InfluxDB in Action
InfluxDB 介绍
InfluxDB 是一个专门为海量时序数据高性能读写设计的时序数据库,可以应用于大量时序数据处理的场景包括 DevOps 监控,设备应用指标、IoT 传感器数据、实时分析等。InfluxDB 由 Go 编写,着重于高性能地存储和查询时序数据,同时在部署上也非常方便,没有任何外部依赖,并且支持灵活的数据组织方式。
InfluxDB 特点:
- 独立部署,方便使用,不需要其它外部依赖
- 为存储时序数据而设计的 TSM 存储引擎,支持高性能的数据写入和数据压缩
- 写入数据时不需要事先建立固定 schema 和数据表,灵活支持动态 Tag 写入
- 支持对 Tag 建立索引,提供高效的检索查询
- 提供类似 SQL 的查询语言 InfluxQL 以及 HTTP 读写接口,方便使用
- 提供连续查询来实现对海量数据的采样和预计算
- 提供灵活的数据保留策略来设置数据的保留时间,及时删除过期数据,释放存储空间
原理
LSM-Tree (Log Structured Merge Tree),是一种分层,有序,面向磁盘的数据结构,其核心思想是充分了利用了磁盘批量的顺序写要远比随机写性能高出很多。
为了保证时序数据写入的高效,InfluxDB 采用 LSM 结构,数据先写入内存以及 WAL,当内存容量达到一定阈值之后 flush 成文件,文件数超过一定阈值执行合并。这个套路与其他 LSM 系统(比如 HBase)大同小异。不过,InfluxDB 在 LSM 体系架构的基础上针对时序数据做了针对性的存储改进,官方称改进后的存储引擎为 TSM(Timestamp Segments Merged Tree)结构引擎。
时序数据写入
InfluxDB 在内存中使用一个 Map 来存储时间线数据,其中 Key 表示为 seriesKey + fieldKey,Map 中一个 Key 对应一个 List,List 中存储时间线数据。其实这是个非常自然的想法,并没有什么高深的难点。基于 Map 这样的数据结构,时序数据写入内存流程可以表示为如下三步:
- 时间序列数据进入系统之后首先根据 measurement(table) + datasource(tags) 拼成 seriesKey;
- 根据这个 seriesKey 以及待查 fieldKey 拼成 Key,再在 Map 中根据 Key 找到对应的时间序列集合,如果没有的话就新建一个新的 List;
- 找到之后将 TimestampValue 组合值追加写入时间线数据链表中。
时序数据读取
在一个文件内部根据 Key 查找一个某个时间范围的时序数据。
中间部分为索引层,TSM 在启动之后就会将 TSM 文件的索引部分加载到内存,数据部分因为太大并不会直接加载到内存。查询可以分为三步:
- 首先根据 Key 找到对应的 SeriesIndex Block,因为 Key 是有序的,所以可以使用二分查找来具体实现;
- 找到 SeriesIndex Block 之后再根据查找的时间范围,使用 [MinTime, MaxTime] 索引定位到可能的 Series Data Block 列表;
- 将满足条件的 Series Data Block 加载到内存中解压进一步使用二分查找算法查找即可找到。
基本用法

InfluxDB’s data model and contain four main components:
- Measurement Name: Description and namespace for the metric.
- Tags: Key/Value string pairs and usually used to identify the metric.
- Fields: Key/Value pairs that are typed and usually contain the metric data.
- Timestamp: Date and time associated with the fields.
Conceptually you can think of a measurement as an SQL table, where the primary index is always time. tags and fields are effectively columns in the table. tags are indexed, and fields are not. The difference is that, with InfluxDB, you can have millions of measurements, you don’t have to define schemas up-front, and null values aren’t stored.
Points are written to InfluxDB using the InfluxDB line protocol, which follows the following format:
<measurement>[,<tag-key>=<tag-value>...] <field-key>=<field-value>[,<field2-key>=<field2-value>...] [unix-nano-timestamp]
The following lines are all examples of points that can be written to InfluxDB:
cpu,host=serverA,region=us_west value=0.64
payment,device=mobile,product=Notepad,method=credit billed=33,licenses=3i 1434067467100293230
stock,symbol=AAPL bid=127.46,ask=127.48
temperature,machine=unit42,type=assembly external=25,internal=37 1434067467000000000
使用示例
下面是一条 CPU 利用率的时序数据:

- database:数据库
- measurement:类似关系型数据库中的表的概念,如上图中的 cpu
- field:指标,k-v 结构,如上图的 value=0.8,value 是 field 名,0.8 是 field 的值,一条数据允许有多个指标
- tag:标签,k-v 结构,如上图的 host=server1,region=southernChina,host, region 是 tag 名,server1, southernChina 是 tag 的值,一条数据允许有多个标签
- timestamp:时间戳,单位为纳秒,如上图中的 1608863431000000000
- point:数据点(相当于传统关系型数据库中的一行记录),由 field, tag, timestamp 组成
- retention policy:存储策略,用于设置数据的保留时间
- series:某一类数据集合,在同一个数据库中,retention policy, measureme, tag 完全相同的同属于一个 series
influx-proxy 集群方案
虽然 InfluxDB 在读写性能、用法方面基本能满足时序数据存储的需求,但是要将其实际落地依旧存在个问题:当前官方开源的 InfluxDB 是单机版的,集群版并未开源。单机版 InfluxDB 不具备水平扩展、容灾、故障恢复等集群能力,并不适合在大规模实际生产环境中投入使用。所以,要将 InfluxDB 方案实际落地,还需要解决 InfluxDB 的集群化问题。
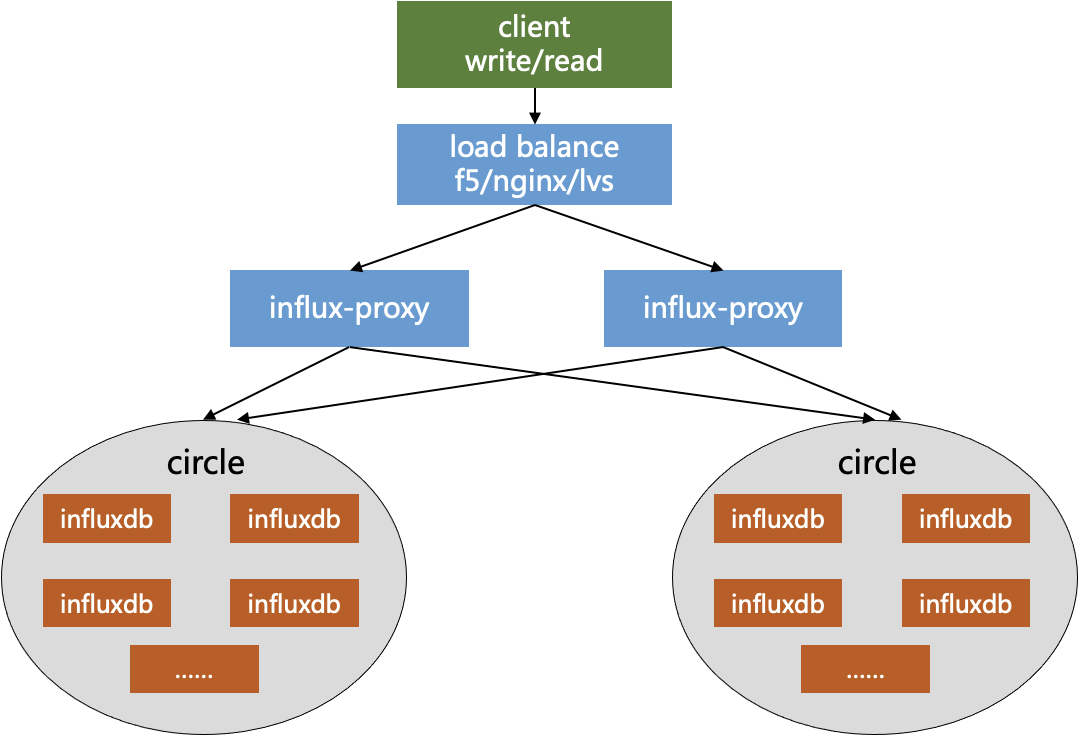
- client:各种语言的 InfluxDB 客户端 (例如,influx-java),InfluxDB shell,curl,浏览器等客户端
- load balance:负载均衡,如 F5、Nginx、LVS、HAProxy等,将客户端请求均衡地分发到各个 proxy 地址
- influx-proxy:代理实例,基于 database + measurement 作为 key 使用一致性哈希算法将读写请求分发到对应的 InfluxDB 实例中,同时具有全局配置信息管理、数据缓存、故障恢复等集群功能
- circle:一致性哈希环,一个 circle 包含了若干个 InfluxDB 实例,共同存储了一份全量的数据,即每个 circle 都是全量数据的一个副本,各个 circle 的数据互备
- influxdb:InfluxDB 实例,以 url 进行区分,一个实例只存储了一份全量数据的一部分数据
在集群高可用方面,架构上可部署多个 proxy 分摊压力,proxy 之间无状态,一个挂掉不影响另外一个。写入数据时经过 proxy 会同时写入多个 circle,实现备份容灾。如果在数据写入时有 InfluxDB 实例出现故障,proxy 会缓存失败数据,直到 InfluxDB 实例重新运行后,恢复重写。查询数据时,因为数据写入了多个 circle,因此只要有一个 circle 里面的 InfluxDB 实例都是健康运行的,就可以查询到数据。
在集群可运维能力方面,influx-proxy 提供了扩缩容、故障恢复、数据同步、数据清理等HTTP接口,对集群状态进行管理,具备基本的集群管理功能。
集群管理 HTTP 接口:
| 接囗 | 描述 |
|---|---|
| /health | 查询所有 influxDB 实例的健康状态 |
| /replica | 查询 db, measurement 对应数据存储的所有 influxdb 实例副本 |
| /rebalance | 对指定的 circle 进行重新平衡 |
| /recovery | 将指定 circle 的全量数据恢复到故障 circle 的全部或部分实例 |
| /resync | 所有 circle 互相同步数据 |
| /cleanup | 对指定的 circle 中不该存储在对应实例的错误数据进行清理 |
性能测试
搭建了一个3节、双备份(2个circle)的最小规模 influx-proxy 集群对其进行读写性能测试,测试包括了 telemetry 时序数据业务场景以及通用的性能压测。单个节点原生 InfluxDB 的 QPS 可达到80万,Influx-proxy 的 QPS 则达到 58万。influx-comparisons 用于数据查询压测,对一个 8000 多条数据的表执行聚合查询操作。在查询压测实验,并发执行了 1000 条查询请求,单节点的 InfluxDB 和 Influx-proxy 的返回时间如下表所示,均在毫秒级别内返回。
| 单个节点 | min | avg | max |
|---|---|---|---|
| InfluxDB | 2.5 ms | 2.8 ms | 6.83 ms |
| Influx-proxy | 3.14 ms | 3.6 ms | 8.29 ms |
其他时序数据库方案
- https://github.com/taosdata/TDengine
- 时序数据库选型指南
注意事项
- 聚合查询能力较弱(仅限 tag 列和时间列)
- 指标列数量大的情况性能是否存在问题
- 集群方案数据一致性如何保证,数据是否会丢失(事务能力是否有保障)
- 非标准 SQL 生态不完善
InfluxQL
- https://docs.influxdata.com/influxdb/v1.8/query_language/ (InfluxQL tutorial)
- https://docs.influxdata.com/influxdb/v1.8/query_language/functions/ (InfluxQL functions)
Documentation
- https://docs.influxdata.com/influxdb/v1.8/ (1.8 版本)
- https://docs.influxdata.com/flux/v0.x/ (Flux documentation)
Refer
- https://github.com/influxdata/influxdb
- https://github.com/influxdata/docs-v2/
- InfluxDB 中文文档
- 时序数据库深入浅出之存储篇
- https://docs.influxdata.com/influxdb/v1.8/introduction/get-started/
- Line protocol
- 时序数据库技术体系–InfluxDB TSM存储引擎之TSMFile
- 深入理解什么是LSM-Tree