CPP Memory Pool
- 基础知识
- 操作系统内存分配的相关函数
- 内存管理一般性描述
- 内存管理的方法
- 内存管理器的设计目标
- 常见 C 内存管理程序
- ptmalloc (glibc 默认内存分配器)
- mimalloc (microsoft)
- minimalloc (google)
- malloc / free / calloc / realloc / reallocarray - allocate and free dynamic memory
- mallopt
- brk, sbrk - change data segment size
- mmap - map or unmap files or devices into memory
- madvise - give advice about use of memory
- malloc_info - export malloc state to a stream
- malloc_stats - print memory allocation statistics
- malloc_trim - release free memory from the heap
- 原理介绍
- Allocator (标准库分配器)
- 问题描述
- 通过基类指针释放对象
- Refer
基础知识
x86 平台 Linux 进程内存布局
Linux 系统在装载 elf 格式的程序文件时,会调用 loader 把可执行文件中的各个段依次载入到从某一地址开始的空间中(载入地址取决 link editor(ld) 和机器地址位数,在 32 位机
器上是 0x8048000,即 128M 处)。如下图所示,以 32 位机器为例,首先被载入的是 .text 段,然后是 .data 段,最后是 .bss 段。这可以看作是程序的开始空间。程序所能访问的最后的地址是 0xbfffffff,也就是到 3G 地址处,3G 以上的 1G 空间是内核使用的,应用程序不可以直接访问。应用程序的堆栈从最高地址处开始向下生长,.bss 段与堆栈之间的空间是空闲的,空闲空间被分成两部分,一部分为 heap,一部分为 mmap 映射区域,mmap 映射区域一般从 TASK_SIZE/3 的地方开始,但在不同的 Linux 内核和机器上,mmap 区域的开始位置一般是不同的。Heap 和 mmap 区域都可以供用户自由使用,但是它在刚开始的时候并没有映射到内存空间内,是不可访问的。在向内核请求分配该空间之前,对这个空间的访问会导致 segmentation fault。用户程序可以直接使用系统调用来管理 heap 和 mmap 映射区域,但更多的时候程序都是使用 C 语言提供的 malloc() 和 free() 函数来动态的分配和释放内存。stack 区域是唯一不需要映射,用户却可以访问的内存区域,这也是利用堆栈溢出进行攻击的基础。
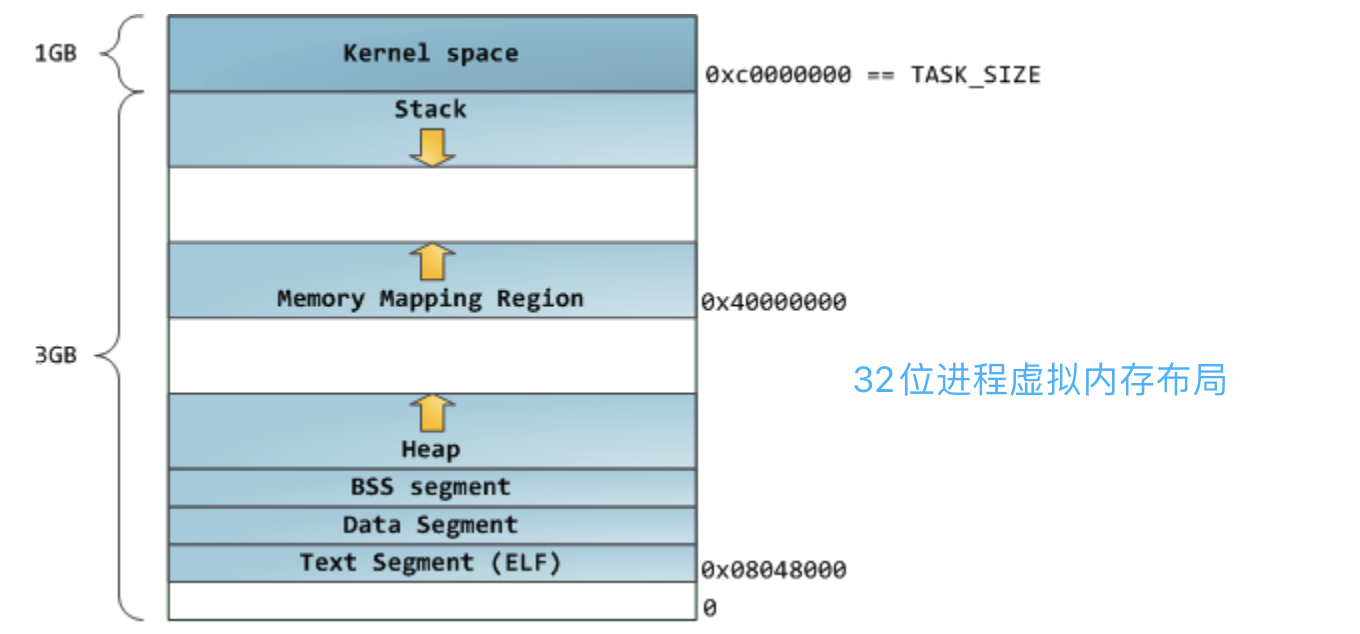
这种布局是 Linux 内核 2.6.7 以前的默认进程内存布局形式,mmap 区域与栈区域相对增长,这意味着堆只有 1GB 的虚拟地址空间可以使用,继续增长就会进入 mmap 映射区域,这显然不是我们想要的。这是由于 32 模式地址空间限制造成的,所以内核引入了另一种虚拟地址空间的布局形式,将在后面介绍。但对于 64 位系统,提供了巨大的虚拟地址空间,这种布局就相当好。
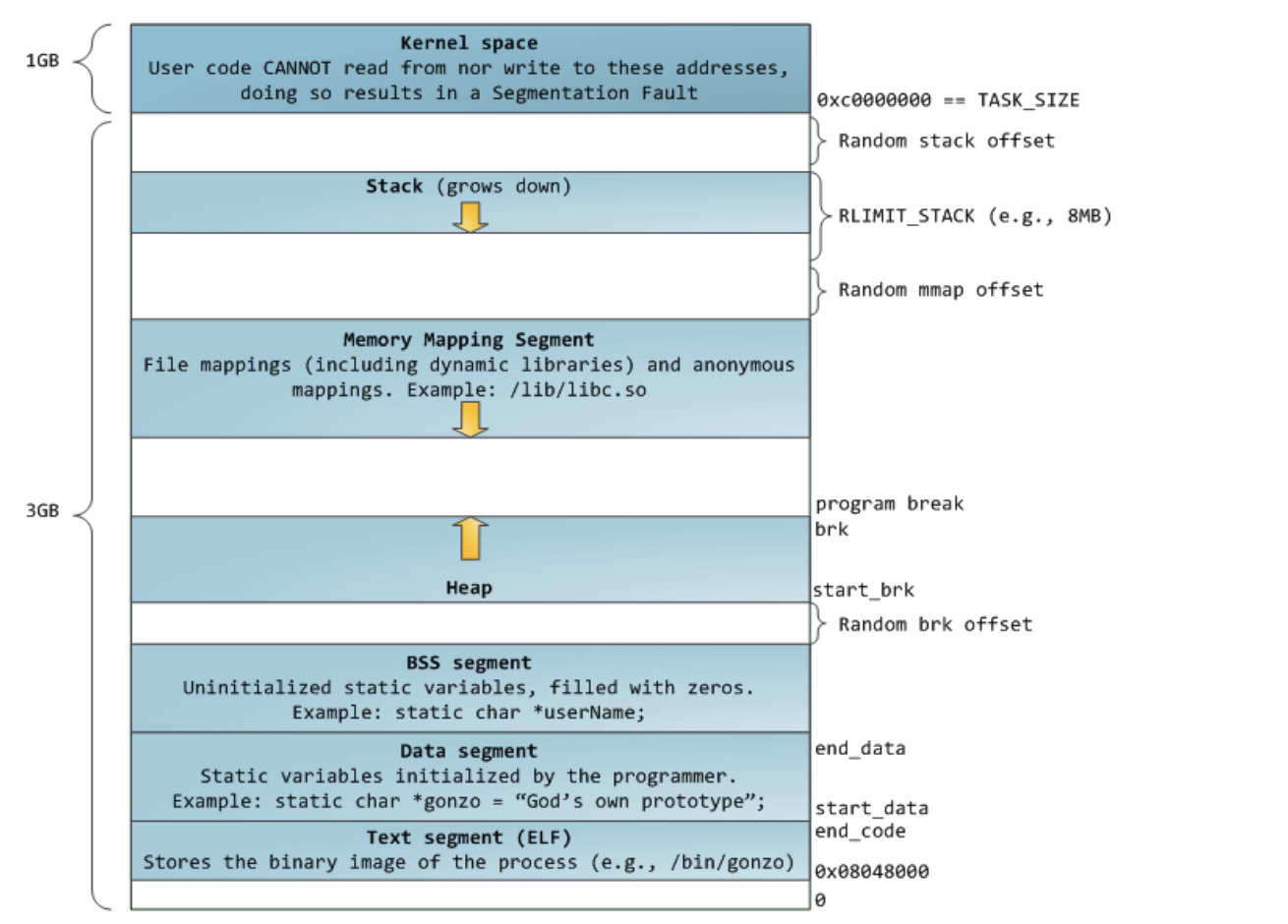
从上图可以看到,栈至顶向下扩展,并且栈是有界的。堆至底向上扩展,mmap 映射区域至顶向下扩展,mmap 映射区域和堆相对扩展,直至耗尽虚拟地址空间中的剩余区域,这种结构便于 C 运行时库使用 mmap 映射区域和堆进行内存分配。上图的布局形式是在内核 2.6.7 以后才引入的,这是 32 位模式下进程的默认内存布局形式。
在 64 位模式下各个区域的起始位置是什么呢?对于 AMD64 系统,内存布局采用经典内存布局,text 的起始地址为 0x0000000000400000,堆紧接着 BSS 段向上增长,mmap 映射
区域开始位置一般设为 TASK_SIZE/3。
#define TASK_SIZE_MAX ((1UL << 47) - PAGE_SIZE)
#define TASK_SIZE (test_thread_flag(TIF_IA32) ? \
IA32_PAGE_OFFSET : TASK_SIZE_MAX)
#define STACK_TOP TASK_SIZE
#define TASK_UNMAPPED_BASE (PAGE_ALIGN(TASK_SIZE / 3))
计算一下可知,mmap 的开始区域地址为 0x00002AAAAAAAA000,栈顶地址为 0x00007FFFFFFFF000
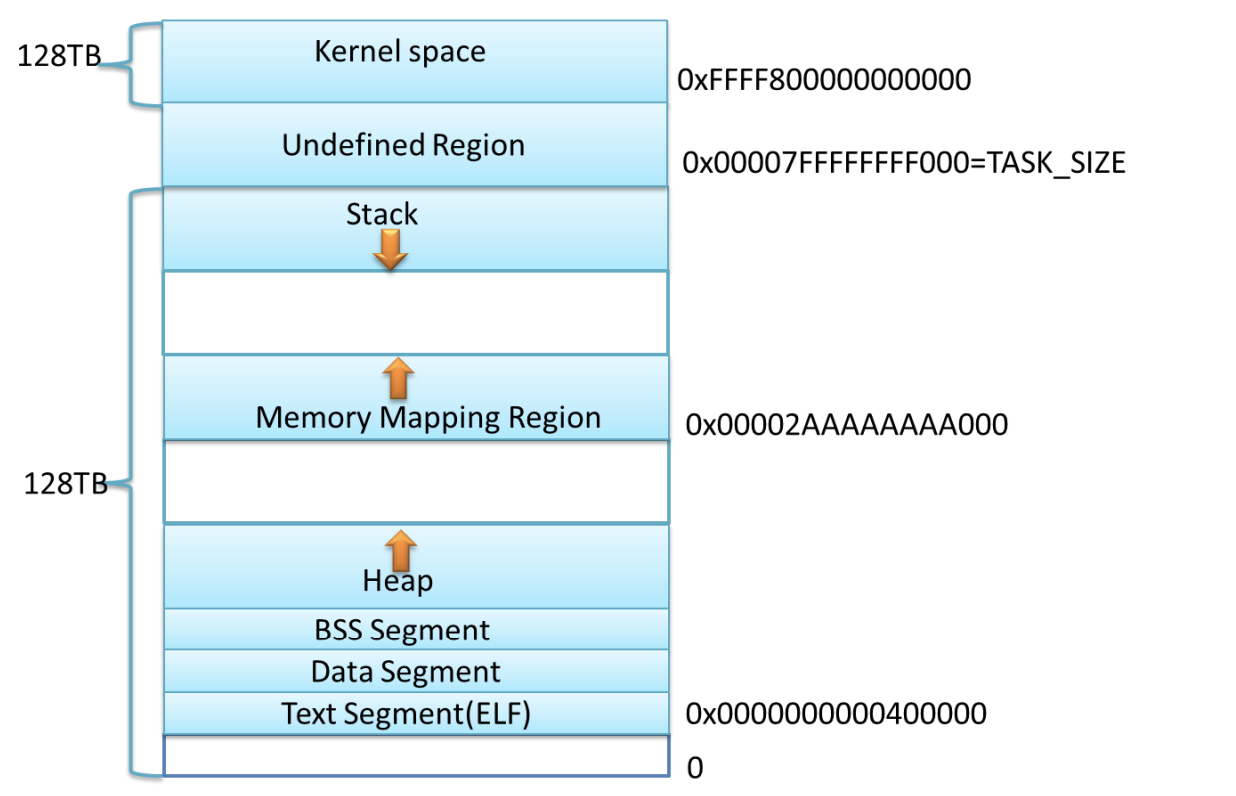
上图是 X86_64 下 Linux 进程的默认内存布局形式,这只是一个示意图,当前内核默认配置下,进程的栈和 mmap 映射区域并不是从一个固定地址开始,并且每次启动时的值都不一样,这是程序在启动时随机改变这些值的设置,使得使用缓冲区溢出进行攻击更加困难。当然也可以让进程的栈和 mmap 映射区域从一个固定位置开始,只需要设置全局变量 randomize_va_space 值为 0 , 这个变量默认值为 1 。 用户可以通过设置 /proc/sys/kernel/randomize_va_space 来停用该特性,也可以用如下命令:
sudo sysctl -w kernel.randomize_va_space=0
操作系统内存分配的相关函数
heap 和 mmap 映射区域是可以提供给用户程序使用的虚拟内存空间,如何获得该区域的内存呢?操作系统提供了相关的系统调用来完成相关工作。
- 对 heap 的操作,操作系统提供了
brk()函数,C 运行时库提供了sbrk()函数 - 对 mmap 映射区域的操作,操作系统提供了
mmap()和munmap()函数
sbrk(),brk() 或者 mmap() 都可以用来向我们的进程添加额外的虚拟内存。Glibc 同样是使用这些函数向操作系统申请虚拟内存。
这里要提到一个很重要的概念,内存的延迟分配,只有在真正访问一个地址的时候才建立这个地址的物理映射,这是 Linux 内存管理的基本思想之一。Linux 内核在用户申请内存的时候,只是给它分配了一个线性区(也就是虚拟内存),并没有分配实际物理内存;只有当用户使用这块内存的时候,内核才会分配具体的物理页面给用户,这时候才占用宝贵的物理内存。内核释放物理页面是通过释放线性区,找到其所对应的物理页面,将其全部释放的过程。
heap 操作相关函数
Heap 操作函数主要有两个,brk() 为系统调用,sbrk() 为 C 库函数。系统调用通常提供一种最小功能,而库函数通常提供比较复杂的功能。Glibc 的 malloc 函数族(realloc,calloc 等)就调用 sbrk() 函数将数据段的下界移动,sbrk() 函数在内核的管理下将虚拟地址空间映射到内存,供 malloc() 函数使用。
内核数据结构 mm_struct 中的成员变量 start_code 和 end_code 是进程代码段的起始和终止地址,start_data 和 end_data 是进程数据段的起始和终止地址,start_stack 是进程堆栈段起始地址,start_brk 是进程动态内存分配起始地址(堆的起始地址),还有一个 brk(堆的当前最后地址),就是动态内存分配当前的终止地址。C 语言的动态内存分配基本函数是 malloc(),在 Linux 上的实现是通过内核的 brk 系统调用。brk() 是一个非常简单的系统调用,只是简单地改变 mm_struct 结构的成员变量 brk 的值。
需要说明的是,当 sbrk() 的参数 increment 为 0 时,sbrk() 返回的是进程的当前 brk 值,increment 为正数时扩展 brk 值,当 increment 为负值时收缩 brk 值。
mmap 映射区域操作相关函数
mmap() 函数将一个文件或者其它对象映射进内存。文件被映射到多个页上,如果文件的大小不是所有页的大小之和,最后一个页不被使用的空间将会清零。munmap 执行相反的操作,删除特定地址区域的对象映射。
#include <sys/mman.h>
void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);
int munmap(void *addr, size_t length);
- addr:映射区的开始地址。
- length:映射区的长度。
- prot:期望的内存保护标志,不能与文件的打开模式冲突。
- flags:指定映射对象的类型,映射选项和映射页是否可以共享。它的值可以是一个或者多个以下位的组合体。
- fd:有效的文件描述符。如果 MAP_ANONYMOUS 被设定,为了兼容问题,其值应为 -1。
- offset:被映射对象内容的起点。
内存管理一般性描述
当不知道程序的每个部分将需要多少内存时,系统内存空间有限,而内存需求又是变化的,这时就需要内存管理程序来负责分配和回收内存。程序的动态性越强,内存管理就越重要,内存分配程序的选择也就更重要。
内存管理的方法
可用于内存管理的方法有许多种,它们各有好处与不足,不同的内存管理方法有最适用的情形。
C 风格的内存管理程序
C 风格的内存管理程序主要实现 malloc() 和 free() 函数。内存管理程序主要通过调用 brk() 或者 mmap() 进程添加额外的虚拟内存。Doug Lea Malloc,ptmalloc,BSD malloc,Hoard,TCMalloc 都属于这一类内存管理程序。
基于 malloc() 的内存管理器仍然有很多缺点,不管使用的是哪个分配程序。对于那些需要保持长期存储的程序使用 malloc() 来管理内存可能会非常令人失望。如果有大量的不固定的内存引用,经常难以知道它们何时被释放。生存期局限于当前函数的内存非常容易管理,但是对于生存期超出该范围的内存来说,管理内存则困难得多。因为管理内存的问题,很多程序倾向于使用它们自己的内存管理规则。
池式内存管理
内存池是一种半内存管理方法。内存池帮助某些程序进行自动内存管理,这些程序会经历一些特定的阶段,而且每个阶段中都有分配给进程的特定阶段的内存。例如,很多网络服务器进程都会分配很多针对每个连接的内存——内存的最大生存期限为当前连接的存在期。Apache 使用了池式内存(pooled memory),将其连接拆分为各个阶段,每个阶段都有自己的内存池。在结束每个阶段时,会一次释放所有内存。
在池式内存管理中,每次内存分配都会指定内存池,从中分配内存。每个内存池都有不同的生存期限。在 Apache 中,有一个持续时间为服务器存在期的内存池,还有一个持续时间为连接的存在期的内存池,以及一个持续时间为请求的存在期的池,另外还有其他一些内存池。因此,如果我的一系列函数不会生成比连接持续时间更长的数据,那么我就可以完全从连接池中分配内存,并知道在连接结束时,这些内存会被自动释放。另外,有一些实现允许注册清除函数(cleanup functions),在清除内存池之前,恰好可以调用它,来完成在内存被清理前需要完成的其他所有任务(类似于面向对象中的析构函数)。
使用池式内存分配的优点如下所示:
- 应用程序可以简单地管理内存。
- 内存分配和回收更快,因为每次都是在一个池中完成的。分配可以在 O(1) 时间内完成,释放内存池所需时间也差不多(实际上是 O(n) 时间,不过在大部分情况下会除以一个大的因数,使其变成 O(1))。
- 可以预先分配错误处理池(Error-handling pools),以便程序在常规内存被耗尽时仍可以恢复。
- 有非常易于使用的标准实现。
池式内存的缺点是:
- 内存池只适用于操作可以分阶段的程序。
- 内存池通常不能与第三方库很好地合作。
- 如果程序的结构发生变化,则不得不修改内存池,这可能会导致内存管理系统的重新设计。
- 您必须记住需要从哪个池进行分配。另外,如果在这里出错,就很难捕获该内存池。
引用计数
在引用计数中,所有共享的数据结构都有一个域来包含当前活动“引用”结构的次数。当向一个程序传递一个指向某个数据结构指针时,该程序会将引用计数增加 1。实质上,是在告诉数据结构,它正在被存储在多少个位置上。然后,当进程完成对它的使用后,该程序就会将引用计数减少 1。结束这个动作之后,它还会检查计数是否已经减到零。如果是,那么它将释放内存。
在 Java,Perl 等高级语言中,进行内存管理时使用引用计数非常广泛。在这些语言中,引用计数由语言自动地处理,所以您根本不必担心它,除非要编写扩展模块。由于所有内容都必须进行引用计数,所以这会对速度产生一些影响,但它极大地提高了编程的安全性和方便性。
以下是引用计数的好处:
- 实现简单。
- 易于使用。
- 由于引用是数据结构的一部分,所以它有一个好的缓存位置。
不过,它也有其不足之处:
- 要求您永远不要忘记调用引用计数函数。
- 无法释放作为循环数据结构的一部分的结构。
- 减缓几乎每一个指针的分配。
- 尽管所使用的对象采用了引用计数,但是当使用异常处理(比如 try 或 setjmp()/longjmp())时,您必须采取其他方法。
- 需要额外的内存来处理引用。
- 引用计数占用了结构中的第一个位置,在大部分机器中最快可以访问到的就是这个位置。
- 在多线程环境中更慢也更难以使用。
垃圾收集
垃圾收集(Garbage collection)是全自动地检测并移除不再使用的数据对象。垃圾收集器通常会在当可用内存减少到少于一个具体的阈值时运行。通常,它们以程序所知的可用的 一组“基本”数据——栈数据、全局变量、寄存器——作为出发点。然后它们尝试去追踪通过这些数据连接到每一块数据。收集器找到的都是有用的数据;它没有找到的就是垃圾,可以被销毁并重新使用这些无用的数据。为了有效地管理内存,很多类型的垃圾收集器都需要知道数据结构内部指针的规划,所以,为了正确运行垃圾收集器,它们必须是语言本身的一部分。
垃圾收集的一些优点:
- 永远不必担心内存的双重释放或者对象的生命周期。
- 使用某些收集器,您可以使用与常规分配相同的 API。
其缺点包括:
- 使用大部分收集器时,您都无法干涉何时释放内存。
- 在多数情况下,垃圾收集比其他形式的内存管理更慢。
- 垃圾收集错误引发的缺陷难于调试。
- 如果您忘记将不再使用的指针设置为 null,那么仍然会有内存泄漏。
内存管理器的设计目标
内存管理器为什么难写?在设计内存管理算法时,要考虑什么因素?管理内存这是内存管理器的功能需求。正如设计其它软件一样,质量需求一样占有重要的地位。分析内存管理算法之前,我们先看看对内存管理算法的质量需求有哪些:
- 最大化兼容性
要实现内存管理器时,先要定义出分配器的接口函数。接口函数没有必要标新立异,而是要遵循现有标准(如 POSIX 或者 Win32),让使用者可以平滑的过度到新的内存管理器上。
- 最大化可移植性
通常情况下,内存管理器要向 OS 申请内存,然后进行二次分配。所以,在适当的时候要扩展内存或释放多余的内存,这要调用 OS 提供的函数才行。OS 提供的函数则是因平台而 异,尽量抽象出平台相关的代码,保证内存管理器的可移植性。
- 浪费最小的空间
内存管理器要管理内存,必然要使用自己一些数据结构,这些数据结构本身也要占内存空间。在用户眼中,这些内存空间毫无疑问是浪费掉了,如果浪费在内存管理器身的内存太多,显然是不可以接受的。内存碎片也是浪费空间的罪魁祸首,若内存管理器中有大量的内存碎片,它们是一些不连续的小块内存,它们总量可能很大,但无法使用,这也是不可以接受的。
- 最快的速度
内存分配/释放是常用的操作。按着 2/8 原则,常用的操作就是性能热点,热点函数的性能对系统的整体性能尤为重要。
- 最大化可调性(以适应于不同的情况)
内存管理算法设计的难点就在于要适应用不同的情况。事实上,如果缺乏应用的上下文,是无法评估内存管理算法的好坏的。可以说在任何情况下,专用算法都比通用算法在时/空性能上的表现更优。为每种情况都写一套内存管理算法,显然是不太合适的。我们不需要追求最优算法,那样代价太高,能达到次优就行了。设计一套通用内存管理算法,通过一些参数对它进行配置,可以让它在特定情况也有相当出色的表现,这就是可调性。
- 最大化局部性(Locality)
大家都知道,使用 cache 可以提高程度的速度,但很多人未必知道 cache 使程序速度提高的真正原因。拿 CPU 内部的 cache 和 RAM 的访问速度相比,速度可能相差一个数量级。两者的速度上的差异固然重要,但这并不是提高速度的充分条件,只是必要条件。另外一个条件是程序访问内存的局部性(Locality)。大多数情况下,程序总访问一块内存附近的内存,把附近的内存先加入到 cache 中,下次访问 cache 中的数据,速度就会提高。否则,如果程序一会儿访问这里,一会儿访问另外一块相隔十万八千里的内存,这只会使数据在内存与 cache 之间来回搬运,不但于提高速度无益,反而会大大降低程序的速度。因此,内存管理算法要考虑这一因素,减少 cache miss 和 page fault。
- 最大化调试功能
作为一个 C/C++程序员,内存错误可以说是我们的噩梦,上一次的内存错误一定还让你记忆犹新。内存管理器提供的调试功能,强大易用,特别对于嵌入式环境来说,内存错误检测工具缺乏,内存管理器提供的调试功能就更是不可或缺了。
- 最大化适应性
前面说了最大化可调性,以便让内存管理器适用于不同的情况。但是,对于不同情况都要去调设置,无疑太麻烦,是非用户友好的。要尽量让内存管理器适用于很广的情况,只有极少情况下才去调设置。设计是一个多目标优化的过程,有些目标之间存在着竞争。如何平衡这些竞争力是设计的难点之一。在不同的情况下,这些目标的重要性又不一样,所以根本不存在一个最好的内存分配算法。
一切都需要折衷:性能、易用、易于实现、支持线程的能力等,为了满足项目的要求,有很多内存管理模式可供使用。每种模式都有大量的实现,各有其优缺点。内存管理的设计目标中,有些目标是相互冲突的,比如最快的分配、释放速度与内存的利用率,也就是内存碎片问题。不同的内存管理算法在两者之间取不同的平衡点。
为了提高分配、释放的速度,多核计算机上,主要做的工作是避免所有核同时在竞争内存,常用的做法是内存池,简单来说就是批量申请内存,然后切割成各种长度,各种长度都有一个链表,申请、释放都只要在链表上操作,可以认为是 O(1)的。不可能所有的长度都对应一个链表。很多内存池是假设,A 释放掉一块内存后,B 会申请类似大小的内存,但是 A释放的内存跟 B 需要的内存不一定完全相等,可能有一个小的误差,如果严格按大小分配,会导致复用率很低,这样各个链表上都会有很多释放了,但是没有复用的内存,导致利用率很低。这个问题也是可以解决的,可以回收这些空闲的内存,这就是传统的内存管理,不停地对内存块作切割和合并,会导致效率低下。所以通常的做法是只分配有限种类的长度。一般的内存池只提供几十种选择。
常见 C 内存管理程序
比较著名的几个 C 内存管理程序,其中包括:
Doug Lea Malloc
Doug Lea Malloc 实际上是完整的一组分配程序,其中包括 Doug Lea 的原始分配程序,GNU libc 分配程序和 ptmalloc。Doug Lea 的分配程序加入了索引,这使得搜索速度更快,并且可以将多个没有被使用的块组合为一个大的块。它还支持缓存,以便更快地再次使用最近释放的内存。ptmalloc 是 Doug Lea Malloc 的一个扩展版本,支持多线程。
BSD Malloc
BSD Malloc 是随 4.2 BSD 发行的实现,包含在 FreeBSD 之中,这个分配程序可以从预先确实大小的对象构成的池中分配对象。它有一些用于对象大小的 size 类,这些对象的大小为 2 的若干次幂减去某一常数。所以,如果您请求给定大小的一个对象,它就简单地分配一个与之匹配的 size 类。这样就提供了一个快速的实现,但是可能会浪费内存。
Hoard
编写 Hoard 的目标是使内存分配在多线程环境中进行得非常快。因此,它的构造以锁的使用为中心,从而使所有进程不必等待分配内存。它可以显著地加快那些进行很多分配和回收的多线程进程的速度。
TCMalloc (Thread-Caching Malloc)
TCMalloc 是 google 开发的开源工具──“google-perftools”中的成员。与标准的 Glibc 库的 malloc 相比,TCMalloc 在内存的分配上效率和速度要高得多。TCMalloc 是一种通用内存管理程序,集成了内存池和垃圾回收的优点。
对于小内存,按 8 的整数次倍分配,对于大内存,按 4K 的整数次倍分配。这样做有两个好处,一是分配的时候比较快,那种提供几十种选择的内存池,往往要遍历一遍各种长度,才能选出合适的种类,而 TCMalloc 则可以简单地做几个运算就行了。二是短期的收益比较大,分配的小内存至多浪费 7 个字节,大内存则 4K。但是长远来说,TCMalloc 分配的种类还是比别的内存池要多很多的,可能会导致复用率很低。
TCMalloc 还有一套高效的机制回收这些空闲的内存。当一个线程的空闲内存比较多的时候,会交还给进程,进程可以把它调配给其他线程使用;如果某种长度交还给进程后,其他线程并没有需求, 进程则把这些长度合并成内存页,然后切割成其他长度。如果进程占据的资源比较多呢,据说不会交回给操作系统。周期性的内存回收,避免可能出现的内存爆炸式增长的问题。TCMalloc 有比较高的空间利用率,只额外花费 1% 的空间。尽量避免加锁(一次加锁解锁约浪费 100ns),使用更高效的 spinlock,采用更合理的粒度。小块内存和打开内存分配采取不同的策略:小于 32K 的被定义为小块内存,小块内存按大小被分为 8Bytes,16Bytes,。。。,236Bytes 进行分级。不是某个级别整数倍的大小都会被分配向上取整。如 13Bytes 的会按 16Bytes 分配,分配时,首先在本线程相应大小级别的空闲链表里面找,如果找到的话可以避免加锁操作(本线程的 cache 只有本线程自己使用)。如果找不到的话,则尝试从中心内存区的相应级别的空闲链表里搬一些对象到本线程的链表。如果中心内存区相应链表也为空的话,则向中心页分配器请求内存页面,然后分割成该级别的对象存储。大块内存处理方式:按页分配,每页大小是 4K,然后内存按 1 页,2 页,……,255 页的大小分类,相同大小的内存块也用链表连接。
TCMalloc 的意义在于,不需要增加任何开发代价,就能使得内存的开销比较少,而且可以从理论上证明,最优的分配不会比 TCMalloc 的分配好很多。
对比 Glibc 可以发现,两者的思想其实是差不多的,差别只是在细节上,细节上的差别,对工程项目来说也是很重要的,至少在性能与内存使用率上 TCMalloc 是领先很多的。Glibc 在内存回收方面做得不太好,常见的一个问题,申请很多内存,然后又释放,只是有一小块没释放,这时候 Glibc 就必须要等待这一小块也释放了,也把整个大块释放,极端情况下,可能会造成几个 G 的浪费。
ptmalloc (glibc 默认内存分配器)
背景介绍
Linux 中 malloc 的早期版本是由 Doug Lea 实现的,它有一个重要问题就是在并行处理时多个线程共享进程的内存空间,各线程可能并发请求内存,在这种情况下应该如何保证分配和回收的正确和高效。
Wolfram Gloger 在 Doug Lea 的基础上改进使得 Glibc 的 malloc 可以支持多线程——ptmalloc,在 glibc-2.3.x 中已经集成了 ptmalloc2,这就是我们平时使用的 malloc,
目前 ptmalloc 的最新版本 ptmalloc3。ptmalloc2 的性能略微比 ptmalloc3 要高一点点。
ptmalloc 实现了 malloc(),free() 以及一组其它的函数. 以提供动态内存管理的支持。分配器处在用户程序和内核之间,它响应用户的分配请求,向操作系统申请内存,然后将其返回给用户程序,为了保持高效的分配,分配器一般都会预先分配一块大于用户请求的内存,并通过某种算法管理这块内存。来满足用户的内存分配要求,用户释放掉的内存也并不是立即就返回给操作系统,相反,分配器会管理这些被释放掉的空闲空间,以应对用户以后的内存分配要求。也就是说,分配器不但要管理已分配的内存块,还需要管理空闲的内存块,当响应用户分配要求时,分配器会首先在空闲空间中寻找一块合适的内存给用户,在空闲空间中找不到的情况下才分配一块新的内存。为实现一个高效的分配器,需要考虑很多的因素。比如,分配器本身管理内存块所占用的内存空间必须很小,分配算法必须要足够的快。
内存管理的设计假设
ptmalloc 在设计时折中了高效率,高空间利用率,高可用性等设计目标。在其实现代码中,隐藏着内存管理中的一些设计假设,由于某些设计假设,导致了在某些情况下 ptmalloc 的行为很诡异。这些设计假设包括:
- 具有长生命周期的大内存分配使用 mmap。
- 特别大的内存分配总是使用 mmap。
- 具有短生命周期的内存分配使用 brk,因为用 mmap 映射匿名页,当发生缺页异常时,linux 内核为缺页分配一个新物理页,并将该物理页清 0,一个 mmap 的内存块需要映射多个物理页,导致多次清 0 操作,很浪费系统资源,所以引入了 mmap 分配阈值动态调整机制,保证在必要的情况下才使用 mmap 分配内存。
- 尽量只缓存临时使用的空闲小内存块,对大内存块或是长生命周期的大内存块在释放时都直接归还给操作系统。
- 对空闲的小内存块只会在 malloc 和 free 的时候进行合并,free 时空闲内存块可能放入 pool 中,不一定归还给操作系统。
- 收缩堆的条件是当前 free 的块大小加上前后能合并 chunk 的大小大于 64KB、,并且堆顶的大小达到阈值,才有可能收缩堆,把堆最顶端的空闲内存返回给操作系统。
- 需要保持长期存储的程序不适合用 ptmalloc 来管理内存。
- 为了支持多线程,多个线程可以从同一个分配区(arena)中分配内存,ptmalloc 假设线程 A 释放掉一块内存后,线程 B 会申请类似大小的内存,但是 A 释放的内存跟 B 需要的内存不一定完全相等,可能有一个小的误差,就需要不停地对内存块作切割和合并,这个过程中可能产生内存碎片。
源码分析
glibc 2.12.1 内存管理 ptmalloc2 源代码分析
mimalloc (microsoft)
- https://github.com/microsoft/mimalloc
- https://github.com/daanx/mimalloc-bench
mimalloc (pronounced “me-malloc”) is a general purpose allocator with excellent performance characteristics. Initially developed by Daan Leijen for the runtime systems of the Koka and Lean languages.
mimalloc is a drop-in replacement for malloc and can be used in other programs without code changes, for example, on dynamically linked ELF-based systems (Linux, BSD, etc.) you can use it as:
> LD_PRELOAD=/usr/lib/libmimalloc.so myprogram
It also includes a robust way to override the default allocator in Windows. Notable aspects of the design include:
mimalloc 的特性可以归纳为以下几点:
- 小巧且一致:库的代码行数约为8k,使用的是简单且一致的数据结构。这使得它非常适合在其他项目中集成和适应。对于运行时系统,它提供了单调心跳和延迟释放的钩子(用于参考计数的有界最坏情况时间)。由于其简单性,mimalloc已经移植到许多系统(Windows, macOS, Linux, WASM, 各种BSD’s, Haiku, MUSL等)并且对动态覆盖有极好的支持。同时,它是一个工业级的分配器,可以在数千台机器上运行(非常)大规模的分布式服务,并具有出色的最坏情况延迟。
- 自由列表分片:我们有许多小的自由列表,每个”mimalloc页面”一个,而不是每个大小类一个大的自由列表。这减少了碎片化并增加了局部性 – 那些在时间上接近的事物在内存中也会被分配得接近。(一个mimalloc页面包含一个大小类的块,通常在64位系统上为64KiB)。
- 自由列表多分片:这是一个大的创新!我们不仅将自由列表按mimalloc页面进行分片,而且每个页面我们都有多个自由列表。特别地,有一个列表用于线程局部的释放操作,另一个用于并发的释放操作。从另一个线程释放现在可以是一个单一的CAS,而不需要复杂的线程之间的协调。由于将有数千个单独的自由列表,竞争自然地分布在堆上,单个位置的竞争机会将会低 – 这与随机算法(如跳跃列表)非常相似,其中添加一个随机预言机可以消除对更复杂算法的需求。
- 热切的页面清理:当一个”页面”变为空(由于自由列表分片的机会增加)时,内存被标记为对操作系统未使用(重置或取消提交),减少了(实际的)内存压力和碎片化,特别是在长时间运行的程序中。
- 安全:mimalloc可以在安全模式下构建,添加保护页,随机分配,加密自由列表等,以防止各种堆漏洞。性能损失通常在我们的基准测试中平均约为10%。
- 一流的堆:有效地创建和使用多个堆,以便在不同的区域进行分配。堆可以一次性销毁,而不是单独释放每个对象。
- 有界:它不会遭受爆炸性增长,有有界的最坏情况分配时间(取决于操作系统原语),有界的空间开销(约0.2%的元数据,内部碎片化低),并且只使用原子操作,没有内部竞争点。
- 快速:在我们的基准测试中(见下文),mimalloc的性能优于其他领先的分配器(jemalloc,tcmalloc,Hoard等),并且通常使用更少的内存。一个好的特性是它在广泛的基准测试中表现始终良好。对于较大的服务器程序,还有很好的巨页操作系统支持。
minimalloc (google)
https://github.com/google/minimalloc
Source code for our ASPLOS 2023 paper, “MiniMalloc: A Lightweight Memory Allocator for Hardware-Accelerated Machine Learning.”
An increasing number of deep learning workloads are being supported by hardware acceleration. In order to unlock the maximum performance of a hardware accelerator, a machine learning model must first be carefully mapped onto its various internal components by way of a compiler. One especially important problem faced by a production-class compiler is that of memory allocation, whereby a set of buffers with predefined lifespans are mapped onto offsets in global memory. Since this allocation is performed statically, the compiler has the freedom to place buffers strategically, but must nevertheless wrestle with a combinatorial explosion in the number of assignment possibilities.
MiniMalloc is a state-of-the-art algorithm designed specifically for static memory allocation that uses several novel search techiques in order to solve such problems efficiently and effectively.
静态内存分配问题主要指在编译期间为数据结构或变量分配内存的过程。在这种情况下,内存分配的大小和位置在程序运行之前就已经确定,因此在程序运行期间不会发生变化。静态内存分配与动态内存分配相对,后者是在程序运行时根据需要动态地分配和释放内存。
静态内存分配问题涉及以下方面:
- 内存布局:编译器需要确定如何在内存中布局数据结构和变量,以便在运行时可以高效地访问它们。这可能涉及到对齐、填充和数据结构的顺序等方面的考虑。
- 内存使用优化:编译器需要在有限的内存空间中尽可能有效地分配内存。这可能涉及到合并具有不重叠生命周期的变量、消除冗余填充以及选择合适的内存分配策略等。
- 生命周期分析:编译器需要确定数据结构和变量的生命周期,以便知道何时可以重用其内存。这可以通过静态分析技术来实现,例如数据流分析、活跃变量分析等。
MiniMalloc 算法,主要关注于解决静态内存分配过程中的内存布局和内存使用优化问题。通过利用 canonical solutions、空间推理技术和支配解的检测与消除等技术,MiniMalloc 能够高效地找到合适的内存分配方案,从而提高硬件加速器在运行深度学习工作负载时的性能。
malloc / free / calloc / realloc / reallocarray - allocate and free dynamic memory
#include <stdlib.h>
void *malloc(size_t size);
void free(void *ptr);
void *calloc(size_t nmemb, size_t size);
void *realloc(void *ptr, size_t size);
void *reallocarray(void *ptr, size_t nmemb, size_t size);
Note
By default, Linux follows an optimistic memory allocation strategy. This means that when malloc() returns non-NULL there is no guarantee that the memory really is available. In case it turns out that the system is out of memory, one or more processes will be killed by the OOM killer.
For more information, see the description of /proc/sys/vm/overcommit_memory and /proc/sys/vm/oom_adj in proc(5), and the Linux kernel source file Documentation/vm/overcommit-accounting.rst.
Normally, malloc() allocates memory from the heap, and adjusts the size of the heap as required, using sbrk(2).
MMAP_THRESHOLD is 128 kB by default
When allocating blocks of memory larger than MMAP_THRESHOLD bytes, the glibc malloc() implementation allocates the memory as a private
anonymous mapping using mmap(2). MMAP_THRESHOLD is 128 kB by default, but is adjustable using mallopt(3).
多线程分配内存竞争
To avoid corruption in multithreaded applications, mutexes are used internally to protect the memory-management data structures employed by these functions. In a multithreaded application in which threads simultaneously allocate and free memory, there could be contention for these mutexes. To scalably handle memory allocation in multithreaded applications, glibc creates additional memory allocation arenas if mutex contention is detected. Each arena is a large region of memory that is internally allocated by the system (using brk(2) or mmap(2)), and managed with its own mutexes.
自定义实现 malloc / free
If your program uses a private memory allocator, it should do so by replacing malloc(), free(), calloc(), and realloc().
The replacement functions must implement the documented glibc behaviors, including errno handling, size-zero allocations, and overflow checking; otherwise, other library routines may crash or operate incorrectly.
For example, if the replacement free() does not preserve errno, then seemingly unrelated library routines may fail without having a valid reason in errno. Private memory allocators may also need to replace other glibc functions; see “Replacing malloc” in the glibc manual for details.
Crash 的原因
Crashes in memory allocators are almost always related to heap corruption, such as overflowing an allocated chunk or freeing the same pointer twice.
malloc()
The malloc() function allocates size bytes and returns a pointer to the allocated memory. The memory is not initialized. If size
is 0, then malloc() returns a unique pointer value that can later be successfully passed to free(). (See “Nonportable behavior”
for portability issues.)
free()
The free() function frees the memory space pointed to by ptr, which must have been returned by a previous call to malloc() or related functions. Otherwise, or if ptr has already been freed, undefined behavior occurs. If ptr is NULL, no operation is performed.
calloc()
The calloc() function allocates memory for an array of nmemb elements of size bytes each and returns a pointer to the
allocated memory. The memory is set to zero. If nmemb or size is 0, then calloc() returns a unique pointer value that can later
be successfully passed to free().
If the multiplication of nmemb and size would result in integer overflow, then calloc() returns an error. By contrast, an
integer overflow would not be detected in the following call to malloc(), with the result that an incorrectly sized block of memory would be allocated:
malloc(nmemb * size);
realloc()
The realloc() function changes the size of the memory block pointed to by ptr to size bytes. The contents of the memory will
be unchanged in the range from the start of the region up to the minimum of the old and new sizes. If the new size is larger than the old size, the added memory will not be initialized.
If ptr is NULL, then the call is equivalent to malloc(size), for all values of size.
If size is equal to zero, and ptr is not NULL, then the call is equivalent to free(ptr) (but see “Nonportable behavior” for portability issues).
Unless ptr is NULL, it must have been returned by an earlier call to malloc or related functions. If the area pointed to was moved, a free(ptr) is done.
reallocarray()
The reallocarray() function changes the size of (and possibly moves) the memory block pointed to by ptr to be large enough for an array of nmemb elements, each of which is size bytes. It is equivalent to the call
realloc(ptr, nmemb * size);
However, unlike that realloc() call, reallocarray() fails safely in the case where the multiplication would overflow. If such an overflow occurs, reallocarray() returns an error.
#include <err.h>
#include <stddef.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define MALLOCARRAY(n, type) ((type *) my_mallocarray(n, sizeof(type)))
#define MALLOC(type) MALLOCARRAY(1, type)
static inline void *my_mallocarray(size_t nmemb, size_t size);
int
main(void)
{
char *p;
p = MALLOCARRAY(32, char);
if (p == NULL)
err(EXIT_FAILURE, "malloc");
strlcpy(p, "foo", 32);
puts(p);
}
static inline void *
my_mallocarray(size_t nmemb, size_t size)
{
return reallocarray(NULL, nmemb, size);
}
mallopt
mallopt() 函数用于设置 glibc 内存分配器(ptmalloc)的参数。以下是一个简单的使用示例,展示了如何使用 mallopt() 设置内存分配器的参数。
#include <stdio.h>
#include <stdlib.h>
#include <malloc.h>
int main() {
// 设置内存分配器参数
int trim_threshold = 128 * 1024; // 128 KB
int mmap_threshold = 64 * 1024; // 64 KB
if (mallopt(M_TRIM_THRESHOLD, trim_threshold) == 0) {
fprintf(stderr, "Failed to set M_TRIM_THRESHOLD\n");
exit(EXIT_FAILURE);
}
if (mallopt(M_MMAP_THRESHOLD, mmap_threshold) == 0) {
fprintf(stderr, "Failed to set M_MMAP_THRESHOLD\n");
exit(EXIT_FAILURE);
}
printf("M_TRIM_THRESHOLD set to %d bytes\n", trim_threshold);
printf("M_MMAP_THRESHOLD set to %d bytes\n", mmap_threshold);
// 在此处执行内存分配和释放操作
return 0;
}
这个示例程序使用 mallopt() 函数设置了两个内存分配器参数:
M_TRIM_THRESHOLD:释放内存时,内存分配器将空闲内存归还给操作系统的阈值。在本示例中,将阈值设置为 128 KB。M_MMAP_THRESHOLD:内存分配器使用mmap()分配内存而不是sbrk()的阈值。在本示例中,将阈值设置为 64 KB。
brk, sbrk - change data segment size
#include <unistd.h>
int brk(void *addr);
void *sbrk(intptr_t increment);
brk() and sbrk() change the location of the program break, which defines the end of the process’s data segment (i.e., the program break is the first location after the end of the uninitialized data segment). Increasing the program break has the effect of allocating memory to the process; decreasing the break deallocates memory.
brk() sets the end of the data segment to the value specified by addr, when that value is reasonable, the system has enough memory, and the process does not exceed its maximum data size (see setrlimit(2)).
sbrk() increments the program’s data space by increment bytes. Calling sbrk() with an increment of 0 can be used to find the current location of the program break.
Avoid using brk() and sbrk(): the malloc(3) memory allocation package is the portable and comfortable way of allocating memory.
以下是 brk() 和 sbrk() 的使用原理:
brk()函数将程序断点设置为指定的地址。如果新地址比当前程序断点更高,堆将增加,从而分配内存。如果新地址比当前程序断点更低,堆将减小,从而释放内存。sbrk()函数通过指定的字节数增加或减少程序断点。正值会增加堆大小,从而分配内存;负值会减小堆大小,从而释放内存。将 increment 设置为 0 并调用sbrk()可以获取当前程序断点的位置。
代码示例
#include <stdio.h>
#include <unistd.h>
int main()
{
// 获取当前程序断点位置
void *current_break = sbrk(0);
printf("Current program break: %p\n", current_break);
// 分配内存(增加堆大小)
int increment = 4096; // 4KB
void *allocated_memory = sbrk(increment);
printf("Allocated memory: %p\n", allocated_memory);
// 获取新的程序断点位置
void *new_break = sbrk(0);
printf("New program break: %p\n", new_break);
// 释放内存(减小堆大小)
sbrk(-increment);
// 获取释放内存后的程序断点位置
void *final_break = sbrk(0);
printf("Final program break: %p\n", final_break);
return 0;
}
输出:
Current program break: 0x1125000
Allocated memory: 0x1125000
New program break: 0x1126000
Final program break: 0x1125000
mmap - map or unmap files or devices into memory
#include <sys/mman.h>
void *mmap(void addr[.length], size_t length, int prot, int flags, int fd, off_t offset);
int munmap(void addr[.length], size_t length);
mmap() creates a new mapping in the virtual address space of the calling process. The starting address for the new mapping is specified in addr. The length argument specifies the length of the mapping (which must be greater than 0).
代码示例
The following program prints part of the file specified in its first command-line argument to standard output. The range of bytes to be printed is specified via offset and length values in the second and third command-line arguments. The program creates a memory mapping of the required pages of the file and then uses write(2) to output the desired bytes.
#include <fcntl.h>
#include <stdio.h>
#include <stdlib.h>
#include <sys/mman.h>
#include <sys/stat.h>
#include <unistd.h>
#define handle_error(msg) \
do { perror(msg); exit(EXIT_FAILURE); } while (0)
int
main(int argc, char *argv[])
{
int fd;
char *addr;
off_t offset, pa_offset;
size_t length;
ssize_t s;
struct stat sb;
if (argc < 3 || argc > 4) {
fprintf(stderr, "%s file offset [length]\n", argv[0]);
exit(EXIT_FAILURE);
}
fd = open(argv[1], O_RDONLY);
if (fd == -1)
handle_error("open");
if (fstat(fd, &sb) == -1) /* To obtain file size */
handle_error("fstat");
offset = atoi(argv[2]);
pa_offset = offset & ~(sysconf(_SC_PAGE_SIZE) - 1);
/* offset for mmap() must be page aligned */
if (offset >= sb.st_size) {
fprintf(stderr, "offset is past end of file\n");
exit(EXIT_FAILURE);
}
if (argc == 4) {
length = atoi(argv[3]);
if (offset + length > sb.st_size)
length = sb.st_size - offset;
/* Can't display bytes past end of file */
} else { /* No length arg ==> display to end of file */
length = sb.st_size - offset;
}
addr = mmap(NULL, length + offset - pa_offset, PROT_READ,
MAP_PRIVATE, fd, pa_offset);
if (addr == MAP_FAILED)
handle_error("mmap");
s = write(STDOUT_FILENO, addr + offset - pa_offset, length);
if (s != length) {
if (s == -1)
handle_error("write");
fprintf(stderr, "partial write");
exit(EXIT_FAILURE);
}
munmap(addr, length + offset - pa_offset);
close(fd);
exit(EXIT_SUCCESS);
}
madvise - give advice about use of memory
madvise() 函数用于向内核提供关于程序如何使用内存映射区域的建议。
#include <sys/mman.h>
int madvise(void addr[.length], size_t length, int advice);
The madvise() system call is used to give advice or directions to the kernel about the address range beginning at address addr and
with size length. madvise() only operates on whole pages, therefore addr must be page-aligned.
The value of length is rounded up to a multiple of page size. In most cases, the goal of such advice is to improve system or application performance.
Initially, the system call supported a set of “conventional” advice values, which are also available on several other implementations. (Note, though, that madvise() is not specified in POSIX.) Subsequently, a number of Linux-specific advice values have been added.
Conventional advice values
The advice values listed below allow an application to tell the kernel how it expects to use some mapped or shared memory areas, so that the kernel can choose appropriate read-ahead and caching techniques.
These advice values do not influence the semantics of the application (except in the case of MADV_DONTNEED), but may influence its performance. All of the advice values listed here have analogs in the POSIX-specified posix_madvise(3) function, and the values have the same meanings, with the exception of MADV_DONTNEED.
The advice is indicated in the advice argument, which is one of the following:
- MADV_NORMAL: No special treatment. This is the default.
- MADV_RANDOM: Expect page references in random order. (Hence, read ahead may be less useful than normally.)
- MADV_SEQUENTIAL: Expect page references in sequential order. (Hence, pages in the given range can be aggressively read ahead, and may be freed soon after they are accessed.)
-
MADV_WILLNEED: Expect access in the near future. (Hence, it might be a good idea to read some pages ahead.)
- MADV_DONTNEED: Do not expect access in the near future. (For the time being, the application is finished with the given range, so the kernel can free resources associated with it.)
Note that, when applied to shared mappings, MADV_DONTNEED might not lead to immediate freeing of the pages in the range. The kernel is free to delay freeing the pages until an appropriate moment. The resident set size (RSS) of the calling process will be immediately reduced however.
代码示例
#include <stdio.h>
#include <stdlib.h>
#include <fcntl.h>
#include <sys/mman.h>
#include <sys/stat.h>
#include <unistd.h>
int main(int argc, char *argv[]) {
if (argc != 2) {
fprintf(stderr, "Usage: %s <file>\n", argv[0]);
exit(EXIT_FAILURE);
}
// 打开文件
int fd = open(argv[1], O_RDONLY);
if (fd == -1) {
perror("open");
exit(EXIT_FAILURE);
}
// 获取文件大小
struct stat sb;
if (fstat(fd, &sb) == -1) {
perror("fstat");
exit(EXIT_FAILURE);
}
// 将文件映射到内存
char *mapped = (char*)mmap(NULL, sb.st_size, PROT_READ, MAP_PRIVATE, fd, 0);
if (mapped == MAP_FAILED) {
perror("mmap");
exit(EXIT_FAILURE);
}
// 通知内核我们将顺序访问此内存映射区域
if (madvise(mapped, sb.st_size, MADV_SEQUENTIAL) == -1) {
perror("madvise");
exit(EXIT_FAILURE);
}
// 逐行处理内存映射区域(例如读取文件内容并输出到标准输出)
size_t start = 0;
for (size_t i = 0; i < sb.st_size; i++) {
if (mapped[i] == '\n') {
fwrite(mapped + start, sizeof(char), i - start, stdout);
printf("\n");
start = i + 1;
}
}
// 输出最后一行(如果没有以换行符结尾)
if (start < sb.st_size) {
fwrite(mapped + start, sizeof(char), sb.st_size - start, stdout);
printf("\n");
}
// 取消内存映射
if (munmap(mapped, sb.st_size) == -1) {
perror("munmap");
exit(EXIT_FAILURE);
}
// 关闭文件
close(fd);
return 0;
}
输出:
$cat data.txt
hello
$./a.out data.txt
hello
malloc_info - export malloc state to a stream
#include <malloc.h>
int malloc_info(int options, FILE *stream);
The malloc_info() function exports an XML string that describes the current state of the memory-allocation implementation in the caller. The string is printed on the file stream stream. The exported string includes information about all arenas (see malloc(3)).
As currently implemented, options must be zero.
On success, malloc_info() returns 0. On failure, it returns -1, and errno is set to indicate the error.
代码示例
该程序接受最多四个命令行参数,其中前三个参数是必需的。
- 第一个参数:指定程序应创建的线程数。
- 第二个参数:指定所有线程(包括主线程)应分配的内存块数量。
- 第三个参数:控制要分配的内存块的大小。主线程创建这个大小的内存块,程序创建的第二个线程分配两倍于这个大小的内存块,第三个线程分配三倍于这个大小的内存块,以此类推。
程序会调用 malloc_info() 两次来显示内存分配状态:
- 第一次调用发生在创建任何线程或分配任何内存之前。
- 第二次调用发生在所有线程分配内存之后。
在给出的示例中,命令行参数指定创建一个额外的线程,主线程和额外线程都分配 10000 个内存块。在分配内存块后,malloc_info() 显示了两个分配区域的状态。
这个程序的目的是展示多线程环境下内存分配的状态,以及如何使用 malloc_info() 函数来查看内存分配情况。通过观察 malloc_info() 的输出,可以了解程序中不同线程的内存使用情况,并分析内存分配器的工作原理。这对于优化内存使用和排查内存相关问题非常有帮助。
#include <err.h>
#include <errno.h>
#include <malloc.h>
#include <pthread.h>
#include <stdlib.h>
#include <unistd.h>
static size_t blockSize;
static size_t numThreads;
static unsigned int numBlocks;
static void * thread_func(void *arg)
{
size_t tn = (size_t) arg;
/*The multiplier '(2 + tn)' ensures that each thread (including
the main thread) allocates a different amount of memory. */
for (unsigned int j = 0; j < numBlocks; j++)
if (malloc(blockSize *(2 + tn)) == NULL)
err(EXIT_FAILURE, "malloc-thread");
sleep(100); /*Sleep until main thread terminates. */
return NULL;
}
int main(int argc, char *argv[])
{
int sleepTime;
pthread_t * thr;
if (argc < 4)
{
fprintf(stderr,
"%s num-threads num-blocks block-size[sleep-time]\n",
argv[0]);
exit(EXIT_FAILURE);
}
numThreads = atoi(argv[1]);
numBlocks = atoi(argv[2]);
blockSize = atoi(argv[3]);
sleepTime = (argc > 4) ? atoi(argv[4]) : 0;
thr = (pthread_t*) calloc(numThreads, sizeof(*thr));
if (thr == NULL)
err(EXIT_FAILURE, "calloc");
printf("============ Before allocating blocks ============\n");
malloc_info(0, stdout);
/*Create threads that allocate different amounts of memory. */
for (size_t tn = 0; tn < numThreads; tn++)
{
errno = pthread_create(&thr[tn], NULL, thread_func,
(void*) tn);
if (errno != 0)
err(EXIT_FAILURE, "pthread_create");
/*If we add a sleep interval after the start-up of each
thread, the threads likely won't contend for malloc
mutexes, and therefore additional arenas won't be
allocated (see malloc(3)). */
if (sleepTime > 0)
sleep(sleepTime);
}
/*The main thread also allocates some memory. */
for (unsigned int j = 0; j < numBlocks; j++)
if (malloc(blockSize) == NULL)
err(EXIT_FAILURE, "malloc");
sleep(2);
/*Give all threads a chance to complete allocations. */
printf("\n============ After allocating blocks ============\n");
malloc_info(0, stdout);
exit(EXIT_SUCCESS);
}
输出:
$getconf GNU_LIBC_VERSION
glibc 2.18
$./a.out 1 10000 100
============ Before allocating blocks ============
<malloc version="1">
<heap nr="0">
<sizes>
</sizes>
<total type="fast" count="0" size="0"/>
<total type="rest" count="0" size="0"/>
<system type="current" size="135168"/>
<system type="max" size="135168"/>
<aspace type="total" size="135168"/>
<aspace type="mprotect" size="135168"/>
</heap>
<total type="fast" count="0" size="0"/>
<total type="rest" count="0" size="0"/>
<system type="current" size="135168"/>
<system type="max" size="135168"/>
<aspace type="total" size="135168"/>
<aspace type="mprotect" size="135168"/>
</malloc>
============ After allocating blocks ============
<malloc version="1">
<heap nr="0">
<sizes>
</sizes>
<total type="fast" count="0" size="0"/>
<total type="rest" count="0" size="0"/>
<system type="current" size="1216512"/>
<system type="max" size="1216512"/>
<aspace type="total" size="1216512"/>
<aspace type="mprotect" size="1216512"/>
</heap>
<heap nr="1">
<sizes>
</sizes>
<total type="fast" count="0" size="0"/>
<total type="rest" count="0" size="0"/>
<system type="current" size="2084864"/>
<system type="max" size="2084864"/>
<aspace type="total" size="2084864"/>
<aspace type="mprotect" size="2084864"/>
</heap>
<total type="fast" count="0" size="0"/>
<total type="rest" count="0" size="0"/>
<system type="current" size="3301376"/>
<system type="max" size="3301376"/>
<aspace type="total" size="3301376"/>
<aspace type="mprotect" size="3301376"/>
</malloc>
malloc_stats - print memory allocation statistics
The malloc_stats() function prints (on standard error) statistics about memory allocated by malloc(3) and related functions. For each arena (allocation area), this function prints the total amount of memory allocated and the total number of bytes consumed by in-use allocations. (These two values correspond to the arena and uordblks fields retrieved by mallinfo(3).)
In addition, the function prints the sum of these two statistics for all arenas, and the maximum number of blocks and bytes that were ever simultaneously allocated using mmap(2).
代码示例
#include <stdio.h>
#include <stdlib.h>
#include <malloc.h>
int main() {
printf("Initial malloc_stats:\n");
malloc_stats(); // 输出初始的内存分配状态
const int num_allocs = 10;
const int block_size = 1024; // 1 KB
// 分配内存
void *blocks[num_allocs];
for (int i = 0; i < num_allocs; i++) {
blocks[i] = malloc(block_size);
}
printf("\nmalloc_stats after allocations:\n");
malloc_stats(); // 输出分配内存后的内存分配状态
// 释放内存
for (int i = 0; i < num_allocs; i++) {
free(blocks[i]);
}
printf("\nmalloc_stats after freeing memory:\n");
malloc_stats(); // 输出释放内存后的内存分配状态
return 0;
}
输出:
Initial malloc_stats:
Arena 0:
system bytes = 0
in use bytes = 0
Total (incl. mmap):
system bytes = 0
in use bytes = 0
max mmap regions = 0
max mmap bytes = 0
malloc_stats after allocations:
Arena 0:
system bytes = 135168
in use bytes = 10400
Total (incl. mmap):
system bytes = 135168
in use bytes = 10400
max mmap regions = 0
max mmap bytes = 0
malloc_stats after freeing memory:
Arena 0:
system bytes = 135168
in use bytes = 0
Total (incl. mmap):
system bytes = 135168
in use bytes = 0
max mmap regions = 0
max mmap bytes = 0
将分配内存大小改为 1 MB,内存将改为 mmap 分配而不是 brk 分配,如下输出信息所示。
const int num_allocs = 10;
const int block_size = 1024 * 1024; // 1 MB
Initial malloc_stats:
Arena 0:
system bytes = 0
in use bytes = 0
Total (incl. mmap):
system bytes = 0
in use bytes = 0
max mmap regions = 0
max mmap bytes = 0
malloc_stats after allocations:
Arena 0:
system bytes = 0
in use bytes = 0
Total (incl. mmap):
system bytes = 10526720
in use bytes = 10526720
max mmap regions = 10
max mmap bytes = 10526720
malloc_stats after freeing memory:
Arena 0:
system bytes = 0
in use bytes = 0
Total (incl. mmap):
system bytes = 0
in use bytes = 0
max mmap regions = 10
max mmap bytes = 10526720
添加 malloc_trim 测试回收 glibc 缓存:
#include <stdio.h>
#include <stdlib.h>
#include <malloc.h>
int main() {
printf("Initial malloc_stats:\n");
malloc_stats(); // 输出初始的内存分配状态
const int num_allocs = 10;
const int block_size = 1024; // 1 kB
// 分配内存
void *blocks[num_allocs];
for (int i = 0; i < num_allocs; i++) {
blocks[i] = malloc(block_size);
}
printf("\nmalloc_stats after allocations:\n");
malloc_stats(); // 输出分配内存后的内存分配状态
// 释放内存
for (int i = 0; i < num_allocs; i++) {
free(blocks[i]);
}
printf("\nmalloc_stats after freeing memory:\n");
malloc_stats(); // 输出释放内存后的内存分配状态
malloc_trim(0);
printf("\nmalloc_stats after malloc_trim:\n");
malloc_stats(); // 输出释放内存后的内存分配状态
return 0;
}
输出:
$getconf -a | grep GNU_LIBC
GNU_LIBC_VERSION glibc 2.18
$./a.out
Initial malloc_stats:
Arena 0:
system bytes = 0
in use bytes = 0
Total (incl. mmap):
system bytes = 0
in use bytes = 0
max mmap regions = 0
max mmap bytes = 0
malloc_stats after allocations:
Arena 0:
system bytes = 135168
in use bytes = 10400
Total (incl. mmap):
system bytes = 135168
in use bytes = 10400
max mmap regions = 0
max mmap bytes = 0
malloc_stats after freeing memory:
Arena 0:
system bytes = 135168
in use bytes = 0
Total (incl. mmap):
system bytes = 135168
in use bytes = 0
max mmap regions = 0
max mmap bytes = 0
malloc_stats after malloc_trim:
Arena 0:
system bytes = 4096
in use bytes = 0
Total (incl. mmap):
system bytes = 4096
in use bytes = 0
max mmap regions = 0
max mmap bytes = 0
malloc_trim - release free memory from the heap
#include <malloc.h>
int malloc_trim(size_t pad);
The malloc_trim() function attempts to release free memory from the heap (by calling sbrk(2) or madvise(2) with suitable arguments).
The pad argument specifies the amount of free space to leave untrimmed at the top of the heap. If this argument is 0, only the minimum amount of memory is maintained at the top of the heap (i.e., one page or less). A nonzero argument can be used to maintain some trailing space at the top of the heap in order to allow future allocations to be made without having to extend the heap with sbrk(2).
原理介绍
malloc_trim() 函数用于释放 glibc 内存分配器(通常是 malloc、calloc、realloc 等函数的底层实现)管理的空闲内存。内存分配器通常会在堆中维护空闲内存块,以便在应用程序需要时快速分配内存。当应用程序释放内存(例如通过 free 函数)时,这些内存可能不会立即返回给操作系统,而是由内存分配器保存以备后续分配。
malloc_trim() 函数的释放原理如下:
-
malloc_trim() 遍历内存分配器管理的空闲内存块列表,查找可以合并的相邻空闲内存块。
-
将合并后的大块空闲内存返回给操作系统。这通常通过调整程序断点(program break)的位置来完成。程序断点定义了堆的结束位置。通过减小程序断点,可以将空闲内存返回给操作系统。在某些系统上,malloc_trim() 还可能使用 madvise() 系统调用来释放内存,通知操作系统可以回收某些内存区域。
-
malloc_trim() 函数接受一个名为 pad 的参数,该参数指定了在堆顶部保留的未削减的空闲空间量。将 pad 设置为 0 可以尽可能多地释放内存,而将其设置为非零值可以在优化性能的同时保留一定的空闲空间。
需要注意的是,malloc_trim() 主要用于释放内存分配器管理的内存。它不会释放通过 mmap 分配的内存空间。对于 mmap 分配的内存,应使用 munmap 函数进行释放。
总之,malloc_trim() 函数通过遍历内存分配器管理的空闲内存块列表、合并相邻空闲内存块并调整程序断点(或使用 madvise() ),从而释放内存并将其返回给操作系统。
Note
只有主堆(使用 sbrk(2) )遵循 pad 参数;线程堆则不遵循。这意味着,在多线程环境中,malloc_trim() 函数对主堆的影响可能会受到 pad 参数的限制,但对线程堆的影响则不受此限制。
从 glibc 2.8 开始,malloc_trim() 函数可以释放所有区域(arenas)中的内存,以及包含整个空闲页的所有内存块。这意味着,在 glibc 2.8 及更高版本中,malloc_trim() 函数可以更有效地释放不同区域和内存块中的空闲内存。
在 glibc 2.8 之前,malloc_trim() 函数仅释放主区域(main arena)堆顶部的内存。这意味着,在早期的 glibc 版本中,malloc_trim() 函数可能无法释放主区域以外的空闲内存。
代码示例
#include <stdio.h>
#include <stdlib.h>
#include <malloc.h>
void print_malloc_info()
{
// 输出到stdout的malloc_info()
malloc_info(0, stdout);
}
int main()
{
const int num_allocs = 100;
const int block_size = 1024 * 1024; // 1 MB
//const int block_size = 16; // 16 B
printf("Initial malloc_info:\n");
print_malloc_info();
// 分配内存
void *blocks[num_allocs];
for (int i = 0; i < num_allocs; i++)
{
blocks[i] = malloc(block_size);
}
printf("\nmalloc_info after malloc some memory:\n");
print_malloc_info();
// 释放一部分内存
for (int i = 0; i < num_allocs; i += 2)
{
free(blocks[i]);
}
printf("\nmalloc_info after freeing some memory:\n");
print_malloc_info();
// 调用malloc_trim()尝试释放内存分配器保留的空闲内存
int result = malloc_trim(0);
if (result == 1)
{
printf("malloc_trim() successfully trimmed memory.\n");
}
else
{
printf("malloc_trim() did not trim any memory.\n");
}
printf("\nmalloc_info after malloc_trim():\n");
print_malloc_info();
// 释放剩余内存
for (int i = 1; i < num_allocs; i += 2)
{
free(blocks[i]);
}
return 0;
}
当 block_size 大小为 1MB 时, malloc_info 输出的信息为 0,将 block_size 大小改为 16B 后,malloc_info 输出的内存信息不为 0,说明内存分配器实际分配了这些较小的内存块,并将其纳入内存管理。这种情况下,malloc_trim() 可能会在释放这些较小内存块时表现出不同的行为。
block_size 大小改为 16B 后的输出信息:
Initial malloc_info:
<malloc version="1">
<heap nr="0">
<sizes>
</sizes>
<total type="fast" count="0" size="0"/>
<total type="rest" count="0" size="0"/>
<system type="current" size="0"/>
<system type="max" size="0"/>
<aspace type="total" size="0"/>
<aspace type="mprotect" size="0"/>
</heap>
<total type="fast" count="0" size="0"/>
<total type="rest" count="0" size="0"/>
<system type="current" size="0"/>
<system type="max" size="0"/>
<aspace type="total" size="0"/>
<aspace type="mprotect" size="0"/>
</malloc>
malloc_info after malloc some memory:
<malloc version="1">
<heap nr="0">
<sizes>
</sizes>
<total type="fast" count="0" size="0"/>
<total type="rest" count="0" size="0"/>
<system type="current" size="135168"/>
<system type="max" size="135168"/>
<aspace type="total" size="135168"/>
<aspace type="mprotect" size="135168"/>
</heap>
<total type="fast" count="0" size="0"/>
<total type="rest" count="0" size="0"/>
<system type="current" size="135168"/>
<system type="max" size="135168"/>
<aspace type="total" size="135168"/>
<aspace type="mprotect" size="135168"/>
</malloc>
malloc_info after freeing some memory:
<malloc version="1">
<heap nr="0">
<sizes>
<size from="17" to="32" total="1600" count="50"/>
</sizes>
<total type="fast" count="50" size="1600"/>
<total type="rest" count="0" size="0"/>
<system type="current" size="135168"/>
<system type="max" size="135168"/>
<aspace type="total" size="135168"/>
<aspace type="mprotect" size="135168"/>
</heap>
<total type="fast" count="50" size="1600"/>
<total type="rest" count="0" size="0"/>
<system type="current" size="135168"/>
<system type="max" size="135168"/>
<aspace type="total" size="135168"/>
<aspace type="mprotect" size="135168"/>
</malloc>
malloc_trim() successfully trimmed memory.
malloc_info after malloc_trim():
<malloc version="1">
<heap nr="0">
<sizes>
<unsorted from="0" to="33" total="1650" count="50"/>
</sizes>
<total type="fast" count="0" size="0"/>
<total type="rest" count="50" size="1650"/>
<system type="current" size="4096"/>
<system type="max" size="135168"/>
<aspace type="total" size="4096"/>
<aspace type="mprotect" size="4096"/>
</heap>
<total type="fast" count="0" size="0"/>
<total type="rest" count="50" size="1650"/>
<system type="current" size="4096"/>
<system type="max" size="135168"/>
<aspace type="total" size="4096"/>
<aspace type="mprotect" size="4096"/>
</malloc>
在 malloc_info 输出中,malloc_trim() 调用后 fast 类型的内存计数变为 0,而 rest 类型的内存计数增加了相应的数量。这是因为 malloc_trim() 在合并空闲内存块时可能会将一些 fast 类型的内存块合并为较大的内存块,从而将它们归类为 rest 类型的内存。
需要注意的是,malloc_trim() 的实际效果可能因系统和内存分配器的实现而异。在某些情况下,malloc_trim() 可能无法释放任何内存,或者只能释放部分内存。要准确分析内存使用情况,您可能需要结合其他工具(如top、free等)和方法。
Allocator (标准库分配器)
Encapsulates strategies for access/addressing, allocation/deallocation and construction/destruction of objects.
分配器,封装了内存分配、释放、对象构造和析构的策略。它被许多标准库组件使用,包括容器如 std::vector、std::map 和 std::unordered_map,以及智能指针如 std::shared_ptr。
为了能够与标准库组件一起使用,分配器必须满足一定的要求。这些要求包括提供 allocate 和 deallocate 成员函数用于内存分配和释放,以及 construct 和 destroy 成员函数用于对象构造和析构。此外,分配器必须是可复制和可赋值的,并且必须提供一个 rebind 成员模板,用于创建不同类型的分配器。
通过使用分配器,标准库组件可以定制使用不同的内存分配策略,例如使用自定义的内存池或不同的内存分配算法。这在某些情况下非常有用,例如在高性能计算应用程序中优化性能时。
许多分配器的要求是可选的,因为包括标准库容器在内的所有分配器感知类都是通过 std::allocator_traits 间接访问分配器的,而 std::allocator_traits 提供了这些要求的默认实现。
例如,std::allocator_traits 为 allocate 和 deallocate 成员函数提供了默认实现,这些函数只是调用分配器对象上对应的函数。类似地,std::allocator_traits 为 construct 和 destroy 成员函数提供了默认实现,分别使用放置 new 和显式析构函数调用。
通过使用 std::allocator_traits,分配器感知类可以以与使用的特定分配器类型无关的方式编写。这允许代码具有更大的灵活性和可重用性,因为可以使用不同的分配器类型与相同的分配器感知类交换使用。
代码示例:
#include <cstdlib>
#include <new>
#include <limits>
#include <iostream>
#include <vector>
template<class T>
struct Mallocator
{
typedef T value_type;
Mallocator () = default;
template<class U>
constexpr Mallocator (const Mallocator <U>&) noexcept {}
[[nodiscard]] T* allocate(std::size_t n)
{
if (n > std::numeric_limits<std::size_t>::max() / sizeof(T))
throw std::bad_array_new_length();
if (auto p = static_cast<T*>(std::malloc(n * sizeof(T))))
{
report(p, n);
return p;
}
throw std::bad_alloc();
}
void deallocate(T* p, std::size_t n) noexcept
{
report(p, n, 0);
std::free(p);
}
private:
void report(T* p, std::size_t n, bool alloc = true) const
{
std::cout << (alloc ? "Alloc: " : "Dealloc: ") << sizeof(T) * n
<< " bytes at " << std::hex << std::showbase
<< reinterpret_cast<void*>(p) << std::dec << '\n';
}
};
template<class T, class U>
bool operator==(const Mallocator <T>&, const Mallocator <U>&) { return true; }
template<class T, class U>
bool operator!=(const Mallocator <T>&, const Mallocator <U>&) { return false; }
int main()
{
std::vector<int, Mallocator<int>> v(8);
v.push_back(42);
}
Alloc: 32 bytes at 0x2020c20
Alloc: 64 bytes at 0x2023c60
Dealloc: 32 bytes at 0x2020c20
Dealloc: 64 bytes at 0x2023c60
问题描述
#include <iostream>
class A
{
public:
A() { std::cout << "A()\n"; }
virtual ~A() { std::cout << "~A()\n"; }
int a[5];
};
class B
{
public:
B() { std::cout << "B()\n"; }
virtual ~B() { std::cout << "~B()\n"; }
int b;
};
class C : public A, public B
{
public:
C() { std::cout << "C()\n"; }
~C() { std::cout << "~C()\n"; }
int c;
};
int main()
{
C* pC = new C();
std::cout << "pC: " << pC << std::endl;
A* pA = pC;
std::cout << "pA: " << pA << std::endl;
B* pB = pC;
std::cout << "pB: " << pB << std::endl;
delete pB; // ok?
}
/*
A()
B()
C()
pC: 0x8fbeb0
pA: 0x8fbeb0
pB: 0x8fbed0
~C()
~B()
~A()
*/
通过基类指针释放对象
问题描述
class Base;
class Derived;
Base *b = MY_NEW(Derived);
MY_DELETE(b); // error, 释放的是基类的长度
MY_DELETE(Derived(b)); // ok,需要显式转换为子类类型
如何不需要指定类型转换,且保证底层回收的内存长度是正确的?
例子:显示调用子类 MY_DELETE_IGNORE_VIRTUAL(obj2),即,Derived(b)的形式,可以不依赖虚函数
#include <iostream>
#include <type_traits>
#define MY_NEW(Type, ...) MyNew<Type>(__VA_ARGS__)
#define MY_DELETE(ptr) MyDelete(ptr)
#define MY_DELETE_IGNORE_VIRTUAL(ptr) MyDeleteIngoreVirtual(ptr)
template<bool HAS_VIRTUAL_DESTRUCTOR>
struct STDeleteInfo
{
template<typename T>
inline static void* Get(T* ptr, size_t& uSize)
{
//std::cout << "ptr: " << ptr << std::endl;
return ptr->VirtualDeleteInfo(uSize);
}
};
template<>
struct STDeleteInfo<false>
{
template<typename T>
inline static void* Get(T* ptr, size_t& uSize)
{
uSize = sizeof(T);
return ptr;
}
};
template<typename Type>
Type* MyNew()
{
void* ptr = malloc(sizeof(Type));
std::cout << "Allocate ptr: " << ptr << ", size: " << sizeof(Type) << std::endl;
new (ptr) Type;
return (Type*)ptr;
}
template<typename Type>
void MyDelete(Type* ptr)
{
size_t uSize = 0;
void* ptr2 = STDeleteInfo<std::has_virtual_destructor<Type>::value>::Get(ptr, uSize);
ptr->~Type();
std::cout << "1 Recycle ptr: " << ptr << ", size: " << sizeof(Type) << std::endl;
std::cout << "2 Recycle ptr: " << ptr2 << ", size: " << uSize << std::endl;
free(ptr2);
}
template<typename Type>
void MyDeleteIngoreVirtual(Type* ptr)
{
ptr->~Type();
std::cout << "Recycle ptr: " << ptr << ", size: " << sizeof(Type) << std::endl;
free(ptr);
}
struct A
{
A()
{
std::cout << "A()\n";
}
~A()
{
std::cout << "~A()\n";
}
virtual void* VirtualDeleteInfo(size_t& uSize)
{
std::cout << "A::VirtualDeleteInfo\n";
uSize = sizeof(*this);
return (void*)this;
}
virtual void f()
{
std::cout << "A::f()\n";
}
int a1;
int a2;
};
struct B
{
B()
{
std::cout << "B()\n";
}
virtual ~B()
{
std::cout << "~B()\n";
}
virtual void* VirtualDeleteInfo(size_t& uSize)
{
std::cout << "B::VirtualDeleteInfo\n";
uSize = sizeof(*this);
return (void*)this;
}
virtual void f()
{
std::cout << "B::f()\n";
}
int b;
};
struct C
: public A
, public B
{
C()
{
std::cout << "C()\n";
}
~C()
{
std::cout << "~C()\n";
}
void* VirtualDeleteInfo(size_t& uSize) override
{
std::cout << "C::VirtualDeleteInfo\n";
uSize = sizeof(*this);
return (void*)this;
}
virtual void f()
{
std::cout << "C::f()\n";
}
int c;
};
int main()
{
B* obj = MY_NEW(C);
std::cout << "obj: " << obj << std::endl;
auto obj2 = dynamic_cast<C*>(obj);
std::cout << "obj2: " << obj2 << std::endl;
MY_DELETE_IGNORE_VIRTUAL(obj2); // 显示调用子类,可以不依赖虚函数
}
/*
Allocate ptr: 0x1d72a80, size: 32
A()
B()
C()
obj: 0x1d72a90
obj2: 0x1d72a80
~C()
~B()
~A()
Recycle ptr: 0x1d72a80, size: 32
*/
方案:通过分配额外的内存空间记录分配的内存大小
若申请 sizeof(Type),则分配 sizeof(Extra) + sizeof(Type)。其中,pBase 指向分配的地址空间,pMem 指向业务申请的分配空间,在 pMem - pBase 之间的内存用于记录业务申请的内存长度。
此方案不可行。因为在多继承场景下,基类指针会发生偏移,无法根据子类的指针计算得到 pBase。例如:动态申请 C 的地址为 c,即 pBase == c。将 c 赋值给 b 后,b 的指针会发生偏移。若通过 MY_DELETE(b) 的方式,只能获取基类的大小,导致释放的内存空间不正确(即,传入的释放地址不正确)。
// struct C : public A, public B
C* c = new C;
A* a = c;
B* b = c;
std::cout << "a: " << a << std::endl;
std::cout << "b: " << b << std::endl;
std::cout << "c: " << c << std::endl;
参考 C++ 对象的内存布局:
- a: 0x15eaac0
- b: 0x15eaad0 若返回是 B* 的对象,则出现地址偏移,无法计算出 C* 时的地址
- c: 0x15eaac0
方案: 通过多态的方式
通过基类指针调用子类的Get函数获取子类的大小和地址。
#include <iostream>
#include <type_traits>
#define MY_NEW(Type, ...) MyNew<Type>(__VA_ARGS__)
#define MY_DELETE(ptr) MyDelete(ptr)
template<bool HAS_VIRTUAL_DESTRUCTOR>
struct STDeleteInfo
{
template<typename T>
inline static void* Get(T* ptr, size_t& uSize)
{
//std::cout << "ptr: " << ptr << std::endl;
return ptr->VirtualDeleteInfo(uSize);
}
};
template<>
struct STDeleteInfo<false>
{
template<typename T>
inline static void* Get(T* ptr, size_t& uSize)
{
uSize = sizeof(T);
return ptr;
}
};
template<typename Type>
Type* MyNew()
{
void* ptr = malloc(sizeof(Type));
std::cout << "Allocate ptr: " << ptr << ", size: " << sizeof(Type) << std::endl;
new (ptr) Type;
return (Type*)ptr;
}
template<typename Type>
void MyDelete(Type* ptr)
{
size_t uSize = 0;
void* ptr2 = STDeleteInfo<std::has_virtual_destructor<Type>::value>::Get(ptr, uSize);
ptr->~Type();
std::cout << "1 Recycle ptr: " << ptr << ", size: " << sizeof(Type) << std::endl;
std::cout << "2 Recycle ptr: " << ptr2 << ", size: " << uSize << std::endl;
free(ptr2);
}
struct A
{
A()
{
std::cout << "A()\n";
}
virtual ~A()
{
std::cout << "~A()\n";
}
virtual void* VirtualDeleteInfo(size_t& uSize)
{
std::cout << "A::VirtualDeleteInfo\n";
uSize = sizeof(*this);
return (void*)this;
}
virtual void f()
{
std::cout << "A::f()\n";
}
int a1;
int a2;
};
struct B : public A
{
B()
{
std::cout << "B()\n";
}
~B()
{
std::cout << "~B()\n";
}
void* VirtualDeleteInfo(size_t& uSize) override
{
std::cout << "B::VirtualDeleteInfo\n";
uSize = sizeof(*this);
return (void*)this;
}
virtual void f()
{
std::cout << "B::f()\n";
}
int b;
};
int main()
{
A* obj = MY_NEW(B);
obj->f();
MY_DELETE(obj);
}
/*
Allocate ptr: 0x11468f0, size: 24
A()
B()
B::f()
B::VirtualDeleteInfo
~B()
~A()
1 Recycle ptr: 0x11468f0, size: 16
2 Recycle ptr: 0x11468f0, size: 24
*/
多继承场景:C -> A, B
#include <iostream>
#include <type_traits>
#define MY_NEW(Type, ...) MyNew<Type>(__VA_ARGS__)
#define MY_DELETE(ptr) MyDelete(ptr)
template<bool HAS_VIRTUAL_DESTRUCTOR>
struct STDeleteInfo
{
template<typename T>
inline static void* Get(T* ptr, size_t& uSize)
{
//std::cout << "ptr: " << ptr << std::endl;
return ptr->VirtualDeleteInfo(uSize);
}
};
template<>
struct STDeleteInfo<false>
{
template<typename T>
inline static void* Get(T* ptr, size_t& uSize)
{
uSize = sizeof(T);
return ptr;
}
};
template<typename Type>
Type* MyNew()
{
void* ptr = malloc(sizeof(Type));
std::cout << "Allocate ptr: " << ptr << ", size: " << sizeof(Type) << std::endl;
new (ptr) Type;
return (Type*)ptr;
}
template<typename Type>
void MyDelete(Type* ptr)
{
size_t uSize = 0;
void* ptr2 = STDeleteInfo<std::has_virtual_destructor<Type>::value>::Get(ptr, uSize);
ptr->~Type();
std::cout << "1 Recycle ptr: " << ptr << ", size: " << sizeof(Type) << std::endl;
std::cout << "2 Recycle ptr: " << ptr2 << ", size: " << uSize << std::endl;
free(ptr2);
}
struct A
{
A()
{
std::cout << "A()\n";
}
virtual ~A()
{
std::cout << "~A()\n";
}
virtual void* VirtualDeleteInfo(size_t& uSize)
{
std::cout << "A::VirtualDeleteInfo\n";
uSize = sizeof(*this);
return (void*)this;
}
virtual void f()
{
std::cout << "A::f()\n";
}
int a1;
int a2;
};
struct B
{
B()
{
std::cout << "B()\n";
}
virtual ~B()
{
std::cout << "~B()\n";
}
virtual void* VirtualDeleteInfo(size_t& uSize)
{
std::cout << "B::VirtualDeleteInfo\n";
uSize = sizeof(*this);
return (void*)this;
}
virtual void f()
{
std::cout << "B::f()\n";
}
int b;
};
struct C
: public A
, public B
{
C()
{
std::cout << "C()\n";
}
~C()
{
std::cout << "~C()\n";
}
void* VirtualDeleteInfo(size_t& uSize) override
{
std::cout << "C::VirtualDeleteInfo\n";
uSize = sizeof(*this);
return (void*)this;
}
virtual void f()
{
std::cout << "C::f()\n";
}
int c;
};
int main()
{
B* obj = MY_NEW(C);
std::cout << "obj: " << obj << std::endl;
MY_DELETE(obj);
}
/*
Allocate ptr: 0x8eda80, size: 32
A()
B()
C()
obj: 0x8eda90
C::VirtualDeleteInfo
~C()
~B()
~A()
1 Recycle ptr: 0x8eda90, size: 16
2 Recycle ptr: 0x8eda80, size: 32
*/
此方案需要考虑一个问题,如何兼容成员函数VirtualDeleteInfo没有定义的情况?
解决方法:编译器检查。通过SFINAE模版推导的方式,检查类中是否定义了某个成员函数,若存在函数定义,则可以支持业务直接传父类指针进行销毁;若不存在函数定义,则忽略函数调用,由分配器底层进行校验检查。
#include <iostream>
#include <type_traits>
struct A {
A() { std::cout << "A()\n"; }
virtual ~A() { std::cout << "~A()\n"; }
virtual void f() { std::cout << "A::f()\n"; }
int a1;
int a2;
};
struct B : public A {
B() { std::cout << "B()\n"; }
~B() { std::cout << "~B()\n"; }
//virtual void f() { std::cout << "B::f()\n"; }
int b;
};
struct C : public B {
C() { std::cout << "C()\n"; }
~C() { std::cout << "~C()\n"; }
virtual void f() { std::cout << "C::f()\n"; }
int c;
};
template<class T>
struct has_member_f {
template<class U, void (U::*)()>
struct sfinae;
template<class U>
static char test(sfinae<U, &U::f>* unused);
template<class>
static int test(...);
static constexpr bool value = sizeof(test<T>(nullptr)) == sizeof(char);
};
struct foo {
void f() {}
};
int main()
{
std::cout << has_member_f<foo>::value << std::endl;
std::cout << has_member_f<int>::value << std::endl;
std::cout << has_member_f<A>::value << std::endl;
std::cout << has_member_f<B>::value << std::endl;
std::cout << has_member_f<C>::value << std::endl;
}
方案: 通过基类指针调用析构时,获取子类大小和地址
TODO