
int main()
{
std::cout << "1) string(); ";
std::string s1;
assert(s1.empty() && (s1.length() == 0) && (s1.size() == 0));
std::cout << "s1.capacity(): " << s1.capacity() << '\n'; // unspecified
std::cout << "2) string(size_type count, CharT ch): ";
std::string s2(4, '=');
std::cout << std::quoted(s2) << '\n'; // "===="
std::cout << "3) string(const string& other, size_type pos, size_type count): ";
std::string const other3("Exemplary");
std::string s3(other3, 0, other3.length()-1);
std::cout << quoted(s3) << '\n'; // "Exemplar"
std::cout << "4) string(const string& other, size_type pos): ";
std::string const other4("Mutatis Mutandis");
std::string s4(other4, 8);
std::cout << quoted(s4) << '\n'; // "Mutandis", i.e. [8, 16)
std::cout << "5) string(CharT const* s, size_type count): ";
std::string s5("C-style string", 7);
std::cout << quoted(s5) << '\n'; // "C-style", i.e. [0, 7)
std::cout << "6) string(CharT const* s): ";
std::string s6("C-style\0string");
std::cout << quoted(s6) << '\n'; // "C-style"
std::cout << "7) string(InputIt first, InputIt last): ";
char mutable_c_str[] = "another C-style string";
std::string s7(std::begin(mutable_c_str) + 8, std::end(mutable_c_str) - 1);
std::cout << quoted(s7) << '\n'; // "C-style string"
std::cout << "8) string(string&): ";
std::string const other8("Exemplar");
std::string s8(other8);
std::cout << quoted(s8) << '\n'; // "Exemplar"
std::cout << "9) string(string&&): ";
std::string s9(std::string("C++ by ") + std::string("example"));
std::cout << quoted(s9) << '\n'; // "C++ by example"
std::cout << "a) string(std::initializer_list<CharT>): ";
std::string sa({'C', '-', 's', 't', 'y', 'l', 'e'});
std::cout << quoted(sa) << '\n'; // "C-style"
// before C++11, overload resolution selects string(InputIt first, InputIt last)
// [with InputIt = int] which behaves *as if* string(size_type count, CharT ch)
// after C++11 the InputIt constructor is disabled for integral types and calls:
std::cout << "b) string(size_type count, CharT ch) is called: ";
std::string sb(3, std::toupper('a'));
std::cout << quoted(sb) << '\n'; // "AAA"
[[maybe_unused]]
auto zero = [] { /* ... */ return nullptr; };
// std::string sc{zero()}; // Before C++23: throws std::logic_error
// Since C++23: won't compile, see overload (12)
}
str2hex / hex2string
C++ convert string to hexadecimal and vice versa
#include <string>
#include <cstdint>
#include <sstream>
#include <iomanip>
std::string string_to_hex(const std::string& in) {
std::stringstream ss;
ss << std::hex << std::setfill('0');
for (size_t i = 0; in.length() > i; ++i) {
ss << std::setw(2) << static_cast<unsigned int>(static_cast<unsigned char>(in[i]));
}
return ss.str();
}
std::string hex_to_string(const std::string& in) {
std::string output;
if ((in.length() % 2) != 0) {
throw std::runtime_error("String is not valid length ...");
}
size_t cnt = in.length() / 2;
for (size_t i = 0; cnt > i; ++i) {
uint32_t s = 0;
std::stringstream ss;
ss << std::hex << in.substr(i * 2, 2);
ss >> s;
output.push_back(static_cast<unsigned char>(s));
}
return output;
}
std::setw / std::left (输出对齐)
可以使用 std::setw() 函数和 std::left、std::right、std::internal 等标志来控制输出的对齐方式。
#include <iostream>
#include <iomanip>
#include <sstream>
int main() {
std::stringstream ss;
ss << std::setw(15) << std::left << "thread" << std::setw(15) << std::left << "reporttime" << std::setw(15) << std::left << "status(0:OK, 1:Exception, 2:Timeout)" << std::endl;
ss << std::setw(15) << std::left << "NetMsgThread" << std::setw(15) << std::left << 1684460218 << std::setw(15) << std::left << 0 << std::endl;
ss << std::setw(15) << std::left << "unittest" << std::setw(15) << std::left << 1684460218 << std::setw(15) << std::left << 0 << std::endl;
ss << std::setw(15) << std::left << "unittestsvr" << std::setw(15) << std::left << 1684460223 << std::setw(15) << std::left << 0 << std::endl;
std::cout << ss.str();
return 0;
}
使用 std::setw 函数设置输出的宽度,使用 std::left 标志控制输出的对齐方式。需要注意的是,std::setw 函数只对下一个输出字段起作用,因此在输出多个字段时,需要多次调用该函数。
输出的结果如下:
thread reporttime status(0:OK, 1:Exception, 2:Timeout)
NetMsgThread 1684460218 0
unittest 1684460218 0
unittestsvr 1684460223 0
abi Namespace Reference
abi::__cxa_demangle
Transforming C++ ABI identifiers (like RTTI symbols) into the original C++ source identifiers is called “demangling.”
If you have read the source documentation for namespace abi then you are aware of the cross-vendor C++ ABI in use by GCC. One of the exposed functions is used for demangling, abi::__cxa_demangle.
In programs like c++filt, the linker, and other tools have the ability to decode C++ ABI names, and now so can you.
#include <cxxabi.h>
#include <string>
#include <iostream>
int main() {
std::string mangled = "N4JLib17CApolloServiceMgr5STCfgE";
int status;
char* demangled = abi::__cxa_demangle(mangled.c_str(), nullptr, nullptr, &status);
if (status == 0) {
std::cout << "Demangled: " << demangled << std::endl;
std::free(demangled);
} else {
std::cerr << "Demangling failed" << std::endl;
}
return 0;
}
/*
Demangled: JLib::CApolloServiceMgr::STCfg
*/
- https://gcc.gnu.org/onlinedocs/libstdc++/manual/ext_demangling.html
- https://gcc.gnu.org/onlinedocs/libstdc++/libstdc++-html-USERS-4.3/a01696.html
Refer
- 编程面试题在线训练平台
- http://www.linuxhowtos.org/C_C++/
- The GNU C++ Library Manual
TODO
拷贝构造/赋值构造/移动拷贝构造/移动赋值构造
#include <iostream>
class A
{
public:
explicit A(int _a, int _b)
{
std::cout << "explicit A(int _a, int _b) \n";
a = _a;
b = _b;
}
A(const A& rhs)
{
std::cout << "A(const A& rhs)\n";
this->a = rhs.a;
this->b = rhs.b;
}
A(const A&& rhs)
{
std::cout << "A(const A&& rhs)\n";
this->a = rhs.a;
}
A& operator=(const A& rhs)
{
std::cout << "A& operator=(const A& rhs)\n";
this->a = rhs.a;
this->b = rhs.b;
return *this;
}
A& operator=(const A&& rhs)
{
std::cout << "A& operator=(const A&& rhs)\n";
this->a = rhs.a;
return *this;
}
int a;
int b;
};
A f()
{
A a(1, 2);
return a;
}
int main()
{
A a(1, 2);
A b(3, 4);
b = a;
std::cout << b.a << " " << b.b << std::endl;
}
拷贝构造在继承场景下的使用问题 (子类禁止拷贝,父类没有禁止拷贝,导致父类仍然可以拷贝)
https://gcc.godbolt.org/z/4Y5G1vxvn
#include <iostream>
#include <map>
#include <string>
class CNonCopyable
{
public:
CNonCopyable() = default;
//CNonCopyable(CNonCopyable&&) noexcept = default;
//CNonCopyable& operator=(CNonCopyable&&) noexcept = default;
// forbidden methods
CNonCopyable(const CNonCopyable&) = delete;
CNonCopyable& operator=(const CNonCopyable&) = delete;
};
class A : public CNonCopyable
{
public:
A() : CNonCopyable() {
std::cout << "A()\n";
}
// Oops, A 类自己提供了拷贝构造函数,覆盖了禁止拷贝的限制
A(const A& a) {
}
};
A g_a;
A Get()
{
return g_a;
}
int main()
{
A a;
A b = Get();
std::cout << __clang_major__;
}
输出:
A()
A()
12
static 单例线程安全
#include <iostream>
#include <thread>
#include <vector>
#include <stdint.h>
int init()
{
std::cout << "init" << std::endl;
return 1;
}
int get_singleton()
{
static int s = init();
return s;
}
int main()
{
static uint32_t kThreadNum = 10;
std::vector<std::thread > th_vec(kThreadNum);
for (std::size_t i = 0; i < kThreadNum; ++i)
{
th_vec[i] = std::thread([]()
{
get_singleton();
});
}
for (std::size_t i = 0; i < kThreadNum; ++i)
{
th_vec[i].join();
}
}
https://blog.csdn.net/qq_44951325/article/details/124676268
ODR 问题
Is there a way to detect inline function ODR violations?
So I have this code in 2 separate translation units:
// a.cpp
#include <stdio.h>
inline int func() { return 5; }
int proxy();
int main() { printf("%d", func() + proxy()); }
// b.cpp
inline int func() { return 6; }
int proxy() { return func(); }
When compiled normally the result is 10. When compiled with -O3 (inlining on) I get 11.
I have clearly done an ODR violation for func().
This is a really nasty C++ issue and I am amazed there isn’t reliable tooling for detecting it.
Other
- What every C++ programmer should know, The hard part
- Stacktrace from exception
- https://stackoverflow.com/questions/2354784/attribute-formatprintf-1-2-for-msvc
-
https://yun.weicheng.men/Book/C%2B%2B%E6%80%A7%E8%83%BD%E4%BC%98%E5%8C%96%E6%8C%87%E5%8D%97.pdf
-
https://en.cppreference.com/w/cpp/language/initialization
- Argument-dependent lookup https://en.cppreference.com/w/cpp/language/adl
Refer
- https://www.learncpp.com/
- https://zhjwpku.com/assets/pdf/books/C++.Primer.5th.Edition_2013.pdf