Linux Performance in Action
- 性能问题归根结底是某个资源不够用
- 生产环境下偶尔很大的响应延迟是怎么回事?
- 程序员为什么要关心代码性能?
- 如何规划一个性能测试和具体的执行步骤
- 性能测试
- 几个法则
- 概率统计和排队论
- 算法的时间复杂度
- 如何选择高质量的测试工具?
- 如何与产品开发和运维业务有机集成?
- 性能工程实践
- 性能优化思路
- Refer
写得了代码,查得出异常;理得清问题,做得了测量;找得到病根,开得出药方。
合抱之木,生于毫末;九层之台,起于累土。

在敏捷开发过程中,尤其是在面对一个全新的产品时,在业界没有先例和经验可遵循的情况下,最看重的特点是快速的迭代与试错,“尽快推出产品”是最重要的。这时,过早的优化很可能优化错地方,也就是优化的地方并非真正的性能瓶颈,因此让“优化工作”成为了无用功。而且,越早的优化就越容易造成负面影响,比如影响代码的可读性和维护性。如果一个产品已经在业界很成熟,大家非常清楚它的生产环境特点和性能瓶颈,那么优化的重要性可以适当提高。否则的话,在没有实际数据指标的基础上,为了一点点的性能提升而进行盲目优化,的确是得不偿失的。
性能问题归根结底是某个资源不够用
所有的性能问题,虽然表现方式各异,归根结底都是某种资源受到制约,不够用了。这里的资源指的是一个计算机系统,程序和互联网服务会用到的每一种资源,比如 CPU、网络等。换句话说,客户的请求在处理时在某个地方“卡住了”。这个卡住的地方就叫“瓶颈”(或者叫卡点,Choke point)。
下面这张图表中展示了一个系统常见的十大瓶颈,基本上覆盖了所有可能出现性能问题的地方。
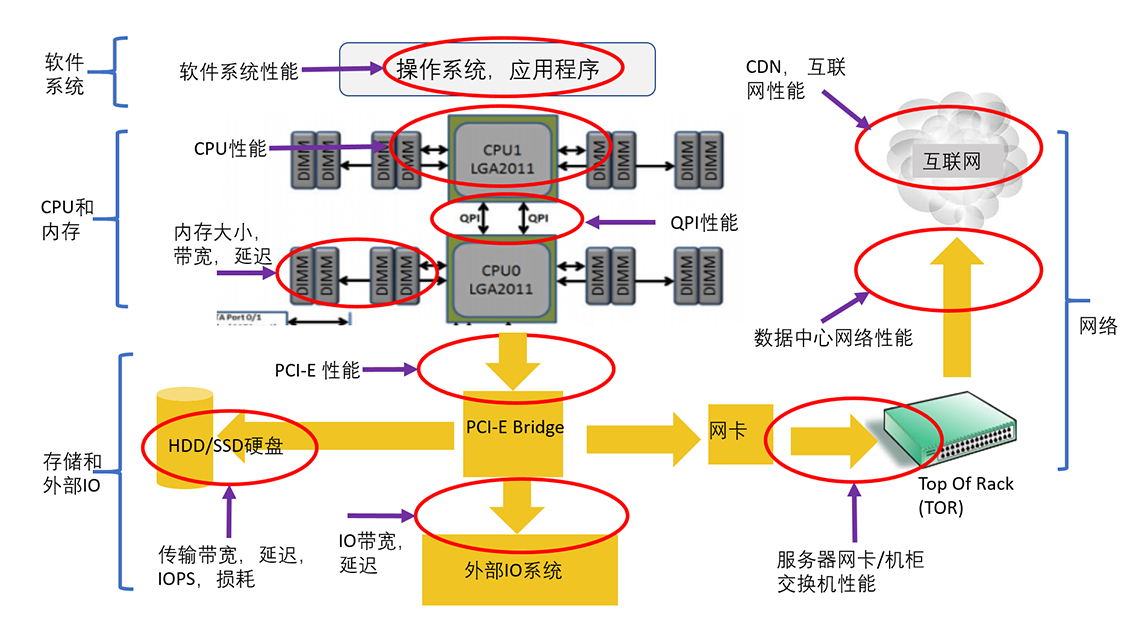
这十大瓶颈可以大致分为四类,这四类是:
- 软件系统:包括操作系统、应用程序、各种类库以及文件系统。
- CPU 和内存:包括 CPU 性能、QPI(QuickPath Interconnect,处理器之间的快速通道互联)和缓存内存。
- 存储和外部 IO:包括处理器的 IO 的接口性能、各种存储系统(尤其是 HDD 和 SSD 性能)。
- 网络:包括服务器到机柜交换机的网络、数据中心的网络、CDN 和互联网。
系统和服务有性能瓶颈就说明这个地方的资源不够用了。所谓最大的性能瓶颈,就是说这个地方的资源短缺程度最大,相对而言,其他地方的资源有富余。
如何找到最大的性能瓶颈?这就需要进行性能测试和性能分析了。性能分析时需要知道三个层次的知识:
- 第一个层次是可能的性能瓶颈,比如我们刚刚讨论的十大瓶颈。知道了瓶颈才能有目标的去分析。
- 第二个层次是每个瓶颈有哪些资源有可能短缺。比如内存就有很多种不同的资源,不仅仅是简单的内存大小。除了内存使用量,还有内存带宽和内存访问延迟。
- 第三个层次是对每个瓶颈的每种资源要了解它和其他模块是如何交互的,对整个系统性能是如何影响的,它的正常值和极限值是多少,如何分析测量等等。
找到性能最大瓶颈后,具体的优化方式就是什么资源不够就加什么资源,同时尽量降低资源消耗,这样就可以做到在资源总量一定的情况下,有能力支撑更高的吞吐率和实现更低的延迟。
生产环境下偶尔很大的响应延迟是怎么回事?
问题场景
比较复杂的 JVM 场景和超大延迟的性能问题,参考论文:Eliminating OS-Caused Large JVM Pauses for Latency-Sensitive Java-Based Cloud Platforms
Abstract:
For PaaS-deployed (Platform as a Service) customer-facing applications (e.g., online gaming and online chatting), ensuring low latencies is not just a preferred feature, but a must-have feature. Given the popularity and powerfulness of Java platforms, a significant portion of today's PaaS platforms run Java. JVM (Java Virtual Machine) manages a heap space to hold application objects. The heap space can be frequently GC-ed (Garbage Collected), and applications can be occasionally stopped for long time during some GC and JVM activities. In this work, we investigated the JVM pause problem. We found out that there are some (and large) JVM STW pauses cannot be explained by application-level activities and JVM activities during GC, instead, they are caused by OS mechanisms. We successfully reproduced such problems and root-cause-ed the reasons. The findings can be used to enhance JVM implementation. We also proposed a set of solutions to mitigate and eliminate these large STW pauses. We share the knowledge and experiences in this writing.
由于大多数互联网业务都是面向在线客户的(例如在线游戏和在线聊天),所以,确保客户相应的低延迟非常重要。各种研究也都表明,200 毫秒延迟,是多数在线用户可以忍受的最大延迟。因此,确保低于 200 毫秒(甚至更短)的延迟,已经成为定义的 SLA(服务水平协议)的一部分。
鉴于 Java 的普及和强大功能,当今的互联网服务中有很大一部分都在运行 Java。Java 程序的一个问题是 JVM 卡顿,也就是大家常说的 STW(Stop The World)、JVM(Java 虚拟机)暂停。根据我的经验,尽管我们或许已经仔细考虑了很多方面来优化,但 Java 应用程序有时仍会遇到很大的响应延迟。
这个 STW 的产生和 JVM 的运行机制是直接相关的。
Java 应用程序在 JVM 中运行,使用的内存空间叫堆。JVM 负责管理应用程序在内存里面的对象。堆空间经常被 GC 回收(垃圾收集),这个过程是 JVM 操作的。Java 应用程序可能在 GC 和 JVM 活动期间停止,这就会给应用程序带来 STW 暂停。这些 GC 和 JVM 活动信息很重要,根据启动 JVM 时提供的 JVM 选项,各种类型的相关信息,都将记录到 GC 的日志文件中。
尽管某些 GC 引起的 STW 暂停众所周知(比如 JVM 导致的 Full GC),但是我们在生产中发现,其他因素,比如操作系统本身,也会导致一些相当大的 STW 暂停。
比如,下图显示了一个 STW 暂停和 GC 日志,这个暂停时间超过了 11 秒,在生产环境中看到这样的 STW 暂停。

注意图片中有较大的字体的那行,里面显示了 User、Sys 和 Real 的计时,分别对应着用户、系统和实际的计时。比如“Real=11.45”就表示实际的 STW 暂停是 11.45 秒钟。在这个 GC 日志中,这种暂停 11 秒钟的 STW 非常讨厌,因为这样大的暂停是不能容忍的。而且这个问题很难理解,完全不能用 GC 期间的应用程序活动和垃圾回收活动来解释。从日志中我们也看到,这个 JVM 的堆并不大,只有 4GB,垃圾收集基本不会超过 1 秒钟。正如图中显示的那样,用户和系统时间都可以忽略不计,User 和 Sys 的暂停时间分别是 0.18 秒钟和 0.01 秒钟,但是实际上 JVM 暂停了 11.45 秒钟!因此,GC 所做的工作量,根本无法解释如此之大的暂停值。
重现问题
就是不断地分配和删除特定大小的对象。程序一直在不断分配对象,当对象数目达到某阈值时,就会删除堆中的对象。堆的大小约为 1GB。每次运行固定时间,是 5 分钟。为了真实地模拟生产环境,我们在第二种场景中注入后台 IO。 这些 IO 由 bash 脚本生成,该脚本就是不断复制很大的文件。在我们的实验室环境中,后台工作模块能够产生每秒 150MB 的磁盘写入负载,差不多可以使服务器配备的镜像硬盘驱动器饱和。
我们考虑的主要性能指标,是关于应用程序的 STW 暂停,具体考虑了两个指标:
- 总暂停时间,即所有 STW 暂停的总暂停时间;
- 较大的 STW 暂停计数和。
场景 A 是基准场景,Java 程序在没有后台 IO 负载的情况下运行。在实验室环境中执行了许多次运行,得到的结果基本是一致的。图片显示的是一个持续 5 分钟的运行,就是沿着 5 分钟的时间线,显示了所有 JVM STW 暂停的时间序列数据。我们观察到,所有暂停都非常小,并且 STW 暂停都不会超过 0.25 秒。 STW 的总暂停时间约为 32.8 秒。
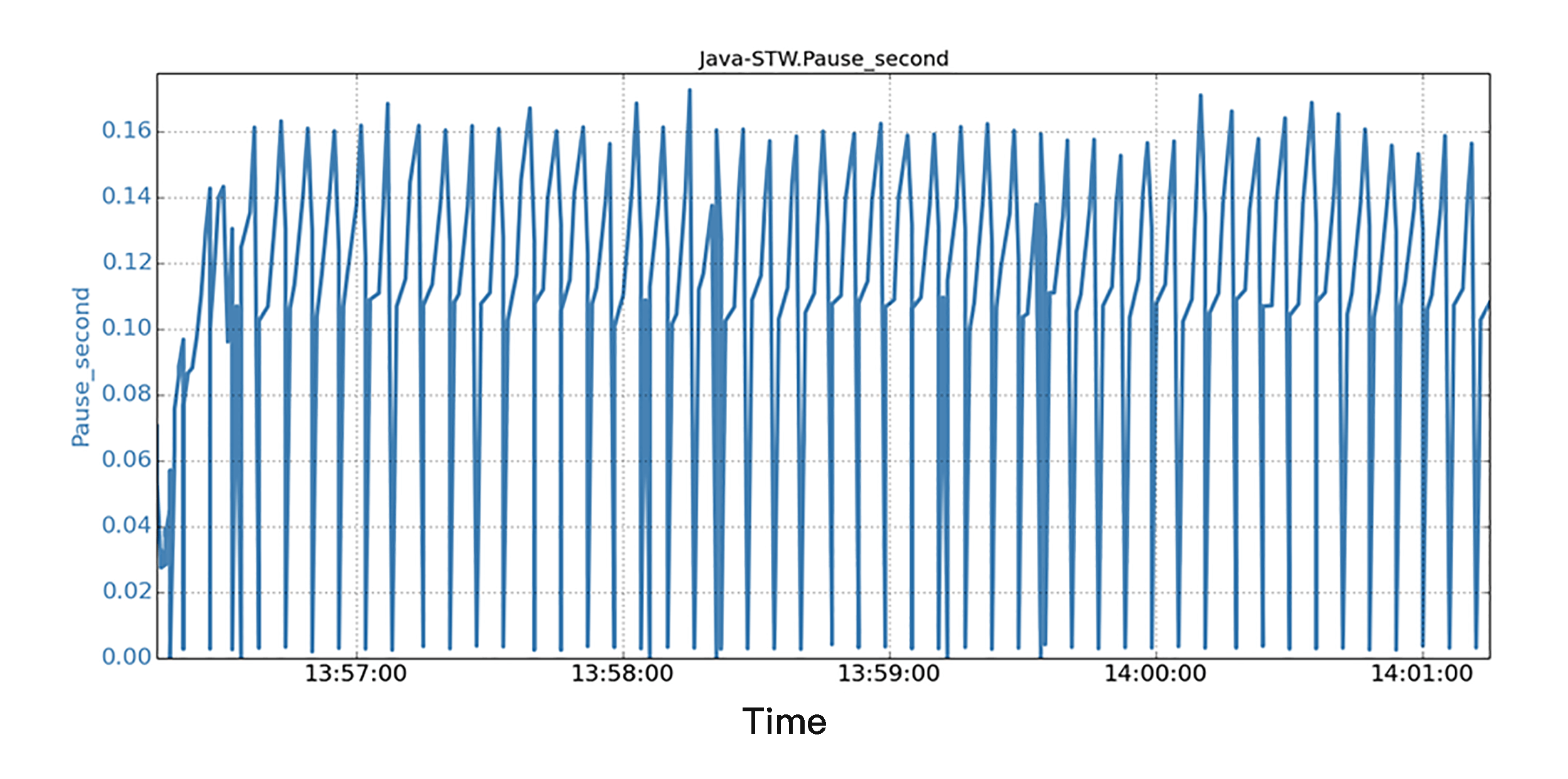
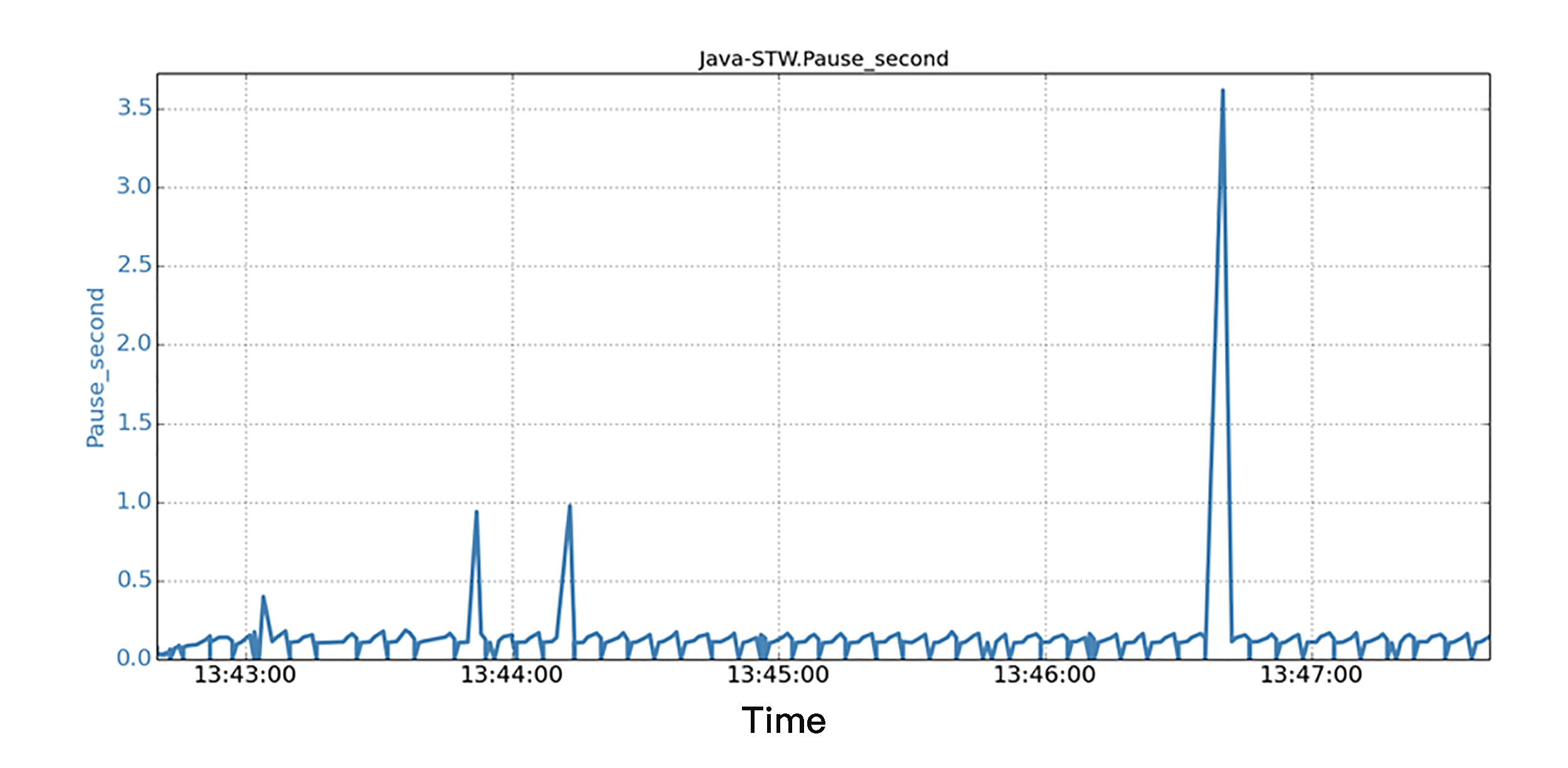
场景 B 是有后台 IO 负载情况下运行相同的 Java 程序。在实际的生产过程中,IO 负载可能来自很多地方,比如操作系统、同一机器上的其他应用程序,或者来自同一 Java 应用程序的各种 IO 活动。在图中,我们同样沿着 5 分钟的时间线,显示了所有 JVM STW 暂停的时间序列数据。我们发现,当后台 IO 运行时,相同的 Java 程序,在短短 5 分钟的运行中,看到 1 个 STW 暂停超过 3.6 秒,3 个暂停超过 0.5 秒!结果是,STW 的总暂停时间为 36.8 秒,比基准场景多了 12%。而 STW 总暂停时间多,也就意味着应用程序的实际工作吞吐量比较低,因为 JVM 多花了时间在 STW 暂停上面。
响应延迟的根本原因在哪里?
我们发现 STW 大的暂停是由 GC 日志记录,write() 调用被阻塞导致的。这些 write() 调用,虽然以缓冲写入模式(即非阻塞 IO)发出,但由于操作系统有“回写”IO 的机制,所以仍然可能被操作系统的“回写”IO 阻塞。操作系统的“回写”机制是什么呢?就是文件系统定期地把一些被改变了的磁盘文件,从内存页面写回存储系统。具体来说,当缓冲的 write() 需要写入文件时,它首先需要写入 OS 缓存中的内存页面。这些内存页是有可能被“回写”的 OS 缓存机制锁定的;而且当后台 IO 流量很重时,该机制可能导致这些内存页面被锁定相当长的时间。
为了彻底查清原因,我们使用 Linux 下的 strace 工具,来剖析函数调用和 STW 暂停的时间相关性。下图表示的是 JVM STW 暂停,和 strace 工具报告的 JVM 进行 write() 系统调用的延迟。图片集中显示了一个 1.59 秒的 JVM STW 暂停的快照。我们仔细检查了两个时间序列数据,发现尽管 JVM 的 GC 日志记录使用缓冲写入,但是 GC 暂停和 write() 延迟之间有极大的相关性。
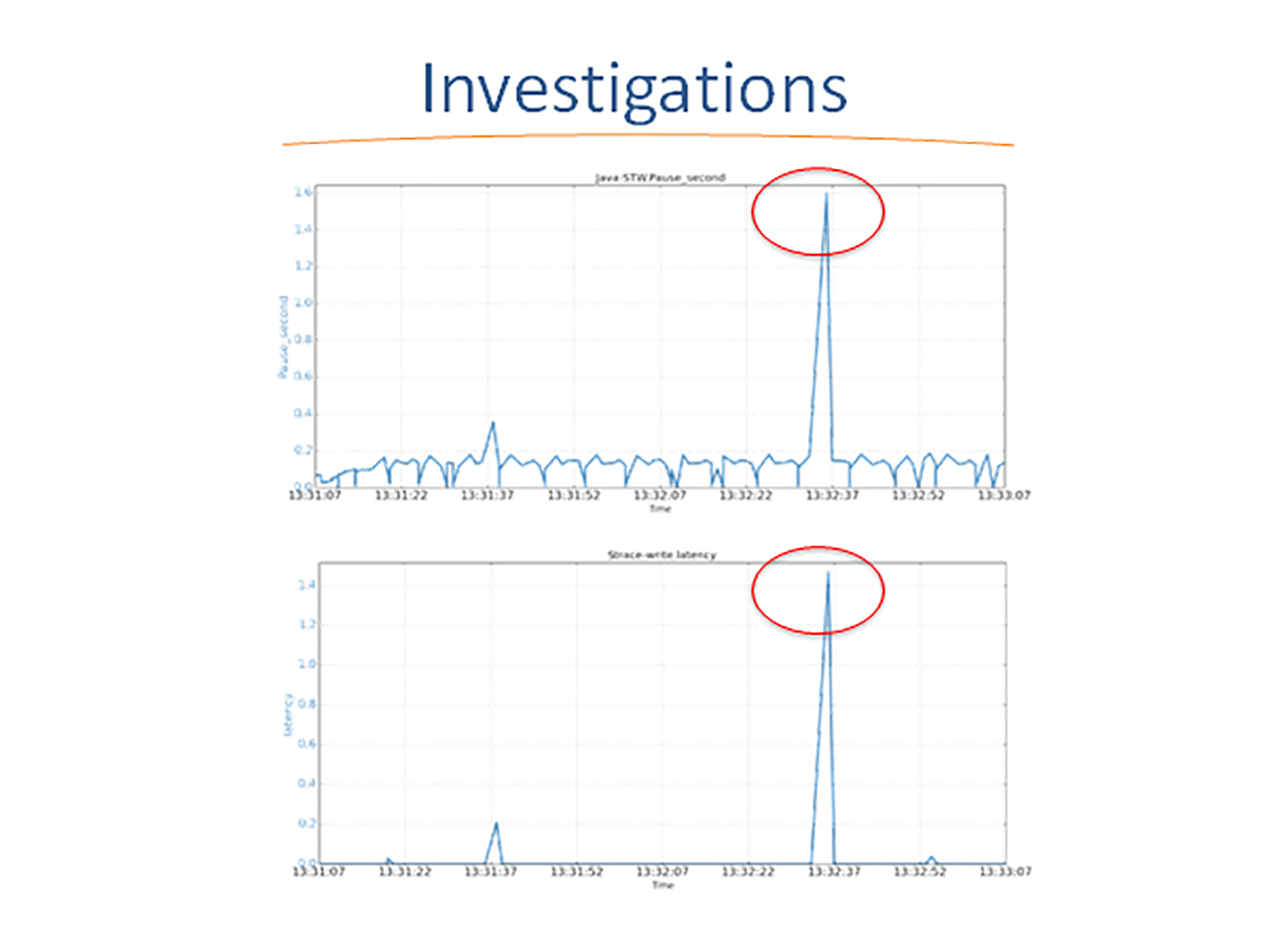
这些时间序列的相关性表明,由于某些原因,GC 日志记录的缓冲写入仍然被阻塞了。那这个原因是什么呢?我们就要通过仔细阅读分析 JVM GC 的日志和 Strace 的输出日志(如下图所示)来寻找。

沿着时间轴线来具体解释一下图片中的数据。
在时间 35.04 秒时,也就是第 2 行日志,一个新的 JVM 新生代 GC 启动,并用了 0.12 秒才完成。新生代 GC 在 35.17 秒时结束,并且 JVM 尝试发出 write() 系统调用(第 4 行),将新生代 GC 统计的信息输出到 GC 日志文件。write() 调用被阻塞 1.47 秒,所以最后在时间 36.64(第 5 行)结束,总共耗时 1.47 秒。当 write() 调用在 36.64 返回给 JVM 时,JVM 记录此 STW 暂停为 1.59 秒(即 0.12 + 1.47)(第 3 行)。
这些数据表明,GC 日志记录过程,恰好位于 JVM 的 STW 暂停路径上,而日志记录所花费的时间也是 STW 暂停的一部分。如果日志记录,也就是 write() 调用被阻塞,那么就会导致 STW 暂停。换句话说,实际的 STW 暂停时间由两部分组成:
- 实际的 GC 时间,例如,新生代 GC 时间。
- GC 日志记录时间,例如,write() 执行时被 OS 阻塞的时间。
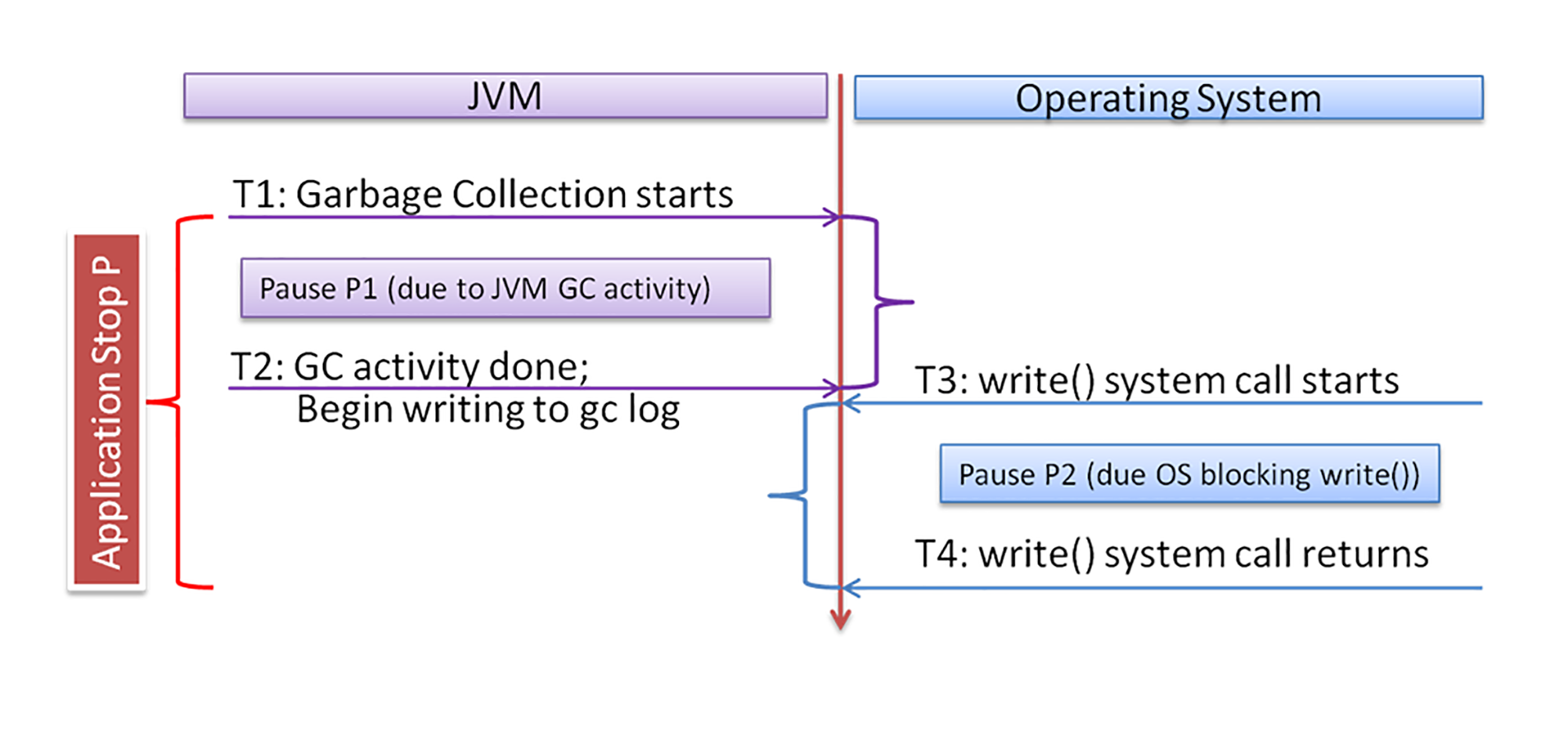
用下图来清楚地表示它们之间的关系:
左边是 JVM 的活动,右边是操作系统的活动。时间 T1 时垃圾回收开始,T2 时 GC 结束,并开始调用 write() 写日志。这之间的延迟,就是 GC 的延迟。T3 时 write() 调用开始,T4 时 write() 调用返回。这之间的延迟,就是 OS 导致的阻塞延迟。所以,总的 STW 暂停就是这两部分延迟的和,也就是 T4-T1。
那么接下来的一个很难理解的问题是:为什么非阻塞 IO,还会被阻塞?
在深入研究各种资源(包括操作系统内核源代码)后,我们意识到,非阻塞 IO 写入还是可能会停留,并被阻塞在内核代码执行过程中。具体原因有好几个,其中包括:页面写入稳定(Stable Page Writing)和文件系统日志提交(Journal Logging)。
JVM 写入 GC 日志文件时,首先会改变(也就是“弄脏”)相应的文件缓存页面。即使以后通过操作系统的写回机制,将缓存页面写到磁盘文件中,被改变内存中的缓存页面,仍然会由于稳定的页面写入而导致页面竞争。根据页面写入稳定的机制,如果页面处于 OS 回写状态,则对该页面的 write() 必须等待回写完成。这是为了避免将部分全新的页面保留到磁盘(会导致数据不一致),来确保磁盘数据的一致性。对于日志文件系统,在文件写入过程中会生成适当的日志。当附加到 GC 日志文件,而需要分配新的文件块时,文件系统需要首先将日志数据保存到磁盘。在日志保存期间,如果操作系统具有其他 IO 活动,则可能需要等待。如果后台 IO 活动繁重,则等待时间可能会很长。
解决方案如何落地?
已经看到,由于操作系统的各种机制的原因,包括页面缓存写回、日志文件系统等,JVM 可能在 GC 日志期间,被长时间阻塞。
那么怎么解决这个问题呢?我们思考了三种方案可以缓解这个问题,分别是:
- 修改 JVM;
- 减少后台 IO;
- 将 GC 日志记录与其他 IO 分开。
修改 JVM 是将 GC 日志记录活动,与导致 STW 暂停的关键 JVM GC 进程分开。这样一来由 GC 日志阻塞引起的问题就将消失。比如 JVM 可以将 GC 日志放到另一个线程中,该线程可以独立处理日志文件的写入,也就不会造成另外一个应用程序线程的 STW 暂停。这个方案的缺点是,采用分线程方法,可能会在 JVM 崩溃期间丢失最后的 GC 日志信息。
后台 IO 引起的 STW 暂停的程度,取决于后台 IO 的强度。因此,可以采用各种方法来降低这些 IO 的强度。比如在 JVM 应用程序运行的服务器上,不要再部署其他 IO 密集型应用程序。
对延迟敏感的应用程序,例如为交互式用户提供服务的在线应用程序,通常无法忍受较大的 STW 暂停。这时可以考虑将 GC 日志记录到其他地方,比如另外一个文件系统或者磁盘上。比如这个文件系统可以是临时文件系统(tmpfs,一种基于内存的文件系统)。它具有非常低的写入延迟的优势,因为它不会引起实际的磁盘写入。但是,基于 tmpfs 的方法存在持久性问题。由于 tmpfs 没有备份磁盘,因此在系统崩溃期间,GC 日志文件将丢失。而另一种方法是将 GC 日志文件放在更快的磁盘上,例如 SSD。我们知道,就写入延迟和 IOPS 而言,SSD 具有更好的 IO 性能。
如何证明解决方案是否有效?
得出方案后,我们就需要对它们进行验证了。这里直接来验证第三种方案:将 GC 日志记录与其他 IO 分开。方法是将 GC 日志文件放在 SSD 文件系统上来验证这种方案。运行与前面实验场景中相同的 Java 应用程序和后台 IO 负载。下图中显示了一个 5 分钟运行时段的所有 STW 暂停和相应的时间戳。
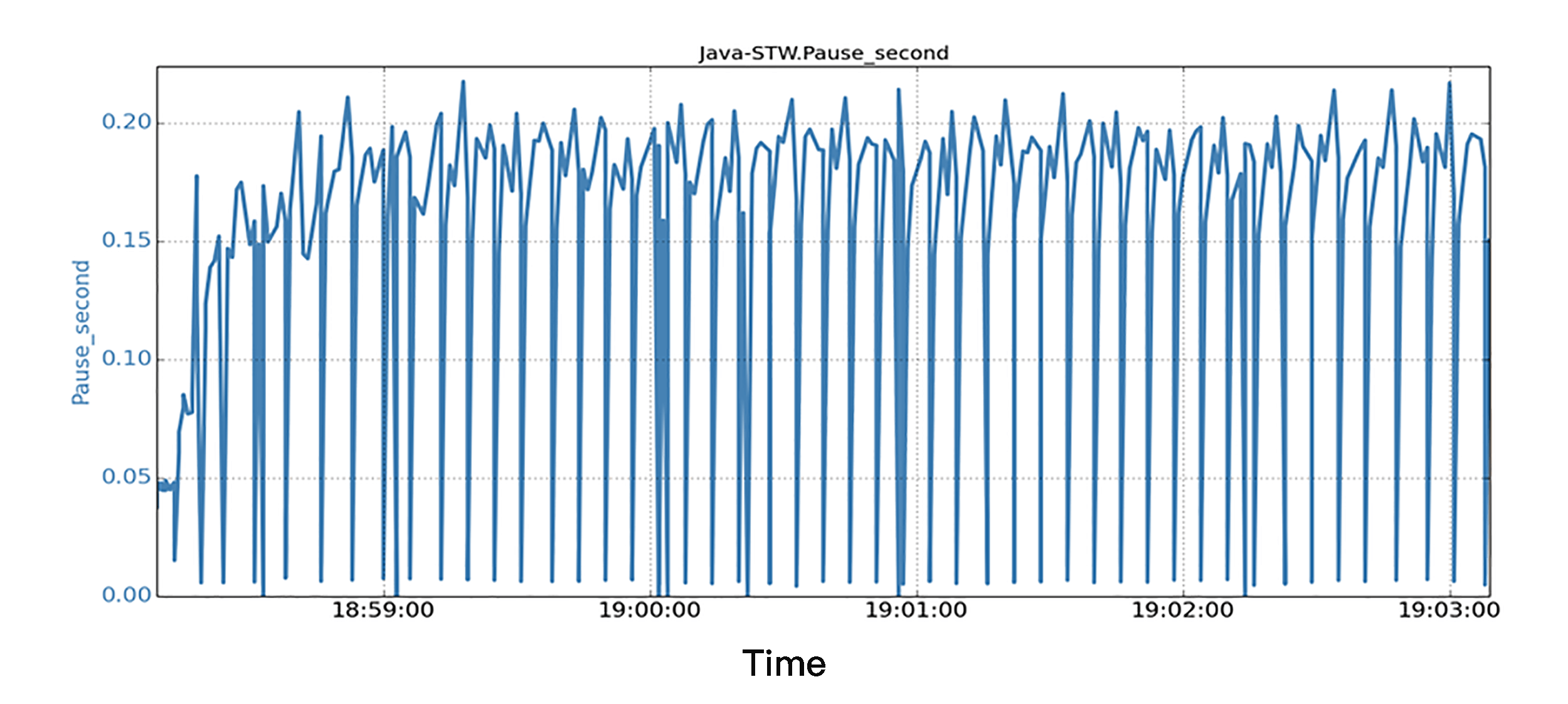
对于 STW 暂停的信息,我们注意到所有的 JVM 的暂停都非常小,所有暂停都在 0.25 秒以下。可以说,延迟暂停方面的性能,得到了很大的提高,这表明,如果这样分开 GC 日志文件,即使有很大的后台 IO 负载,也不会导致 JVM 程序发生较大的 STW 暂停;这样的结果也就验证了这一方案的有效性。
简单来说,就是 JVM 在 GC 时会输出日志文件,写入磁盘时会因为背景 IO 而被阻塞。把日志文件和背景 IO 分开放在不同磁盘,从而让它们互相不影响的话,就能大幅度降低 STW 延迟。
程序员为什么要关心代码性能?
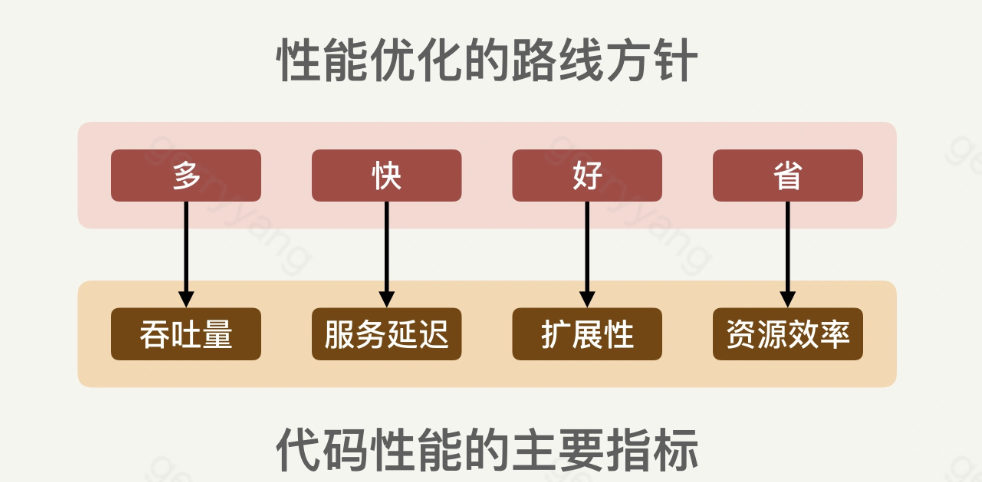
代码性能表现在很多方面和指标,比较常见的几个指标有吞吐量(Throughput)、服务延迟(Service latency)、扩展性(Scalability)和资源使用效率(Resource Utilization)。
- 吞吐量:单位时间处理请求的数量。
- 服务延迟:客户请求的处理时间。
- 扩展性:系统在高压的情况下能不能正常处理请求。
- 资源使用效率:单位请求处理所需要的资源量(比如 CPU,内存等)。
注意,除了这几个指标之外,根据场景,还可以有其他性能指标,比如可靠性(Reliability)。可靠性注重的是在极端情况下能不能持续处理正常的服务请求
性能好的代码,可以用四个字来概括:”多快好省”
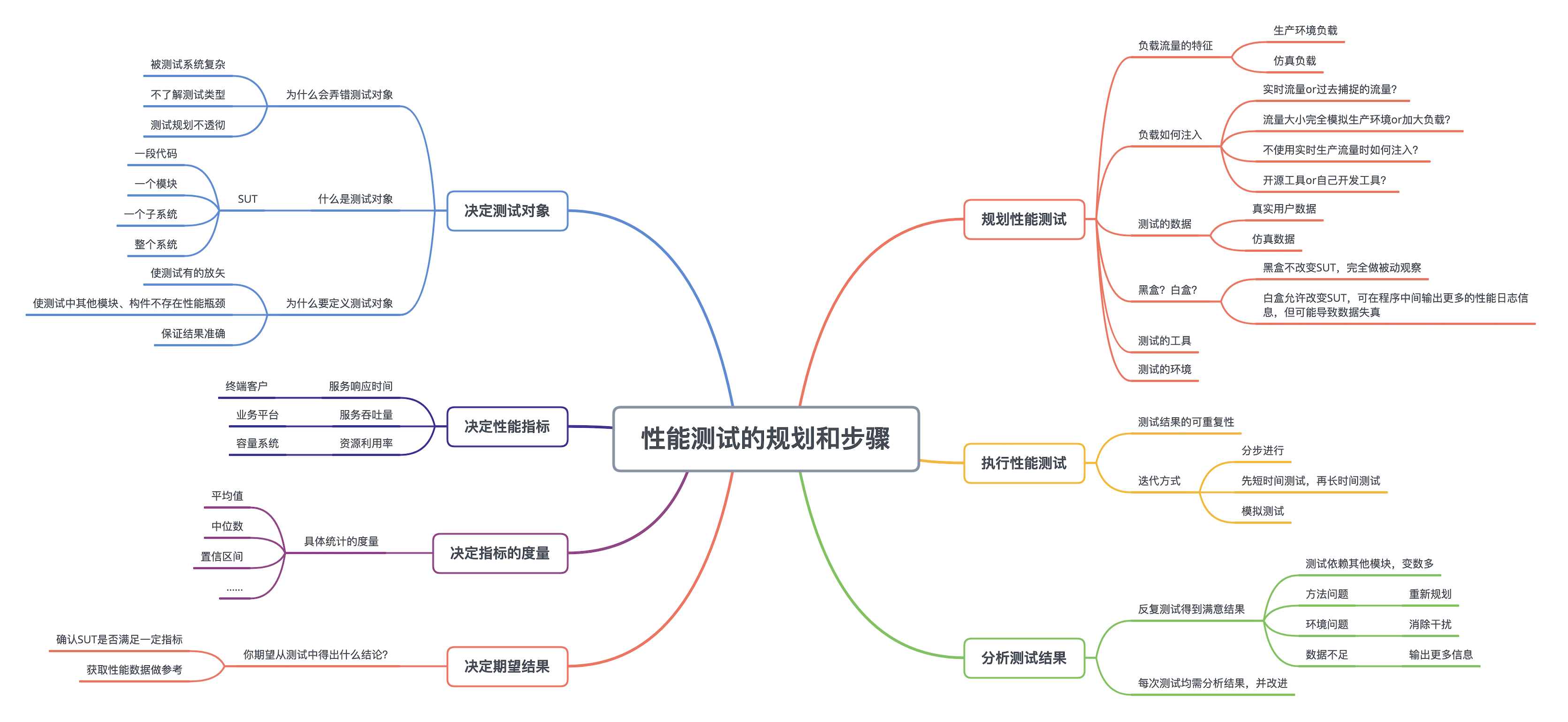
如何规划一个性能测试和具体的执行步骤
在规划任何一种性能测试时,最重要的事情是搞清楚被测试的实体,也就是 SUT(System Under Test),对应的性能指标和度量,以及期望的结果。在此基础上,根据测试的类型来决定和规划具体的测试步骤,然后执行测试,最后再合理地分析测试的结果。
用下图来表示整个性能测试的过程,总共七个部分。
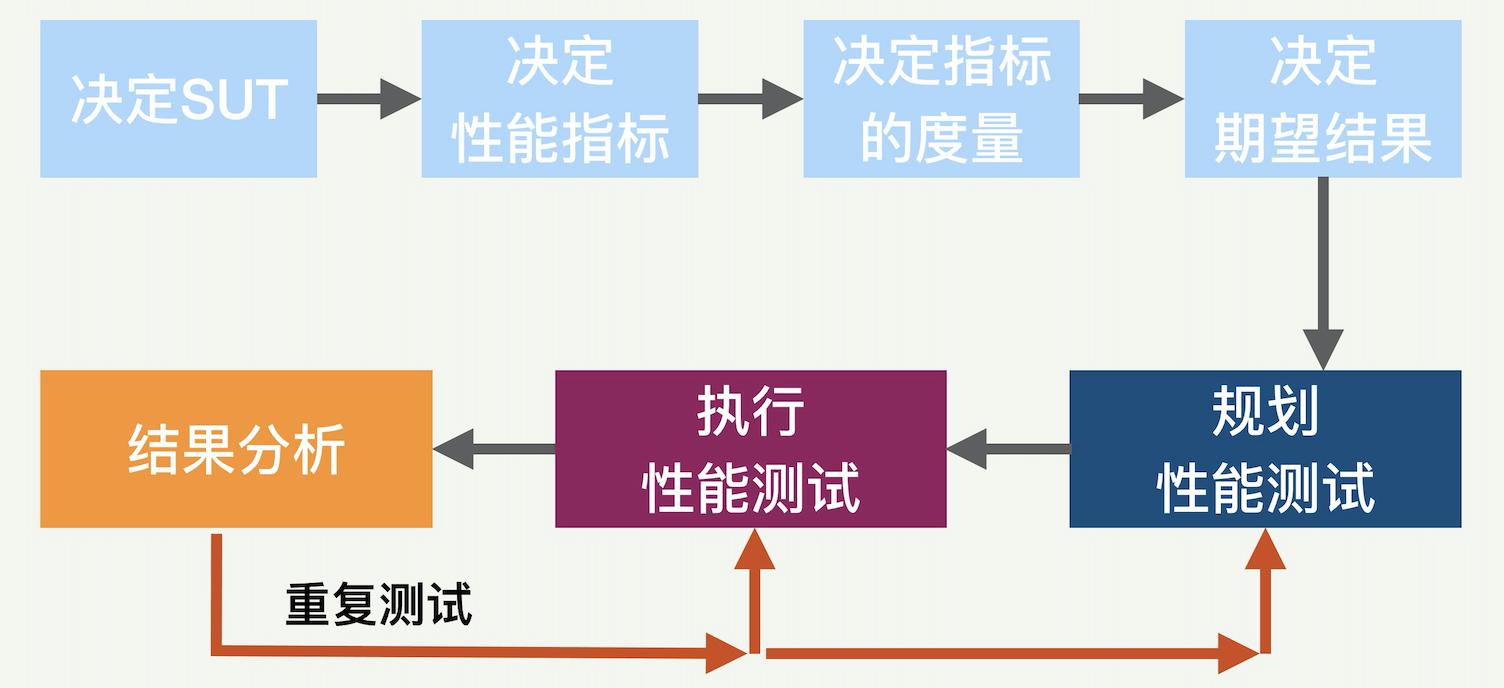
大体上分为前后两大部分。前面四个部分分别是:决定 SUT、决定性能指标、决定指标的度量、决定期望结果。后面三个部分是性能测试的规划、测试的执行和结果分析。这三个部分根据测试的结果或许需要重复多次。
搞清楚测试对象
测试的对象一般叫 SUT(System Under Test),它可以是一段代码、一个模块、一个子系统或者一个整个的系统。比如要测试一个在线互联网服务的性能,那么这整个系统,包括软件、硬件和网络,都算是 SUT。再比如,SUT 也可以是一个子系统,比如运行在某台服务器上的一个进程。
搞清楚 SUT 的重要之处,是让测试做到有的放矢。除了 SUT 本身,其他所有的模块和构件在整个性能测试的过程中都不能有任何性能瓶颈。
比如测试一个在线服务,那么所使用的负载和流量模块就不能成为瓶颈。如果这一点不能得到保证,那么性能测试得出的数据和结论就是不正确的。拿上面的互联网服务来举个例子,如果性能测试中负责产生负载流量的模块成了瓶颈,一秒钟只能发出一千个请求,那么你测出的吞吐量最多也就每秒一千请求。这样的结果和结论显然是不对的。
决定测试的性能指标
搞清楚测试对象 SUT 之后,下一步就是决定具体的性能指标。
对一个面向终端客户的 SUT 而言,一般就是和客户直接相关的性能指标,比如客户(端到端的)服务延迟。如果 SUT 是系统中的某个模块,那么测试的指标有可能是资源的使用率,比如 CPU 或者内存使用率。
平时用的最多的性能指标有三个,就是服务响应时间,服务吞吐量和资源利用率。这三个指标各有侧重,分别对应了终端客户、业务平台以及容量系统。通常,响应时间是用户关注的指标,吞吐量是业务关注的指标,资源利用率是系统关注的指标。
决定测试指标的度量
决定性能指标后,还需要更加具体到统计上的度量。比如你关注的是平均值,还是百分位数(例如 P99);也或许是某个置信区间的大小。
举例来说,对服务响应时间延迟的指标而言,一般需要同时考虑平均值、中位数和几个高端的百分位数,比如 99 百分位。
决定性能测试的期望结果
SUT 和性能指标都确定了,那么下一步就是决定我们期望从测试中得出什么样的结论,比如是为了确认 SUT 的性能满足一定的指标呢,还是只希望获取一些性能数据做参考。搞清楚了测试的期望结果,才能决定什么样的测试结果是可以接受的,什么样是不能接受的。
假设 SUT 是一个互联网服务,测试指标是端到端的平均服务延迟。我们或许已经知道可以接受的平均服务延迟的最大值,比如 500 毫秒。如果性能测试测出的结果显示平均服务延迟是 600 毫秒,那么这个测试结果显然是负面的,就是被测互联网服务不够好,不能接受。如果只是想获取性能数据,那么这个 600 毫秒就是测试结果。
再举几个更复杂一点的测试期望结果的例子:
- 当 2000 个用户同时访问网站时,所有客户的 P99 响应时间不超过 2 秒;
- 测试应用程序崩溃前可以处理的最大并行用户数;
- 测试同时读取 / 写入 500 条记录的数据库执行时间;
- 在峰值负载条件下,检查应用程序和数据库服务器的 CPU 和内存使用情况;
- 验证应用程序在不同负载条件下,比如较低、正常、中等和重载条件下的响应时间。
性能测试的规划
一个成功的性能测试离不开具体的规划,比如如下的几个方面的重要内容,包括负载流量的特征、负载如何注入、测试的数据、黑盒还是白盒测试、测试的工具、测试的环境等。
负载流量的特征和测试类型直接相关。首先我们需要决定是用真正的生产环境的负载还是仿真的负载。
那么负载如何注入呢?负载流量即使已经确定用真正的生产负载,还需要继续决定几个问题:
- 是用实时的流量呢,还是用过去捕捉的流量来重新注入?
- 流量的大小,是完全模拟生产环境呢,还是加大负载。
- 如果不使用实时生产流量,那么如何注入呢?
很多情况下,直接采用开源的工具就够了,但有些情况下需要自己开发或者对开源工具进行二次开发。
配置一个合适的测试环境很重要,理想情况下,应该尽量用与生产平台相同的硬件、路由器配置、网络,甚至是网络背景流量等。不过值得说明的是,有时候我们会特意选取和生产环境不同的测试环境,比如当我们希望提高可重复性,降低测试环境的噪音;那么我们就会选取一个单独的不受干扰的环境来测试。
性能测试的执行
测试规划完毕后就是执行了,这个过程相对简单。
但是需要强调的是,测试结果的可重复性非常重要。性能测试和性能优化很多情况下是一个长期的行为,所以需要固定测试性能指标、测试负载、测试环境,这样才能客观反映性能的实际情况,也能展现出优化的效果。
很多性能测试比较复杂,所以不要期望一次测试就能成功让整个测试环境工作。经常需要实验好几次才能真正让整个测试环境搭配成功。
所以,复杂的性能测试需要多次迭代执行,一般有以下几种方式迭代:
- 分步进行:把复杂的测试验证过程分成几步,一次验证一步,最后一步是整个完整的测试。这样的好处是每一步的问题都可以及早暴露,快速解决。
- 先短时间测试,再长时间测试:有些测试需要执行很长时间,比如一周。如果一周后才发现测试过程有错误,那就浪费了一周时间。所以,为了避免浪费时间,会先进行短期测试,比如半小时。然后分析结果,来发现其中的问题。这样可以比较快速地纠正测试中的错误。
- 模拟测试:在实际使用负载测试之前,先执行简单的负载测试以检查各种工具的正确性。
分析测试结果
测试完毕,就需要分析测试结果了。
如果对一次测试的结果我们不满意,我们就需要重新回到以前的步骤上,或者重新执行测试的步骤,或者重新规划测试的方法。几乎所有的性能测试,就算是看起来非常简单直白的测试,都需要反复进行多次,才能达到满意的效果。 所以如果发生这样的情况,你千万不要气馁。
为什么性能测试不容易一蹴而就呢?这是因为任何测试,其实都依赖于很多其他模块,比如流量的产生、数据的注入、环境的搭建、干扰的排除、数据的收集、结果的稳定等,这些模块都不简单。所以寄希望于“毕其功于一役”,一次就完美地规划和执行一个测试,几乎是不可能的。
每一次测试完毕,我们都要认真分析一下结果,如果不满意,就需要看看如何改进。如果是测试方法不对,就需要重新规划。如果是环境不稳定,有干扰,那么就需要考虑如何消除干扰,净化测试环境。如果数据的收集不够多,就需要从测试模块中输出更多的信息。
性能测试
性能测试是一种特殊的软件测试,它的目的是确保软件应用程序在一定的负载流量下运行良好。性能测试是性能分析和性能优化的基础,它的目标是发现和性能相关的各种问题和性能瓶颈,从而进一步去消除错误和性能瓶颈。
测试目的
大体上有几种目的:
- 测量服务速度(Speed):确定程序是否能够快速地响应用户的请求,这个服务速度一般包括延迟和吞吐率两个指标。速度通常是应用程序最重要的属性之一,因为运行缓慢的应用程序容易丢失用户。
- 测量可扩展性(Scalability):确定应用程序是否可以在用户负载和客户流量增大情况下还能正常地运行。
- 测量稳定性(Stability):确定在各种极端和恶劣环境下,应用程序是否能稳定运行。
- 测量性能瓶颈(Performance Bottleneck):性能瓶颈是应用程序和系统中的最影响整体性能的因素。瓶颈是指某个资源不足而导致某些负载下的性能降低。一些常见的性能瓶颈是 CPU、内存、网络、存储等。
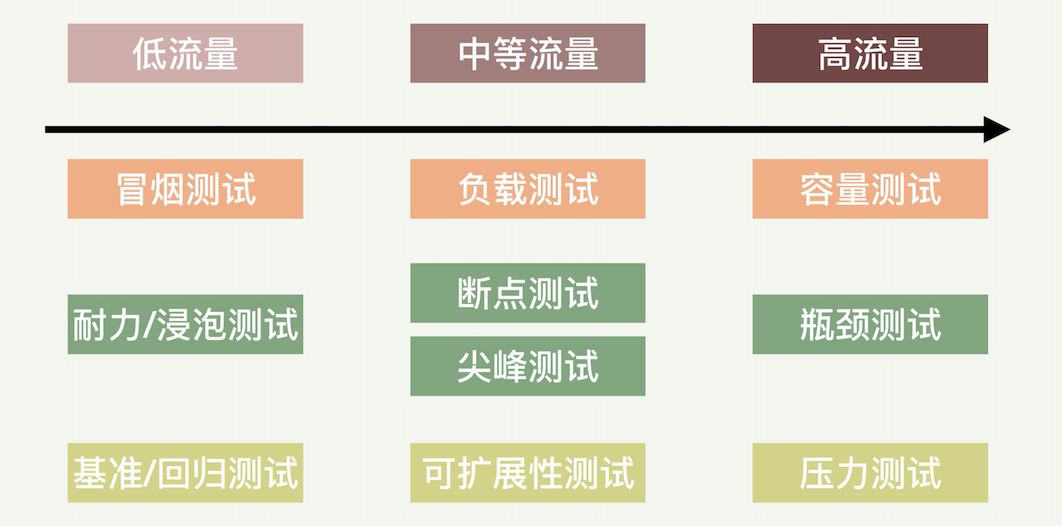
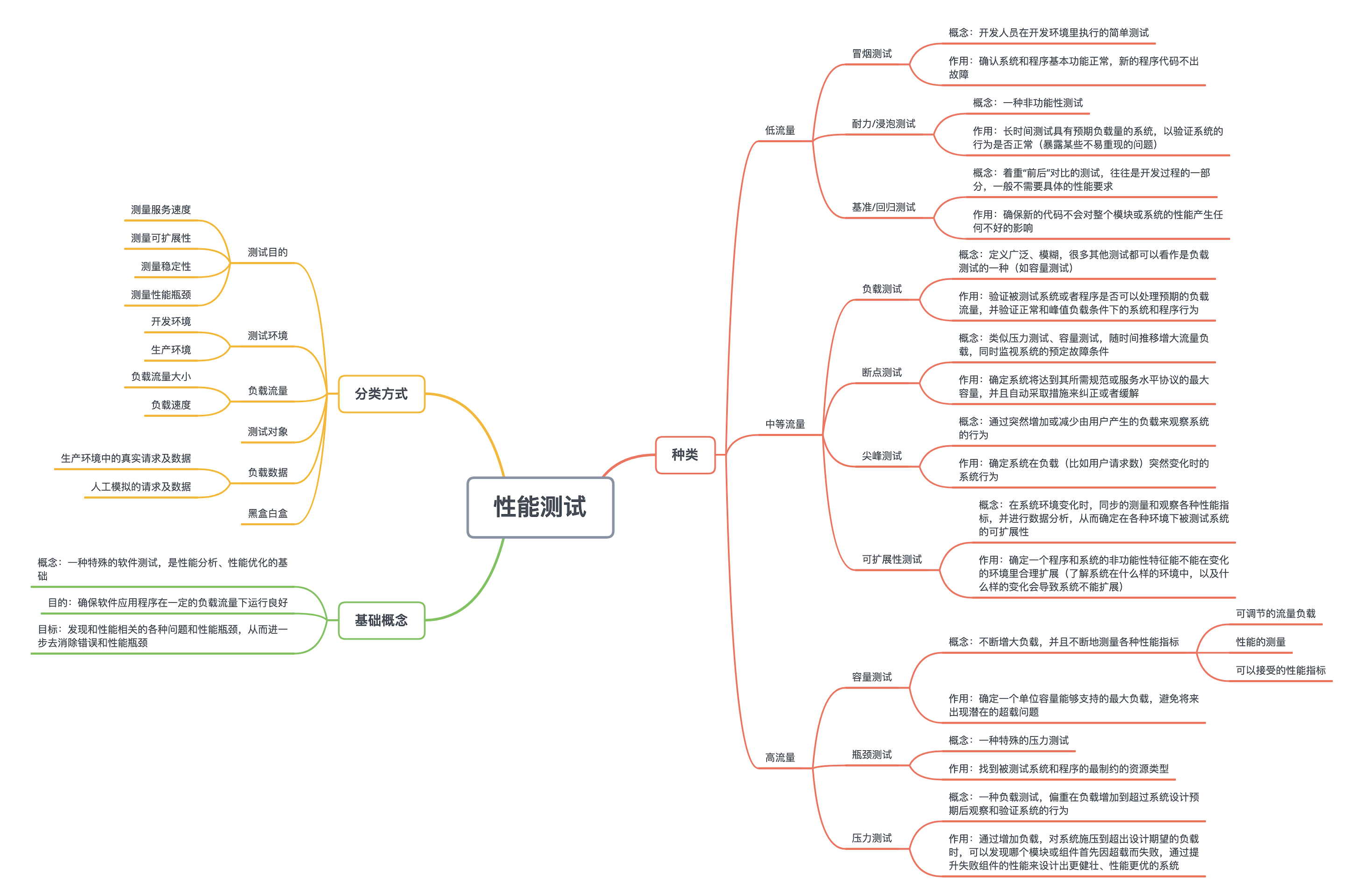
性能测试的种类
常见的性能测试方法,包括负载测试、容量测试、压力测试、断点测试、瓶颈测试、尖峰测试、耐力测试、基准测试、可扩展性测试和冒烟测试这 10 种。
冒烟测试(Smoke Testing)
冒烟测试是开发人员在开发环境里执行的简单测试,以确定新的程序代码不出故障。冒烟测试目的是确认系统和程序基本功能正常。冒烟测试的执行者往往就是开发人员,但有时也让运维人员参与。
耐力测试(Endurance Testing)/ 浸泡测试(Soak Testing)
耐力测试(或者耐久测试)有时也叫浸泡测试,是一种非功能性测试。耐力测试是长时间测试具有预期负载量的系统,以验证系统的行为是否正常。举一个例子,假设系统设计工作时间是 3 小时;我们可以对这一系统进行超过 3 小时的测试,比如持续 6 小时的耐力测试,以检查系统的耐久性。
执行耐力测试最常见的用例是暴露某些不易重现的问题,如内存问题、系统故障或其他随机问题。
这里的偏重点是测试时间,因为有些程序和系统的问题只有在长期运行后才暴露出来。一个最明显的例子就是内存泄漏。一个程序或许短时间内运行正常,但是如果有内存泄漏,只要运行时间足够,就一定会暴露出这个问题。
基准测试(Benchmark Testing)/ 性能回归测试(Performance Regression Testing)
基准测试或者性能回归测试是着重“前后”对比的测试。
这种测试往往是开发过程的一部分,一般不需要具体的性能要求。代码的演化过程中经常需要确保新的代码不会对整个模块或系统的性能产生任何不好的影响。最简单的方法是对代码修改前后进行基准测试,并比较前后的性能结果。执行基准测试的重点是保证前后测试环境的一致,比如负载流量的特征和大小。
负载测试(Load Testing)
负载测试用于验证被测试系统或者程序是否可以处理预期的负载流量,并验证正常和峰值负载条件下的系统和程序行为。这里的负载可以是真正的客户请求,也可以是仿真的人工产生的负载。
断点测试(Breakpoint Testing)
断点测试类似于压力测试或者容量测试。这种测试的过程是随着时间的推移而增大流量负载,同时监视系统的预定故障条件。
断点测试也可以用来确定系统将达到其所需规范或服务水平协议的最大容量,并且自动采取措施来纠正或者缓解。比如云计算环境中,我们可以设置某种性能断点,用它们来驱动某种扩展和伸缩策略。
比如一种性能断点可以是根据用户的访问延迟。如果延迟性能测量的结果是已经超过预定的阈值,就自动进行系统容量调整,比如增加云计算的服务器。反之,系统容量也可以根据断点的规则来减少,以节省成本。
尖峰测试(Spike Testing)
尖峰测试用于确定系统在负载(比如用户请求数)突然变化时的系统行为。这种测试是通过突然增加或减少由用户产生的负载来观察系统的行为。
测试的目标是确定性能在这样的场景下是否会受损,系统是否会失败,或者是否能够处理负载的显著变化。尖峰测试的核心是负载变化的突然性,所以也算是一种压力测试。
可扩展性测试(Scalability Testing)
可扩展性(或者叫可伸缩性)测试用于确定一个程序和系统的非功能性特征能不能在变化的环境里合理扩展。这里的环境变化包括系统环境的变化、负载量的大小、请求的多样性、数据量的大小等。
在系统环境变化时,同步的测量和观察各种性能指标,并进行数据的分析,从而确定在各种环境下被测试系统的可扩展性。如下图所示。
这个测试的主要目的是了解系统在什么样的环境中,以及什么样的变化会导致系统不能扩展。发现这些环境后,可以进一步有针对性的分析和加强。
容量测试(Capacity Testing)
容量测试(或者叫体积测试,Volume Testing)是用于确定一个单位容量能够支持的最大负载。比如一个程序运行在某种服务器上,我们有时需要知道每台服务器能够支持的最大负载(例如客户数),从而决定需要部署多少台服务器才能满足预定的总负载要求。
容量测试一般是会不断增大负载,并且不断地测量各种性能指标。在性能目标变得不可接受之前,系统和程序可以成功处理的负载大小,就是单位容量可以承担的负载。为了尽量让得到的结果匹配实际生产环境,采用的负载流量最好是真正的生产环境的请求和数据。
正常生产环境中的流量和数据或许不够大到让一台服务器超载,因此我们需要解决这个问题。很多公司的解决方案是把其他服务器上的请求重定向到某一台被测试服务器,从而让这台服务器适度超载。
容量测试是确保系统稳定的重要一环。只有进行彻底的容量测试,并有相对应问题的解决方案,才可以使我们能够避免将来出现潜在的超载问题,例如增加的用户数或增加的数据量。
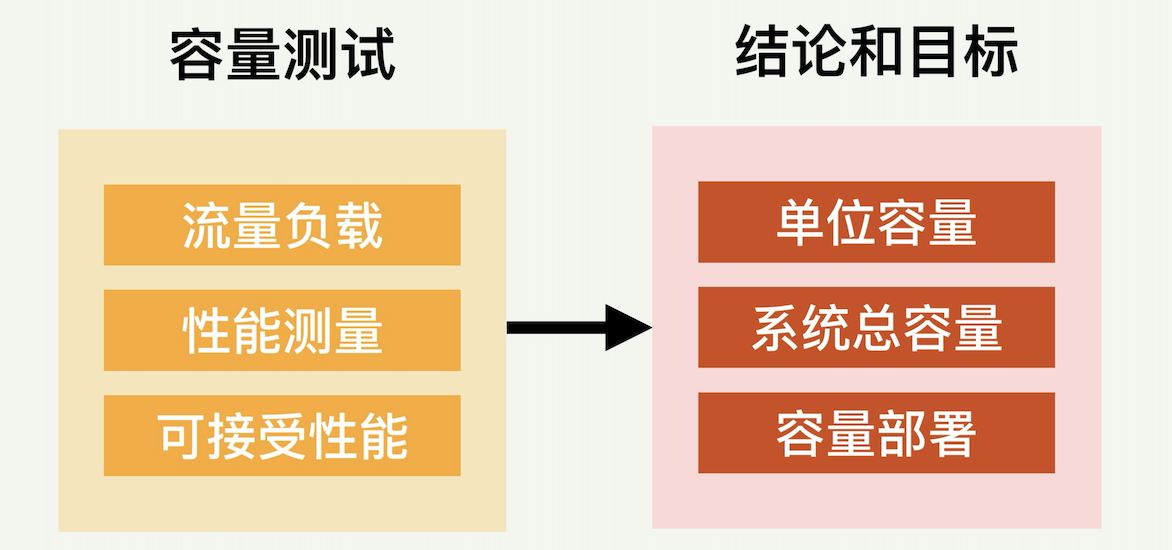
如下图所示,容量测试至少包含三个部分:可调节的流量负载、性能的测量、可以接受的性能指标。这三个部分一起就可以决定单位容量(比如一台服务器)的最大负载容量。这个数据可以帮助我们做各种决策,包括预估系统能负担的总负载;或者根据预期负载来决定部署多少台服务器。
瓶颈测试(Bottleneck Testing)
瓶颈测试其实可以看作一种特殊的压力测试。它的目的是找到被测试系统和程序的最制约的资源类型(比如 CPU 或者存储)。瓶颈测试并不局限于只找到最制约的一个瓶颈,它也可以同时找多个性能瓶颈。
找多个性能瓶颈的的意义主要有两点:
- 如果最制约的瓶颈资源解决了,那么其他制约资源类型就自动会成为下一个瓶颈,所以需要未雨绸缪。
- 系统设计时可以考虑在几个资源之间做些平衡,比如用内存空间来换取 CPU 资源的使用。
压力测试(Stress Testing)
压力测试也是一种负载测试,不过它偏重的是在负载增加到超过系统设计预期后观察和验证系统的行为。当我们通过增加负载,对系统施压到超出设计期望的负载时,就能发现哪个模块或组件首先因超载而失败。这样我们就可以通过提升失败组件的性能来设计出更健壮、性能更优的系统。
相对于容量测试,压力测试的目的是为了暴露系统的问题,因此采用的负载不一定是真正的生产数据和客户请求。
几个法则
帕累托法则 (八二法则)
这个法则是基于我们生活中的认识产生的,人们在生活中发现很多变量的分布是不均匀的——在很多场景下,大约 20% 的因素操控着 80% 的局面。也就是说,所有的变量中,比较重要的只有 20%,是所谓的“关键少数”。剩下的多数,却没有那么重要。
举例来讲,在企业销售中,根据帕累托法则,大约“80%的销售额来自 20%的客户”。认识到这一点对企业管理至关重要,比如需要重视大客户的关系。
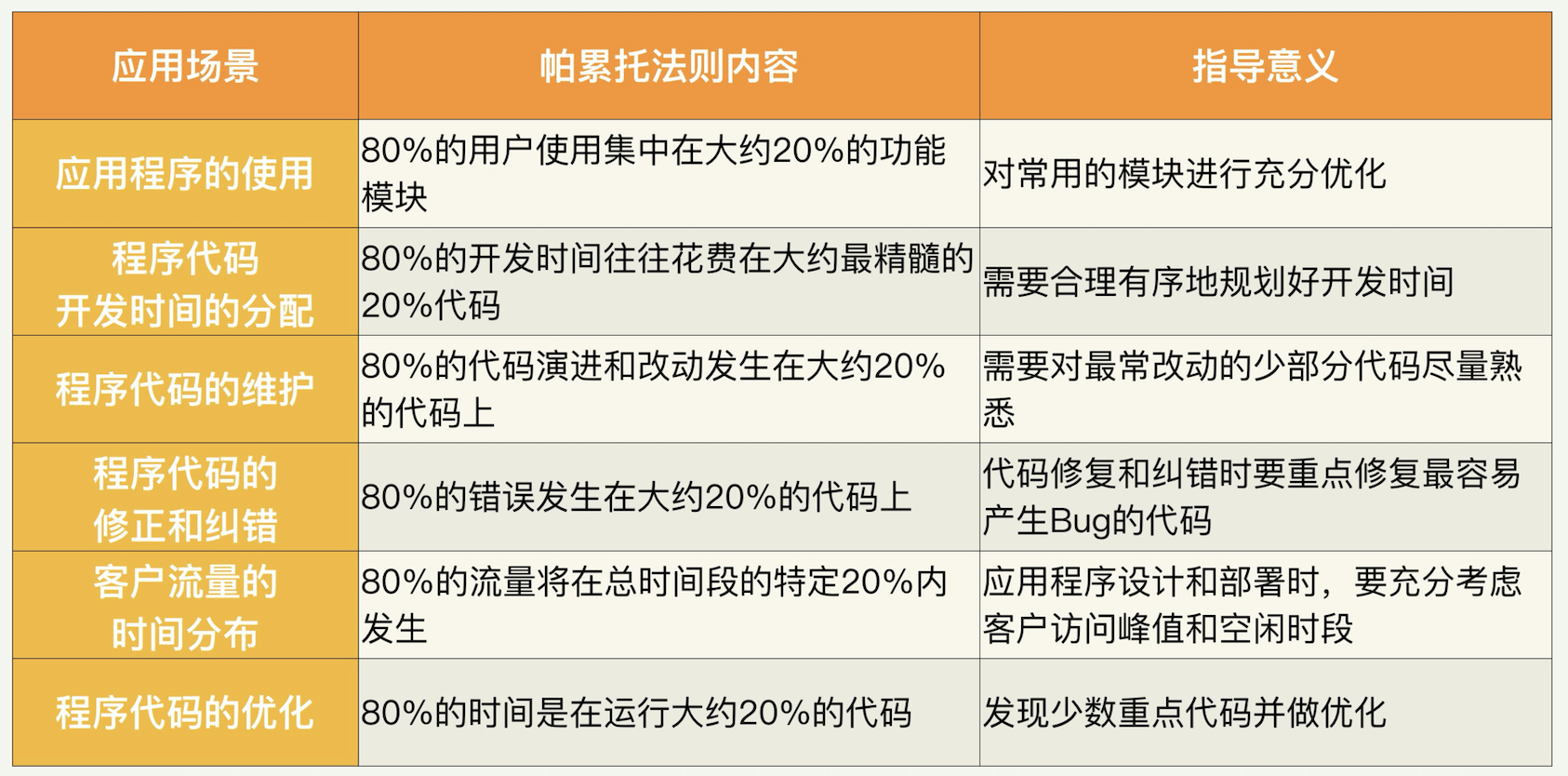
以程序代码的优化为例:
一个程序完成后必然会去运行,如果我们统计代码的运行时间,往往会发现程序的 80% 的时间是在运行大约 20% 的代码。也就是说,只有少数代码非常频繁地被调用。所以,如果我们想提高程序的性能,最好找出这些少数代码,并做重点优化,这样就可以用很少的改动大幅度地提升整个程序和系统的性能。
假设我们的性能优化投入永远是按照代码的优先级来投入的,也就是说,总是要先优化最值得优化的代码。那么我们看到,只要投入差不多 20% 的努力,就能产出 80% 的性能优化产出,获得最大的投入产出比。
在应用帕累托法则的时候,需要注意的是,里面的 80% 或者 20% 都是大约数字,实际的场景千差万别,不可能是恰好这两个数字。这个法则的精髓是,我们的生活和自然界万物的分布不是均匀的,总有些因素比其他因素更重要。
阿姆达尔定律
阿姆达尔定律(Amdahl’s law / Amdahl’s argument)是计算机科学界非常重要的一个定律和法则。它本来用于衡量处理器进行并行处理时总体性能的提升度。但其实阿姆达尔定律可以用在很多方面。
我们用洗衣服和晾衣服来举例。这里假设我们不用洗衣机,而是用传统的方式,先洗再晾。再假设洗衣服和晾衣服各需要 10 分钟,那么整个过程进行完需要 20 分钟。如果我们对晾衣服的过程进行优化,从 10 分钟缩短到 5 分钟,相当于进行了两倍优化。现在整个过程需要多长时间呢?需要 15 分钟,因为洗衣服的模块还是需要 10 分钟。在这个基础上,我们继续对晾衣服模块进行优化,速度提升 5 倍,从 10 分钟缩短到 2 分钟。整个过程现在需要 12 分钟完成。在这个基础上继续进行类推,我们就会发现,无论对晾衣服模块进行多大的优化,整个洗衣服、晾衣服的过程所需的时间不会小于 10 分钟,也就是整体加速比不会超过 2。
根据阿姆达尔定律描述,科学计算中用多处理器进行并行加速时,总体程序受限于程序所需的串行时间百分比。譬如说,一个程序 50% 是串行的,其他一半可以并行,那么,最大的加速比就是 2。无论用多少处理器并行,这个加速比不可能提高到大于 2。所以在这种情况下,改进程序本身的串行算法可能比用多核处理器并行更有效。
利特尔法则
这个法则描述的是:在一个稳定的系统中,长期的平均客户人数(N)等于客户抵达速度(X)乘以客户在这个系统中平均处理时间(W),也就是说 N=XW。
如果这个状态稳定,也就是说,我们的系统处理速度恰恰好赶上客户到达速度的话,一方面系统没有空闲,另外一方面客户也不需要排队在系统外等待。那么在这个稳定状态下,我们的系统的总容量就恰好等于系统里面正在处理的客户数目。也就是说,N 就等于 X 和 W 的乘积。
从这里可以引申出利特尔法则在性能优化工作中的两种用处:
- 帮助我们设计性能测试的环境。性能测试的内容我们后面会详细讲到,这里简单提一下。比如当我们需要模拟一个固定容量的系统,那么性能测试的客户请求流量速度和每个请求的延时都需要仔细考虑。
- 帮助我们验证测试结果的正确性。有时候,如果性能测试的工作没有仔细地规划,得出的测试结果会出奇得好,或者出奇得差,从而让我们抓脑壳。这时如果采用利特尔法则,就可以很快地发现问题所在之处。
概率统计和排队论
概率和置信区间
概率(Probability),是一个在 0 到 1 之间的实数,是对随机事件发生之可能性的度量。概率论中有一个很重要的定理,叫贝叶斯定理,做性能测试和分析中经常需要用到。
贝叶斯定理(Bayes’ theorem)描述的是在已知一些条件下,某事件的发生概率。比如,如果已知某癌症与寿命有关,合理运用贝叶斯定理就可以通过得知某人年龄,来更加准确地计算出他患上该癌症的概率。
具体来讲,对两个事件 A 和 B 而言,“发生事件 A”在“事件 B 发生”的条件下的概率,与“发生事件 B”在“事件 A 发生”的条件下的概率是不一样的。
然而,这两者的发生概率却是有确定的关系的。就是 A 事件发生的概率,乘以 A 事件下 B 事件发生的概率,这个乘积等于 B 事件发生概率乘以 B 事件下 A 发生的概率。贝叶斯定理的一个用途在于通过已知的任意三个概率函数推出第四个。
P(A|B) = P(B|A) * P(A) / P(B)
置信区间(Confidence interval,CI)是对产生样本的总体参数分布(Parametric Distribution)中的某一个未知参数值,以区间形式给出的估计。相对于点估计指标(比如均值,中位数等),置信区间蕴含了估计精确度的信息。
置信区间是对分布(尤其是正态分布)的一种深入研究。通过对样本的计算,得到对某个总体参数的区间估计,展现为总体参数的真实值有多少概率落在所计算的区间里。
数理统计的点估计指标
做性能测试和优化的过程中会产生大量的数据,比如客户请求的吞吐率,请求的延迟等等。获得这些大量数据后,如何分析和理解这些数据就是一门学问了。通常我们需要处理一下这些数据来求得另外的指标,以方便描述和理解。
描述性统计分析是传统数据分析的基础,这个分析过程可以产生一些描述性指标,比如平均值、中位数、最大值、最小值、百分位数等。这些描述性指标通常也被称为“点估计”,相对于前面讲到的置信区间,是用一个样本统计量来估计参数值,比较容易理解。这些点估计指标分别有不同的优点和缺点。
- 平均值:(Mean,或称均值,平均数)是最常用测度值,它的目的是确定一组数据的均衡点。但不足之处是它容易受极端值影响。比如公司的平均收入,如果有一两个员工有特别高的收入,会把大家的平均收入拉高,就是平时我们经常调侃的“被平均”。
需要注意的是,我们有好几种不同的平均值算法。我们平时比较常用的是算术平均值,就是把 N 个数据相加后的和除以 N。但是还有几种其他计算方法,分别适用不同的情况。比如几何平均数,就是把 N 个数据相乘后的乘积开 N 次方。
-
中位数(Median,又称中值),将数值集合划分为相等的上下两部分,一般是把数据以升序或降序排列后,处于最中间的数。它的优点是不受极端值的影响,但是如果数据呈现一些特殊的分布,比如二向分布,中位数的表达会受很大的负面影响。
-
四分位数(Quartile)是把所有数值由小到大排列,并分成四等份,处于三个分割点位置的数值就是四分位数。 从小到大分别叫做第一四分位数,第二四分位数等等。四分位数的优点是简单,固定了三个分割点位置。缺点也正是这几个位置太固定,因此不能更普遍地描述其他位置。
-
百分位数(Percentile)可以看作是四分位数的扩展,是将一组数据从小到大排序,某一百分位所对应数据的值就称为这一百分位的百分位数,以 Pk 表示第 k 个百分位数。比如常用的百分位数是 P90,P95 等等。百分位数不容易受极端值影响,因为有 100 个位置可以选取,相对四分位数适用范围更广。
几个特殊的百分位数也很有意思,比如 P50 其实就是中位数,P0 其实就是最小值,P100 其实就是最大值。
还要注意的是,面对同一组数据,平均值和中位数以及百分位数这些点估计指标,谁大谁小是不一定的,这取决于这组数据的具体离散程度。比如,在面试的时候我经常问来面试的人一个问题,就是平均值和 P99 哪个比较大?答案就是:不确定。
- 方差 / 标准差(Variance,Standard Variance),描述的是变量的离散程度,也就是该变量离其期望值的距离。
分布模型
以上的几个描述性的点估计统计指标很简单,但是描述数据的功能很有限。如果需要更加直观并准确的描述,就需要了解分布模型了。假设我们有一个系统,观察对客户请求的响应时间。如果面对一万个这样的数据,如何对这个数据集合进行描述呢?这时候用分布模型来描述就很合适。
泊松分布
泊松分布(Poisson distribution)适合于描述单位时间内随机事件发生的次数的概率分布。如某一服务设施在一定时间内收到的服务请求的次数等。
泊松分布(Poisson Distribution)是一种离散概率分布,用于描述单位时间内随机事件发生的次数的概率。这种分布由法国数学家西莫恩·德尼·泊松(Siméon-Denis Poisson)在1838年提出。
泊松分布与二项分布的关系:
泊松分布是二项分布的一个极限情况。当试验次数 n 趋向于无穷大且成功概率 p 趋向于零,使得 np=λ 时,二项分布收敛到泊松分布。这意味着泊松分布适用于描述大量独立事件的情况,其中每个事件的发生概率较小且固定。
二项分布
二项分布(Binomial distribution),是 n 个独立的是/非试验中成功的次数的离散概率分布。
这里通常重复 n 次独立的伯努利试验(Bernoulli trial)。在每次试验中只有两种可能的结果,而且两种结果发生与否互相对立,并且相互独立。也就是说事件发生与否的概率在每一次独立试验中都保持不变,与其它各次试验结果无关。当试验次数为 1 时,二项分布服从比较简单的 0-1 分布。
正态分布
正态分布(Normal distribution),也叫高斯分布(Gaussian distribution)。经常用来代表一个不明的随机变量。
正态分布的曲线呈钟型,两头低,中间高,左右对称,因此经常被称之为钟形曲线。正态分布的重要性在于,大多数我们碰到的未知数据都呈正态分布状。这意味着我们在不清楚总体分布情况时,可以用正态分布来模拟。
排队的理论
计算机系统中的很多模块,比如网络数据发送和接收、CPU 的调度、存储 IO、数据库查询处理等等,都是用队列来缓冲请求的,因此排队理论经常被用来做各种性能的建模分析。
排队论(Queuing Theory),也被称为随机服务系统理论。这个理论能帮助我们正确地设计和有效运行各个服务系统,使之发挥最佳效益。
排队的模型有很多,平时我们用得多的有单队列单服务台和多队列多服务台。系统里面各个模块的模型都可以变化,排队论里面还有很多延伸理论。
算法的时间复杂度
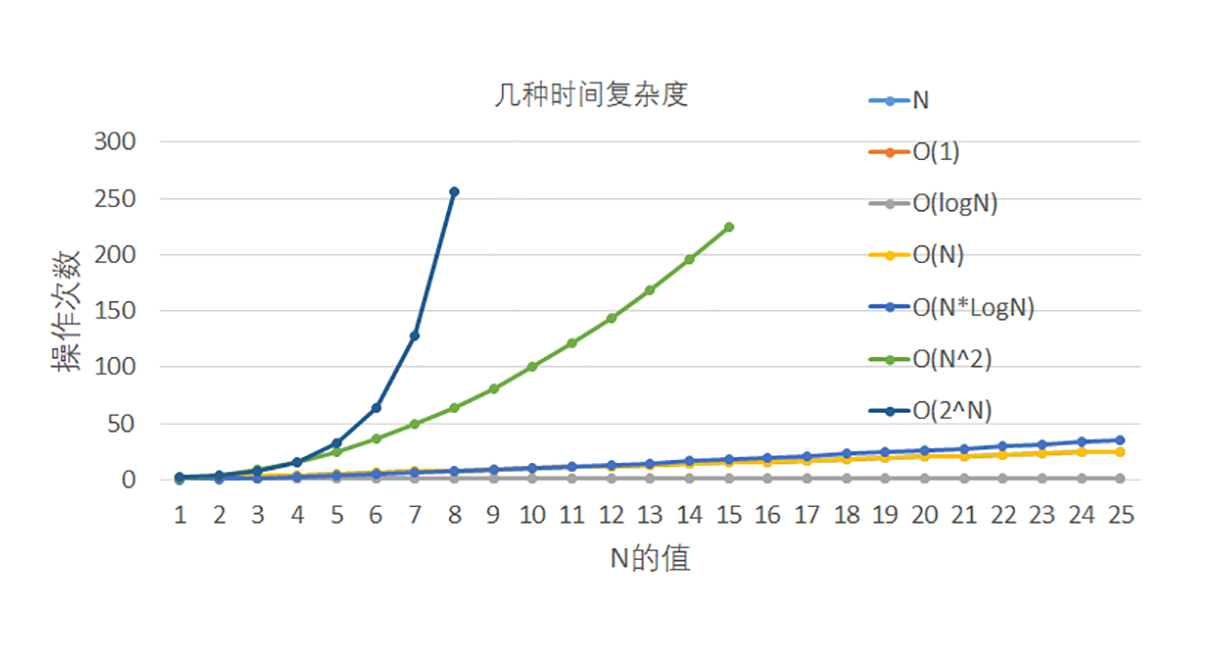
算法的时间复杂度(Time Complexity)。复杂度一般表示为一个函数,来定性描述该算法的期待运行时间,常用大 O 符号表述。具体来讲,有六种复杂度是比较普遍的,这里按照从快到慢的次序依次介绍:
- 常数时间,
O(1):判断一个数字是奇数还是偶数。 - 对数时间,
O(Log(N)):你很熟悉的对排序数组的二分查找。 - 线性时间,
O(N):对一个无序数组的搜索来查找某个值。 - 线性对数时间,
O(N Log(N)):最快的排序算法,比如希尔排序,就是这个复杂度。 - 二次时间,
O(N^2):最直观也最慢的排序算法,比如冒泡,就是这个复杂度。 - 指数时间,
O(2^N): 比如使用动态规划解决旅行推销员问题。这种复杂度的解决方案一般不好。
把这几个算法复杂度放在一张图中表示出来,可以清楚地看出它们的增长速度。大体上来讲,前四种算法复杂度比较合理,而后面两种(也就是 N 平方和指数时间)就不太能接受了,因为在数据量大的时候,运行时间很快就超标了。
如何选择高质量的测试工具?
测试工具的分类
性能测试工具是繁多的。之所以繁多,是因为每种工具适合的场合不同,所以它们各有特点。比如如下几个方面:
- 测试场景:是针对 Web 环境、移动 App、系统、数据库,还是模块测试?
- 测试类型:是基准测试还是峰值测试?
- 免费还是收费:开源工具一般都是免费的;但是很多收费工具也的确物有所值。
- 支持的协议:比如是否支持 HTTP 协议、FTP 协议等等。
- 支持的功能:比如并发性支持度,能否分析测试结果,能否录制性能测试脚本等。
测试的过程
大规模性能测试的一般过程是:通过录制、回放定制的脚本,模拟多用户同时访问被测试系统(SUT)来产生负载压力,同时监控并记录各种性能指标,最后生成性能分析结果和报告,从而完成性能测试的基本任务。
比照这个过程,一个稍微健全的测试工具都会包括以下的模块:
- 负载生成模块:负责产生足够的流量负载。多少流量算足够?这得根据测试类型和具体需求来定。如果测试类型是压力测试,那么产生的流量一定要大到 SUT 不能处理的程度。
- 测试数据收集模块:负责获取测试的数据,包括具体的各种性能数据。这个收集可以是实时的,就是在测试进行之中收集;也可以是后期,等测试完成之后收集的。
- 结果分析和展示:有了大量的测试数据,就需要进行分析并展示。同样的,这个过程可以是实时的,也可以是等全部测试完成后进行。
- 资源监控模块:测试过程中离不开对 SUT 和流量生成模块的实时资源监控,目的是确保这两个模块运行正常。具体来说,流量生成模块必须不能负载过量,否则很可能产生的流量不够大。SUT 也要确保运行还是正常的,否则整个测试就失去意义了。
- 控制中心模块:测试者需要用这个模块和整个测试系统来交互,比如开始或停止测试,改变测试的各种参数等等。
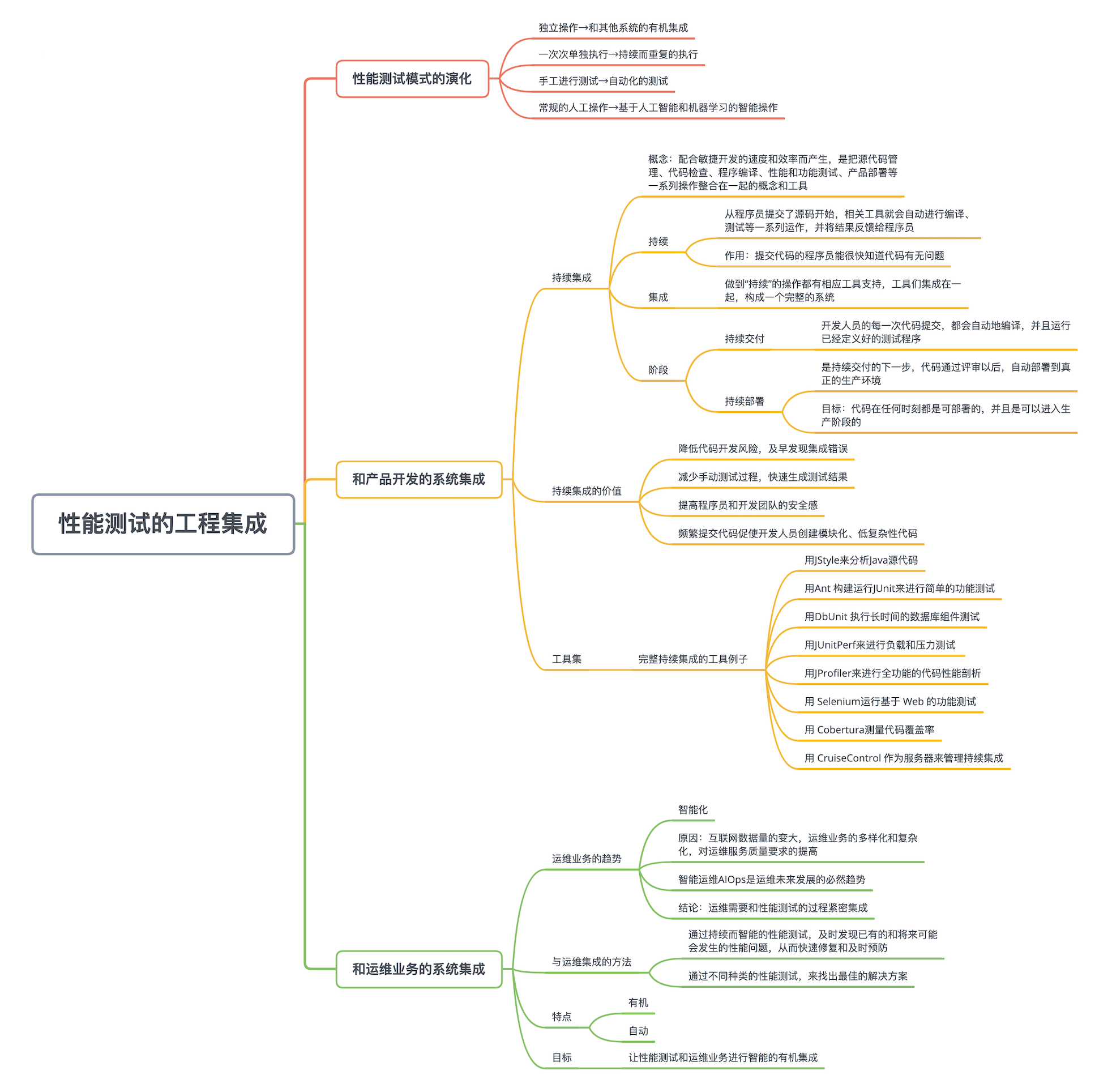
如何与产品开发和运维业务有机集成?
如何让性能测试这一工作从单独的、一次性的、手工发起的、传统的人工操作,进化成一个和开发及运维过程相结合的、持续的、自动重复执行的智能操作。
性能测试模式的演化
性能测试作为 IT 公司的一种重要工作,它的工作模式正在从传统的手工模式,不断进化成智能集成的自动模式。这样的演化主要归功于这些年互联网技术的进步和业务需求的提高,包括数据量的加大和业务的日益复杂化、客户需求的多元化、公司业务规模的扩大,以及人工智能和机器学习的不断成熟。
性能测试的模式进化表现在哪些方面呢?主要有四个方面,如下图所示:
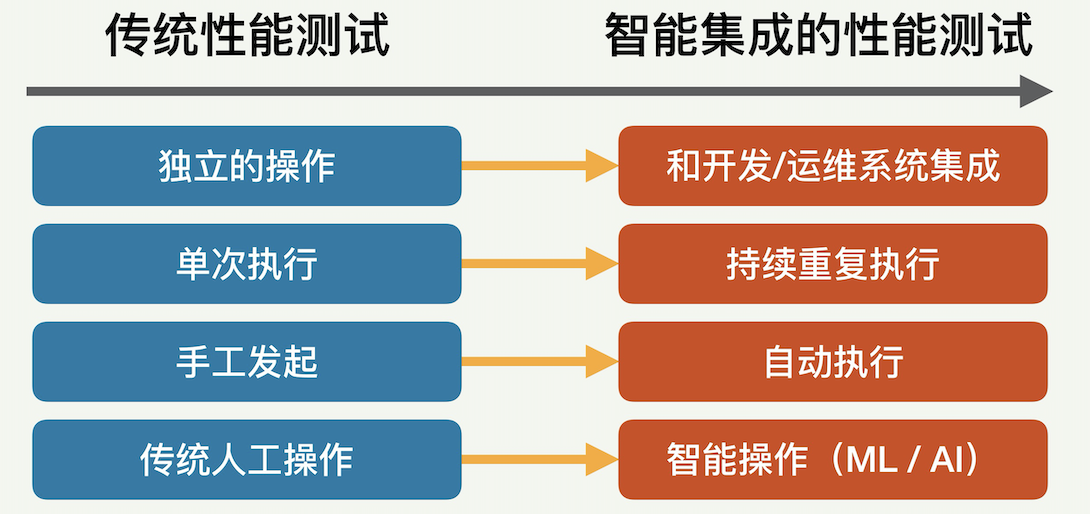
- 从独立的操作演化成和其他系统(比如开发和运维)的有机集成。公司中很多业务都和性能测试有关,尤其是产品开发和系统运维业务。性能测试需要和这些业务紧密结合,从而使相关工作的效率极大提高。
- 从一次次的单独执行演化成持续而重复的执行。从开发角度来看,一个产品的程序代码会不断被开发和增强,包括加入新的功能和修补发现的错误。每次代码改变都需要进行性能测试,以确保程序面对客户的端到端性能和资源利用效率没有变低。从运维角度来看,公司的产品系统也需要持续地进行性能测试,以尽早发现可能的问题。
- 从手工进行测试演化成自动化的测试。每当需要进行性能测试的时候,系统越来越需要自动触发,并按照既定规则来开始测试。测试完成后也需要自动进行分析,并根据分析的结果继续进行后面的定义好的步骤。整个过程最好不需要测试人员的人工参与,以降低运营成本并减少人为错误。
- 从常规的人工操作演化成基于人工智能(AI)和机器学习(ML)的智能操作。数据量的变大让有效的机器学习成为可能。同时伴随着人工智能技术的不断成熟,传统常规的性能测试一步步地走向智能的自动性能优化。
和产品开发的系统集成
性能测试和产品开发密切相关,用下面这张图片表示它们之间的关系。性能测试和产品开发的集成也是所谓“持续集成”(Continuous Integration)的一部分。
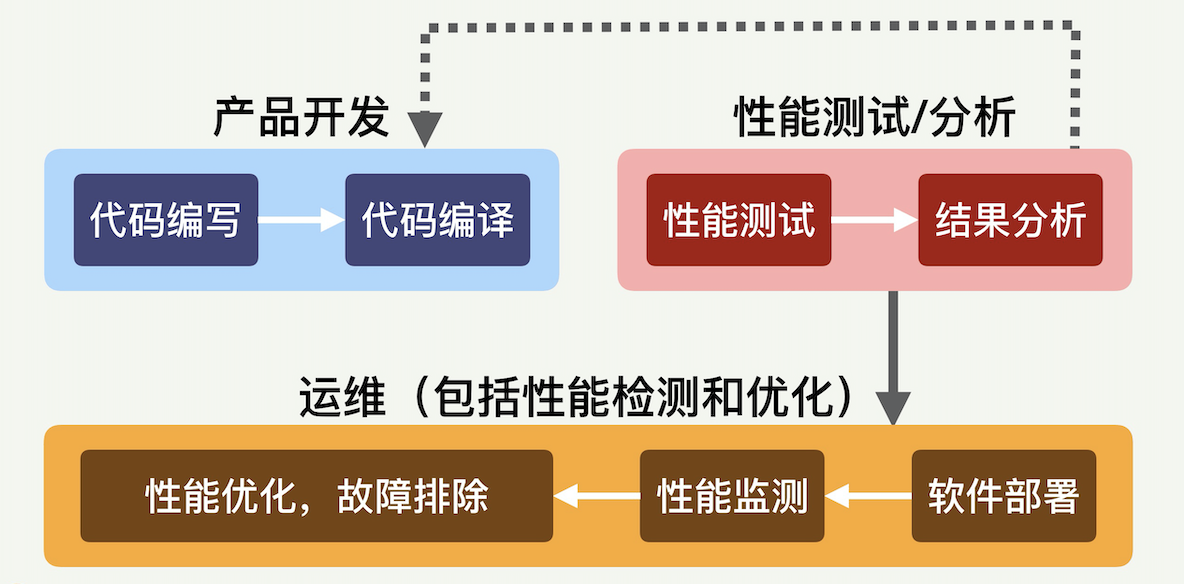
什么是“持续集成”呢?这个概念已经在软件开发领域存在很多年了,本来是为了配合敏捷开发(Agile Developement)的速度和效率而产生的,是把源代码管理、代码检查、程序编译、性能和功能测试、产品部署等一系列操作整合在一起的概念和工具。
怎么才叫“持续”呢?就是从程序员提交了源码开始,相关工具就会自动进行编译、测试等一系列运作,并将结果反馈给程序员。这样,提交代码的程序员很快就会知道刚刚提交的代码有没有问题。可能发生的问题有很多种,包括编译错误、整个程序不能运作、能编译运行但是整体性能变差等等。如果发现这样的问题,程序员和团队就可以迅速进行改正,不必等到开发周期后期才寻找和修复缺陷。
什么叫“集成”?就是上述一套操作都是有相应工具支持的,几个工具又集成在一起,构成一个完整的系统。
持续集成包括两个重要阶段:持续交付和持续部署。
持续交付(Continuous delivery)指的是开发人员的每一次代码提交,都会自动地编译,并且运行已经定义好的测试程序。测试程序里面就包括性能测试和结果分析。如果分析的结果确认这次代码提交没有性能问题,就成功接受这次提交。否则,就会采取措施通知代码提交者去修正代码;并重复这个过程,直到通过。
持续部署(Continuous deployment)是持续交付的下一步,指的是代码通过评审以后,自动部署到真正的生产环境。持续部署的目标是,代码在任何时刻都是可部署的,并且是可以进入生产阶段的。持续部署的前提是能自动化完成测试、构建、部署等步骤。同时,如果一旦部署了的版本发生不能接受的问题,就需要回滚到上一个版本。这个回滚的过程也需要简单方便,否则会造成非常大的混乱。
持续集成的价值何在?持续集成的价值主要有几点:降低代码开发风险,及早发现集成错误,减少手动测试过程,快速生成测试结果,提高程序员和开发团队的安全感。同时,频繁的提交代码,也会鼓励和促使开发人员创建模块化和低复杂性的代码。
和运维业务的系统集成
广义上来讲,性能工作也是运维的一部分,包括性能测试、性能分析和性能优化。但是,如果把性能工作和其他运维业务分开来看,它就需要和其他运维业务有机而智能地集成。运维业务的一个趋势是智能化。
智能化的原因,是互联网数据量的变大,运维业务的多样化和复杂化,以及对运维服务质量要求的提高(比如低成本、低延迟、高防范)。这样一来,很多传统的运维技术和解决方案已经不能满足当前运维所需。另一方面,机器学习(ML)和 人工智能(AI)技术在飞速发展,这就推生了智能运维 AIOps(Artificial Intelligence for IT Operations),这是运维未来发展的必然趋势。
在这样一个趋势里,运维就需要和性能测试的过程紧密集成。
- 一是通过持续而智能的性能测试,能及时发现已有的和将来可能会发生的性能问题,从而快速修复和及时预防。比如,根据性能测试的结果,可能会发现在不久的将来,整个系统的某项资源会用光,有可能导致系统挂掉。这种情况,我们就可以提前采取相应的措施,来避免这一问题的发生。
- 二是通过不同种类的性能测试,来找出最佳的解决方案。或许,对有些简单的性能问题,我们能很容易发现和解决,但对很多复杂的性能问题,就比较难找出原因和确定最优方案。要找出最主要的性能问题根因,经常需要进一步的性能测试。即使找到根因,现代互联网服务产品的子模块之间依存度很高,互相的交互多而复杂。那么什么样的解决方案才是效果最好,最容易实现的的,往往需要进行进一步测试来验证。
性能测试和运维的集成必须有两个特点:有机和自动。
不管是性能衡量、问题预测、根因分析还是性能优化,人工去执行都非常费时费力,从而不可取。唯一可行的就是借助于人工智能来尽量自动化。除了持续自动地进行性能测试,发现性能问题还需要进行自动分析,找出问题后也要执行自动调整优化。我们的目标是让性能测试和运维业务进行智能的有机集成,其中的智能来自于对大数据的分析和机器学习。无论是本业务系统的历史数据,还是其他业务系统的数据,甚至是业界其他公司的数据和经验,都是机器学习的对象和分析的基础。同时,我们还需要注入适当的知识和规则,来帮助这一套集成的持续优化。在这一过程中,数据的采集和整理是一切的基础。公司层面需要全方位,实时、多维度、全量地对各种运维数据采集、整理和存储。这里的运维数据包括基础架构的机器监控数据,内网和外网的网络数据,公司业务流量数据,工单系统数据,日志监控数据等。这些数据需要有统一而合理的接口,以方便访问。
性能工程实践
如何在生产环境中进行真实的容量测试?
LinkedIn 公司生产实践,在生产环境中进行真实场景的压力测试。
LinkedIn 为超过 5.9 亿用户提供服务,在性能优化的过程中,经常会遇到这类问题:一个服务可以承受的最大 QPS 是多少?要满足 100K QPS 的服务需求,我需要多少服务器?
怎么解决这些问题呢,有一个大招就是在生产环境中进行真实的容量测试。关于这个实践的详细方案和技术细节,我们曾经发表过一篇研究论文:RedLiner: Measuring Service Capacity with Live Production Traffic,并且很荣幸地获得了 IEEE 最佳论文奖。
Abstract:
Accurate capacity measurement of Internet services is critical to ensure high-performing production computing environments. In this work, we present our solution of performing accurate capacity measurement. Referred to as "Redliner", it uses live traffic in production environments to drive the measurement, hence avoiding many pitfalls that prevent capacity measurement from obtaining accurate values in synthetic lab environment. Redliner works by intelligently redirecting a portion of production traffic to the SUT (Service Under Test) and realtime analyzing the performance. It has been adopted by hundreds of services inside LinkedIn and is executed for various types of capacity analysis on a daily basis.
为什么需要在生产环境中进行容量测试?
一个在线互联网公司的存活和发展,靠的是它提供的互联网在线服务,自然也就依赖于这些服务的性能和稳定性。要保证每个服务都能够稳定地运行,我们必须为之提供足够的服务容量,比如适当数量的服务器。那么要如何保证服务容量足够呢?首先就必须做好服务容量的预测。要预测服务容量,我们就需要做容量的性能测试。一般是先确定每台单独的服务器可以支撑多少服务流量;然后用这个单台服务器的数据,来决定这个服务整体需要多少台服务器。这种测试其实就是我们前面讲过的容量测试。举个具体例子,如果测试结果表明,一台服务器最多可以支撑 100 个 QPS,那么要满足 100K QPS 的服务需求,总共就需要部署一千台服务器。
一般来说,公司提供的服务大致上分为两种:前端服务和后端服务。前端服务是什么样呢?包括各种服务的登陆页面和移动 App,这些服务会直接影响用户的体验。后端服务呢,一般是为前端服务和其他后端服务提供数据和结果。后端服务可以有多种,比如键值数据存储服务(例如,Apache Cassandra),和公司内部的各种微服务。
测试为什么需要在生产环境中进行呢?在非生产环境中的容量测试,执行起来肯定更简单啊!没错,的确会更简单,但是,在实验环境或者其他非生产环境中做这样的测试,比如采用人工合成的流量负载,会非常不准确。
这是因为实际的生产环境里面,有多个特殊因素会导致和非生产环境中不同的结果。比如:
- 客户需求会随着时间而变化,例如高峰时段与非高峰时段的流量就很不一样;
- 用户请求的多样性,例如不同国家的查询类型不同;
- 负载流量的规模,基础架构设施的变化,例如服务的软件版本更新,微服务互相调用的变化等等。
所以,对一个重要而复杂的互联网在线服务,由于难以在非生产环境中进行准确的容量测试,我们经常需要转向真正的生产环境,使用实时而真实的客户流量负载来测试。所以,想要在非生产环境中进行准确的容量测试基本上是做不到的。而对一个重要而复杂的互联网在线服务,能够做到准确的容量测试又太重要了。因为准确的容量数据,是保证线上服务的可靠运行和控制公司成本的基础。那怎么办呢?这时候我们就需要转向真正的生产环境,使用实时而真实的客户流量负载来测试。
如何在真实生产环境中进行容量测试?
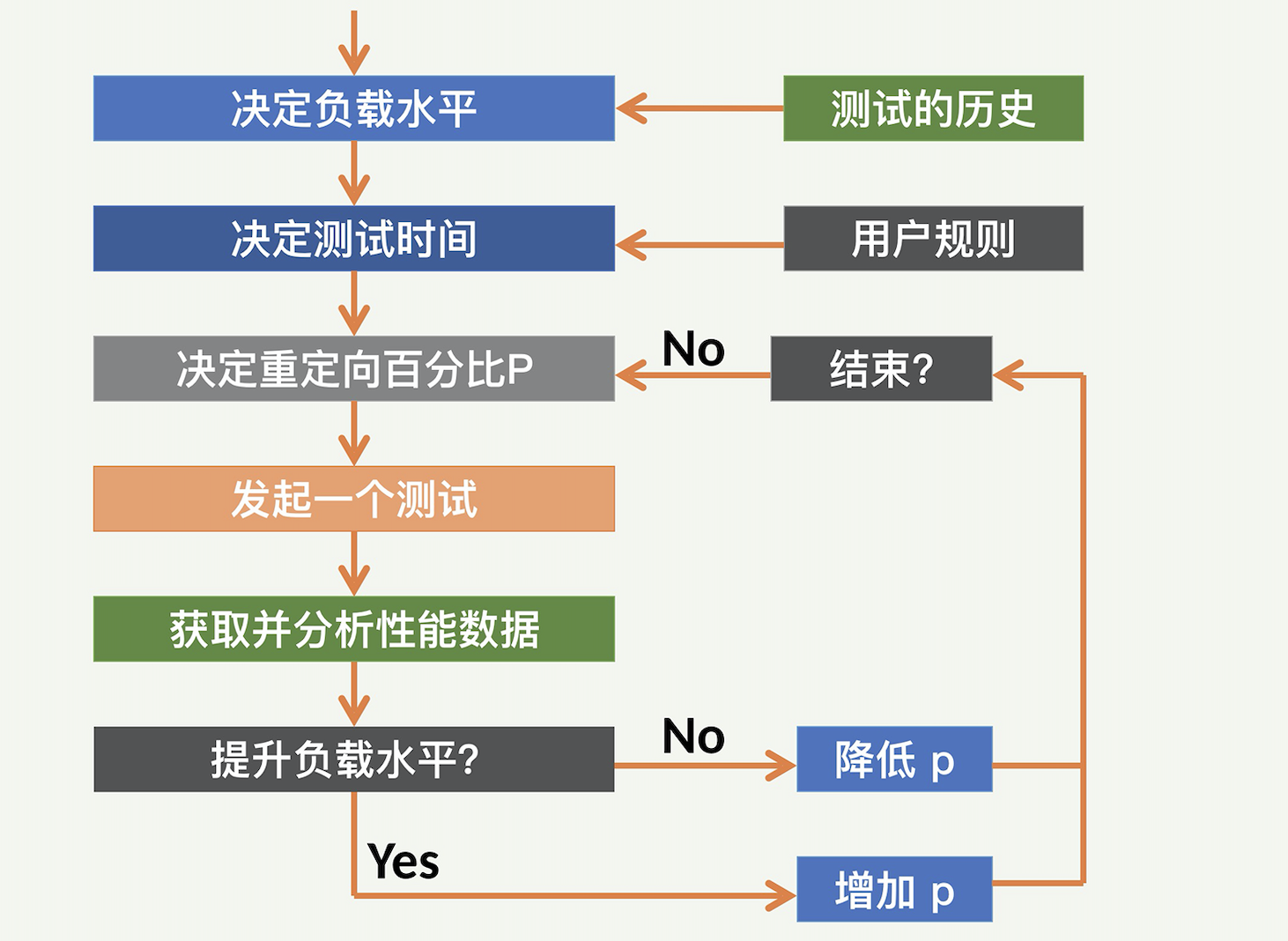
一般来说,我们需要把生产环境的流量进行重定向,让这些重定向的流量,实时地驱动运行 SUT 的单个或者几个服务器。根据重定向的流量大小,会产生不同级别的流量负载。通过仔细地操作重定向的多少,并且把握测试的时间,我们可以获得非常准确的运行 SUT 服务器的容量值。
但是,生产环境中的容量测量也有诸多挑战:
- 第一个挑战是需要设计一个控制重定向流量的机制。这个机制要能够根据其他一些参数,来调整重定向的流量多少。
- 第二个挑战(也是最大的挑战)是这种重定向生产流量可能会影响真正的客户。因为我们会把客户请求重定向到某个服务器,并且会不断给服务器加压,直到这个服务器接近超载,那么这个服务器上所有的客户请求的延迟都会受影响,也就是可能会变大,用户性能也就可能会受到损害。为了尽量减少对客户的影响,我们的容量测试需要设计合适的机制,来将这种可能的损害降到最低点。系统里面必须有一个模块,来不断地监测客户的性能;一旦到达临界点,就停止继续加压的操作,甚至适当减压。这就是所谓的“非侵入性”(Non-Intrusive)。
- 还有一个挑战是对于测试时间的控制。既然重定向生产流量可能影响客户性能,当然是测试的时间越短越好。可是测试时间太短的话,又可能会影响数据的稳定性。
为了应对这些挑战,准确地确定服务容量的极限,并精确定位容量瓶颈,LinkedIn 采用了一个解决方案,我们将它命名为 RedLiner。
宏观来讲,Redliner 是固定一个生产环境中的 SUT,这个 SUT 包括服务器和上面运行的被测服务,然后不断地把其他服务器上的流量,重定向到这个 SUT 服务器上面。随着流量的不断增大,这个 SUT 服务器的资源使用也就越来越多,所服务的客户请求的性能,比如端到端延迟,就会越来越差。直到客户请求的性能差到一个定好的阈值,比如端到端延迟是 200 毫秒,流量重定向才会停止。这个时候,基本就可以确定 SUT 服务器不能再处理任何额外的负载。此时获得的容量结果就是 SUT 服务器的最大容量。
合理方案的设计原则,一共是五条:
- 要使用实时流量以确保准确性。
- 尽量不影响生产流量,这就需要实时的监测和反馈模块。
- 可以定制重定向等行为规则;对不同的服务和不同的场景的测试,各种性能指标和阈值都会不同。
- 能自动终止测试,并把测试环境复位,尽量减少人工干预。
- 支持基于日历和事件的自动触发和调度。
RedLiner (LinkedIn 生产环境容量评估方案)
那这个方案具体是怎么实现的呢?现在来看看解决方案的高层架构,如下图所示,这个方案主要包括四个组件:
- 核心控制器 LiveRedliner
- 重定向流量的 TrafficRedirector
- 收集性能数据的 PerfCollector
- 分析性能数据的 PerfAnalyzer
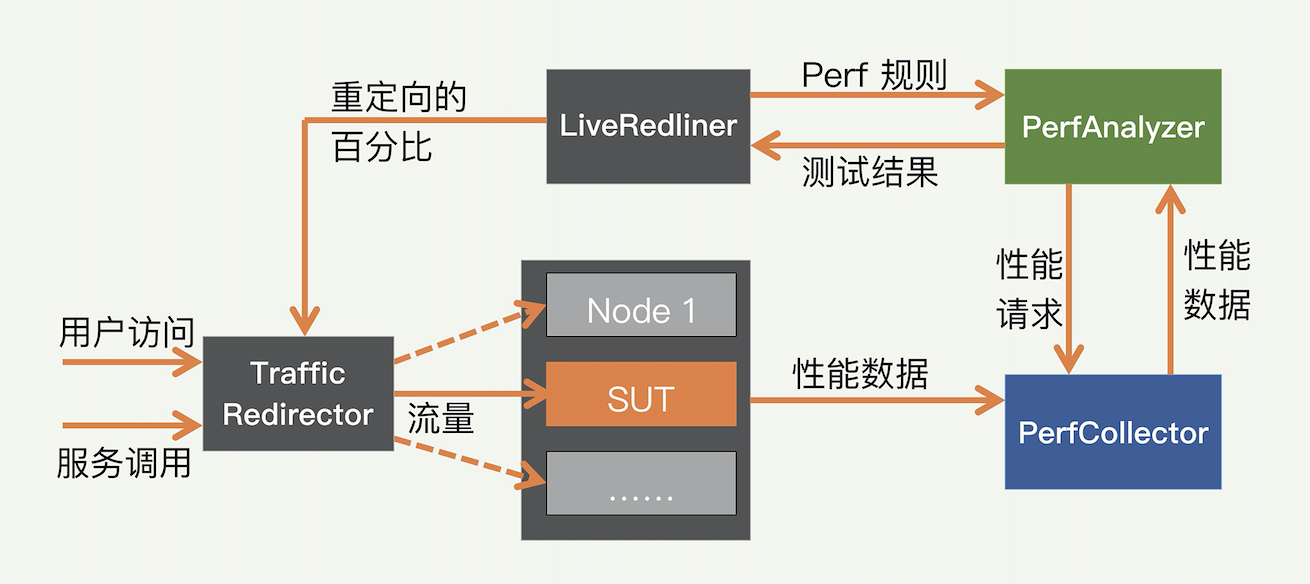
Redliner 作为一个完整的解决方案,通过几个模块互相配合来实现真实的线上容量测试。通过动态地调整线上的流量,直到让被测系统临近超载状态,从而获得准确的单位服务容量。
核心控制组件 LiveRedliner
核心控制组件是整个系统的神经中枢,负责总体调度容量测试的过程。比如何时发起测试,何时终止测试,何时需要增加更大的流量等等。用户可以自己定义一些特殊的规则,来更好地控制整个测试。用户可以自定义性能指标的阈值。这些性能指标,可以是用户的端到端延迟,包括各种统计指标,比如 P99。也可以把几个不同的性能指标组合起来,实现复杂的逻辑,比如“端到端延迟不超过 200 毫秒,并且错误率不超过 0.1% 等”。
重定向流量组件 TrafficRedirector
重定向流量组件负责对生产流量进行重定向。具体的实现机制,根据被测试的服务类型分为两种:前端服务和后端服务。
用于前端服务时,Redliner 是通过客户请求的属性(例如用户 ID、语言或帐户创建日期),来决定是否对一个客户请求来进行重定向的。这个转换也很简单,可以是取模机制。举个例子来说,如果 Redliner 需要重定向 1%的流量,它可以把用户的一个属性比如 userid 转换成整数,然后执行用 100 来取模的操作,并且和一个固定整数值作比较。
用于后端服务时,重定向流量可以通过另外一个叫做“资源动态发现和负载均衡”的模块来实现。在 LinkedIn,我们很多的服务负载均衡机制,一般会采用一个服务器列表(URI 集群),以相对应的权重值来决定一个请求发送到哪个服务器。
假设这样一个机制有 10 个可用的 URI 集群,并且最初所有这些集群都接收等量的流量(即每个 URI 的权重为 10%)。如果 Redliner 决定将 20%的流量重定向到特定的 URI(即 SUT),那么它可以为 SUT 的 URI 分配 20%的权重。
性能数据收集组件 PerfCollector
容量测试必须采集各种类型的性能指标,例如 CPU,内存和 QPS 等。这些性能指标的作用,就是确定 SUT 何时达到其容量最大值,以及容量值是多少。
PerfCollector 组件负责收集各种性能指标,包括系统级和服务级的指标。这个组件运行在所有受监视的节点。组件传递的数据量通常很大,因为一般要监测较多的性能指标。所以最好采用扩展性好的实时消息传递系统,来把这些性能数据及时传到其他组件。我们采用的消息传递系统是 Kafka。Kafka 也是由 LinkedIn 设计并开源的,扩展性和性能都很好。
性能分析组件 PerfAnalyzer
收集性能指标是第一步,下一步就是分析性能,并采取相应的措施。具体来说,可以根据性能指标的值来确定 SUT 是否饱和。
根据性能数据和用户定义的规则,如果发现当前的 SUT,仍有空间来承担更多的负载,我们可以将更大比例的实时流量重定向到该 SUT。否则,如果 SUT 显示饱和迹象,那么重定向的流量百分比就应该降低。PerfAnalyzer 组件能分析收集的数据,并确定是否有特定指标是否违反用户定义的规则。
网络数据传输慢,问题到底出在哪了?
网络传输问题其实就分两种:
- 数据根本没有传递
- 数据传送速度较慢
数据没有传递”虽然看起来更严重,但是相对“数据传送缓慢”来说,更容易判断和解决。所以,重点讨论第二种问题。有哪些可能的原因会导致数据传输缓慢呢?在宏观上,这种问题的可能原因可以分为三种场景:
- 客户端应用程序的原因
- 网络的原因
- 服务器应用程序的原因
也就是说,可能是由于数据发送方过载,而没有向接收方发送数据;也可能是网络通道很慢;又或者是数据接收方的服务器太忙,从而无法从网络缓冲区读取数据。
为了描述方便,我们根据平时客户浏览网页的场景,假设客户端是数据接收方,而服务器端是数据发送方。
如何判断问题所在位置?
这个解决方案本质上依靠的是客户端和服务器端的 TCP 层面的特征。TCP 是传输层协议之一,可提供有序且可靠的流字节传输,是当今使用最广泛的传输协议。TCP 具有流控制功能,可避免接收方过载。接收方设置专用的接收缓冲区,发送方设置相应的发送缓冲区。数据发送方(服务器)的发送缓冲区和数据接收方(客户端)的接收缓冲区,都可以通过操作系统来监测当前队列大小。为了能够识别瓶颈,你需要在发送方和接收方的传输层上,收集有关队列大小的信息。有很多收集此类信息的方法。有两种工具可以使用,分别是 netstat 和 ss (Socket Statistics)。
ss -s:显示当前 Sockets 概要信息
$ ss -s
Total: 554
TCP: 33 (estab 22, closed 0, orphaned 0, timewait 0)
Transport Total IP IPv6
RAW 2 1 1
UDP 5 4 1
TCP 33 29 4
INET 40 34 6
FRAG 0 0 0
ss -altp:显示正在监听的 TCP 程序的 process
ss -atlp
State Recv-Q Send-Q Local Address:Port Peer Address:Port Process
LISTEN 0 100 127.0.0.1:42222 0.0.0.0:*
LISTEN 0 1024 127.0.0.1:38249 0.0.0.0:* users:(("code-f1e16e1e62",pid=2964278,fd=9))
LISTEN 0 3000 127.0.0.1%lo:60020 0.0.0.0:*
LISTEN 0 3000 9.134.129.173%eth1:60020 0.0.0.0:*
LISTEN 0 128 0.0.0.0:56000 0.0.0.0:*
LISTEN 0 128 0.0.0.0:36000 0.0.0.0:*
LISTEN 0 4096 9.134.129.173:48369 0.0.0.0:*
LISTEN 0 4096 *:9150 *:*
LISTEN 0 4096 [::1]:34245 [::]:* users:(("java",pid=718680,fd=160))
LISTEN 0 4096 [::1]:43409 [::]:* users:(("java",pid=720687,fd=160))
LISTEN 0 128 [::]:36000 [::]:*
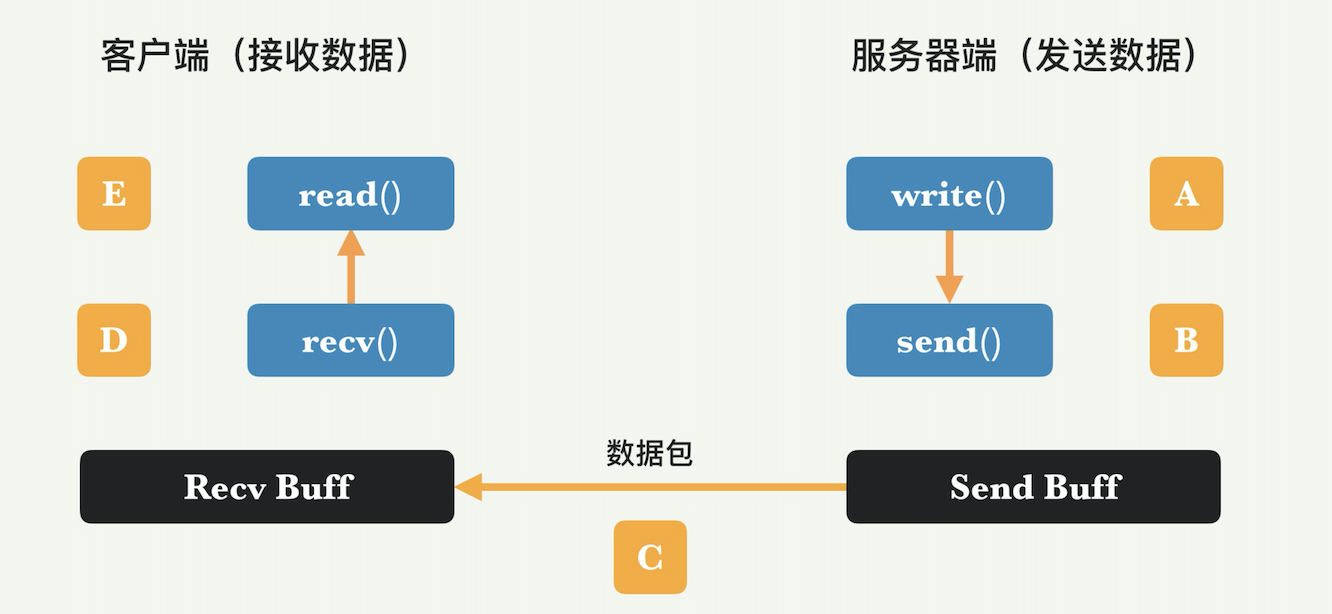
上图显示了任何基于 TCP 的数据传输中的典型流程。关于系统调用和网络传输的五个步骤如下:
- 在步骤 A,服务器应用程序发出 write() 系统调用,并将应用程序数据复制到套接字发送缓冲区。
- 在步骤 B,服务器的 TCP 层发出 send() 调用,并将一些数据发送到网络;数据量受 TCP 的拥塞控制和流控制。
- 在步骤 C,网络将数据逐跳路由到接收方(IP 路由协议在这部分中发挥作用)。
- 在步骤 D,客户端的 TCP 层将通过 recv() 系统调用接收数据,数据放入接收缓冲区。
- 在步骤 E,客户端应用程序发出 read() 调用,以接收数据并将其复制到用户空间。
场景1:客户端接收数据缓慢
为了重现这一场景,我们做一个实验,让发送端发送一段固定大小的数据给接收方。我们强制接收方,也就是客户端,减慢数据的接收速度。具体做法,就是在应用程序代码的 read() 调用之前,注入了一定的延迟,这种场景代表了客户端数据接收成为瓶颈的情况。
数据发送方的发送缓冲区,SendQ(Send Queue)的大小变化。开始时候,数据发送调用 send(),立刻注满 SendQ。随着数据的传输,慢慢变为 0。
客户端的接收缓冲区,RecvQ(Receive Queue)的大小变化,客户端因为应用程序运行缓慢,所以 RecvQ 具有一定的积累,这可以由非零值来看出。这些非零值持续了一段时间,随着应用程序不断地读取,最终 RecvQ 减为 0。
场景2:数据发送方是瓶颈
我们强制发送方(即服务器端),放慢数据的发送速度。具体来说,我们在应用程序代码中,对 write() 的调用之前注入了一定的延迟,模拟了发送者是瓶颈的情况。
服务器端的 SendQ 的值,可以看到,SendQ 几乎全部是零。这是因为发送端是瓶颈,其他地方不是瓶颈,所以任何 SendQ 的数据会被很快发送出去。可以在图片中看到一个持续时间很短的峰值,这是因为 SendQ 取样的时候恰好取到数据还没有被传输到网络中的时候。但因为这个峰值持续时间很短,简单的过滤就可以去掉。
接收端的 RecvQ,可以看到,因为接收端不是瓶颈,RecvQ 是零。
场景3:网络本身是瓶颈
我们通过向网络路径注入延迟来创造这一场景,以使 TCP 仅能以非常低的吞吐量进行传输。
发送端的 SendQ 值,你可以看到它的值不为零,因为那些数据不能很快地被传送出去。
接收端的 RecvQ,RecvQ 全为零,这些零值就代表了快速的数据传递。
总结
通过上面三种场景的分析,尤其是对发送端 SendQ 和接收端 RecvQ 的观察,不难总结出规律来。正常的数据传输情况下,客户端的接收队列和服务器端的发送队列都应该是零。
反之,如果数据传输缓慢,则有如下几种情况:
- 如果客户端上的接收队列 RecvQ 不为零,则客户端应用程序是性能瓶颈;
- 如果服务器上的发送队列 SendQ 为零,则服务器应用程序是性能瓶颈;
- 如果客户端的接收队列 RecvQ 为零,而服务器的发送队列 SendQ 为非零,则网络本身是性能瓶颈。
性能优化思路
优化性能思路:常见方法
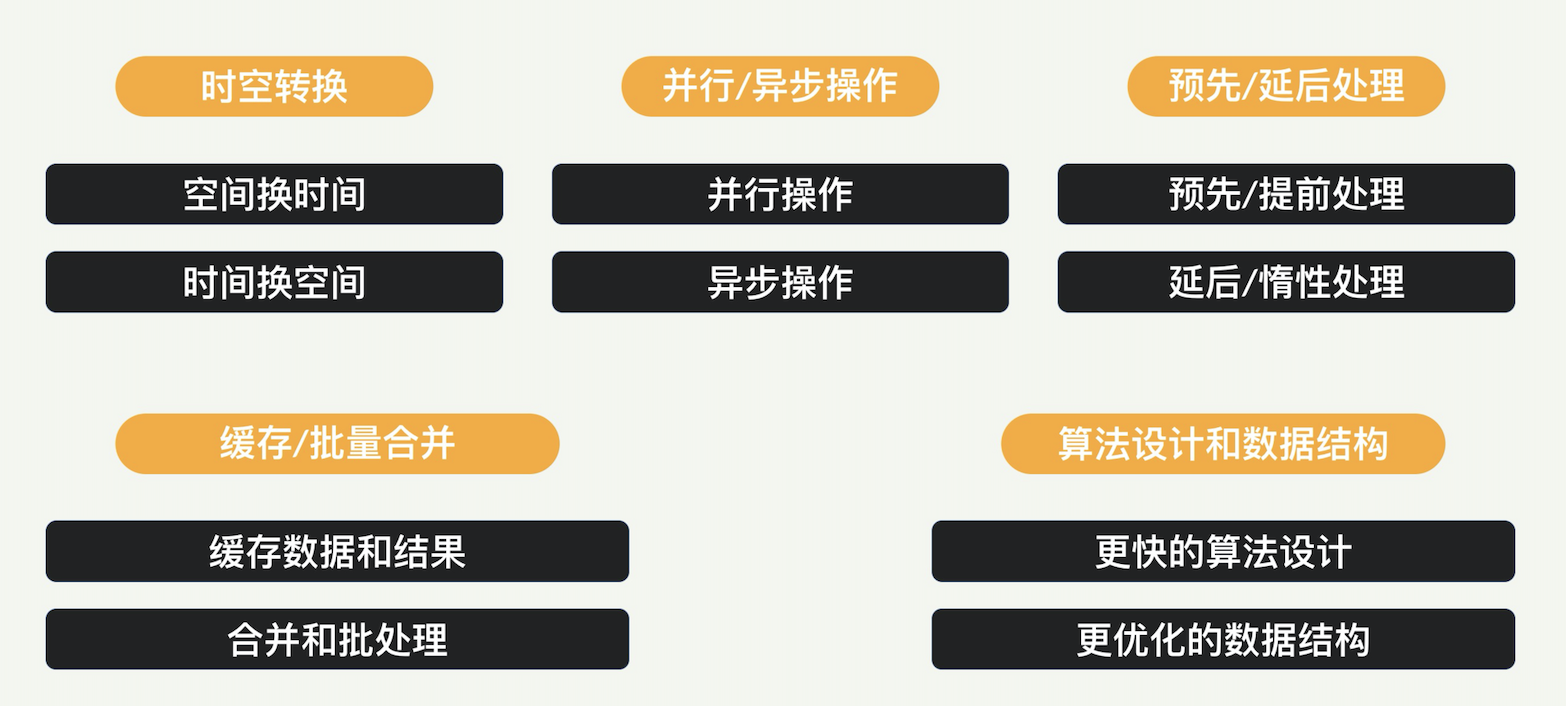
- 用时间换空间:压缩算法
- 用空间换时间:CDN 内容分发网络
- 预先 / 提前处理:文件系统有预读的功能,提前从磁盘读取额外的数据,为下次上层应用程序读数据做准备。这个功能对顺序读取非常有效,可以明显地减少磁盘请求的数量,从而提升读数据的性能。
- 延后 / 惰性处理:COW(Copy On Write,写时复制)。假设多个线程都想操作一份数据,一般情况下,每个线程可以自己拷贝一份,放到自己的空间里面。但是拷贝的操作很费时间。系统如果采用惰性处理,就会将拷贝的操作推迟。如果多个线程对这份数据只有读的请求,那么同一个数据资源是可以共享的,因为“读”的操作不会改变这份数据。当某个线程需要修改这一数据时(写操作),系统就将资源拷贝一份给该线程使用,允许改写,这样就不会影响别的线程。COW 最广为人知的应用场景,例如 Unix 系统 fork 调用产生的子进程共享父进程的地址空间,只有到某个子进程需要进行写操作才会拷贝一份。
- 并行操作:绝大多数互联网服务器,要么使用多进程,要么使用多线程来处理用户的请求,以充分利用多核 CPU。
- 异步操作:同步和异步的区别在于一个函数调用之后,是否直接返回结果。如果函数挂起,直到获得结果才返回,这是同步;如果函数马上返回,等数据到达再通知函数,那么这就是异步。Unix 下的文件操作,是有 block 和 non-block 的方式的,有些系统调用也是 block 式的,如:Socket 下的 select 等。如果我们的程序一直是同步操作,那么就会非常影响性能。采用异步操作的话,虽然稍微增加一点程序的复杂度,但会让性能的吞吐率有很大提升。
- 缓存数据:缓存的本质是加速访问。这是一个用得非常普遍的策略,几乎体现在计算机系统里面每一个模块和领域,CPU、内存、文件系统、存储系统、内容分布、数据库等等,都会遵循这样的策略。
- 批量合并处理:在有 IO(比如网络 IO 和磁盘 IO)的时候,合并操作和批量操作往往能提升吞吐量,提高性能。对数据库的读写操作,也可以尽量合并。比如,对键值数据库的查询,最好一次查询多个键,而不要分成多次。
- 先进的算法:同一个问题,肯定会有不同的算法实现,进而就会有不同的性能。比如各种排序算法,就是各有千秋。有的实现可能是时间换空间,有的实现可能是空间换时间,那么就需要根据你自己的实际情况做权衡。
- 高效的数据结构:没有一个数据结构是在所有情况下都是最好的,比如你可能经常用到的 Java 里面列表的各种实现,包括各种口味的 List、Vector、LinkedList,它们孰优孰劣,取决于很多个指标:添加元素、删除元素、查询元素、遍历耗时等等。我们同样要权衡取舍,找出实际场合下最适合的高效的数据结构。
优化性能思路: 硬件优化 (软硬结合)
计算机方面的知识可以大体上分为两大类:软件相关和硬件相关。很多程序员对软件相关的知识了解多些,但对硬件方面了解不多。但是,因为很多性能问题会牵扯到硬件,所以基本要求就是“能软能硬”,两方面的知识都要足够。
对下层的软硬件构件越是了解,就越有可能设计出性能优越的模块和应用程序。
- DRAM 内存就是一种存储,它速度很快,但是价格贵、容量小,并且所存数据不能长期保存,一断电数据就会丢失。
- 最近几年一种新的非易失性内存(NVM,Non-volatile Memory)的出现,打破了这一传统,数据可以长期保持,但是速度稍微慢一些。
- 固态硬盘(SSD) 的大量采用,在很多新设计的在线系统中已经作为标准配置,几乎取代了传统硬盘。
优化性能思路: 宏观思维
从公司运营的角度来看,整个互联网大服务的性能才是我们每个程序员真正关心和负责的。我们每人都需要从这个大局出发来考虑和分析问题,来设计自己的模块以及各种交互机制。否则,可能会出现我们的模块本身看起来设计得不错,但却对上下游模块造成不好的影响,进而影响整个大服务的性能。
某个下游模块出现延展性问题,服务的延迟变大,上游模块发出的请求排了很长的队。这个时候上游模块已经感觉到下游的性能问题,因为对下游请求的处理延迟已经大幅度增加了。此时上游模块本应该怎么做呢?它应该降低对下游模块的请求速度,从而减轻下游模块的负担。但是案例中的上游模块设计没有考虑到这一点。不但没有降低请求速度,反而发送了更多的请求,以求得更快的回答。这样无异于火上浇油,最后导致下游模块彻底挂掉,引发了整个服务的瘫痪。
后来我们学到的教训就是,串联的服务模块中,上游模块必须摒弃这样雪上加霜的服务异常尝试,应该采用指数退避机制(Exponential Backoff),通过快速地降低请求速度来帮助下游模块恢复(上游模块对下游资源进行重试请求的时间间隔,要随着失败次数的增加而指数加长)。
优化性能思路: 公司的成本
一个高性能的服务,在服务同等数量的客户时,需要的成本会比较小。具体来说,如果我们的服务是计算密集型,那么就应该尽量优化算法和数据结构等方面来降低 CPU 的使用量,这样就可以用尽量少的服务器来完成同样的需求,从而降低公司的成本。
现如今是大数据时代,公司在服务器和数据中心以及网络等容量方面的支出是很可观的。尤其是大的公司比如脸书,腾讯等,公司有很多的数据中心和几百万台的服务器。如果公司的每个服务都做到高性能,替公司节省的运营成本是非常巨大的。
同时,面向互联网服务的容量规划和效率管理也很重要。如果能科学地管理容量,准确地预测未来需求,并逐步提升容量的效率,就能把公司这方面的成本管理和节省好,从而不至于浪费资金在不必要的多余容量上。
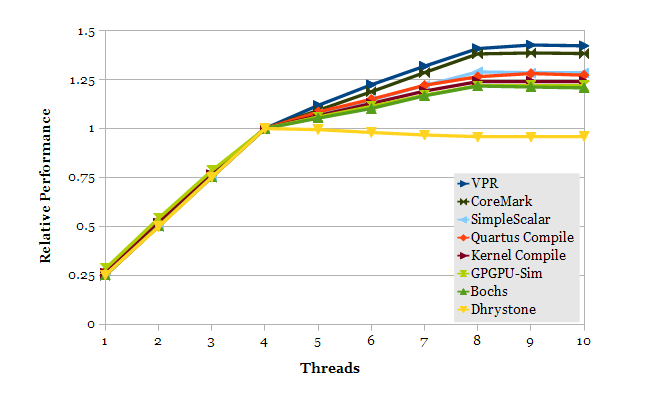
优化性能思路: 线程数量越多,性能越好?
为了提高服务器的 CPU 使用效率,提出把应用程序的线程池增大,建议程序线程池的主线程数目应该和服务器的逻辑 CPU 的数目相等,这个方案是否合理?(这里的逻辑 CPU,就是通常说的虚拟核数)
正确的做法:降低主线程池大小到逻辑 CPU 的一半,因为服务器的逻辑 CPU 不是物理 CPU。在超线程技术(Hyper Threading)的情况下,服务器的吞吐量不是严格按照逻辑 CPU 的使用率来提升的,因为两个逻辑 CPU 其实共享很多物理资源。
例如下面表示在一台有8个逻辑 CPU 的服务器上,如果部署超过 4 个线程,得到的性能提升非常有限,甚至可能会带来其他不好的后果。这里具体的提升率和效果,取决于线程和应用程序的特性。
优化性能思路: 选择不同的 unordered_map 提升性能
google::dense_hash_map 的性能可以比 std::unordered_map 快好几倍
优化性能思路: 汇编指令的性能优化
通过使用 GCC 的 __builtin_prefetch 指令来预先提取关键指令,从而降低缓存的缺失比例,提高 CPU 的使用效率

假设有一个处理大量数据的函数:
#include <stdio.h>
void process_data(int *data, size_t size) {
for (size_t i = 0; i < size; ++i) {
data[i] = data[i] * 2;
}
}
int main() {
int data[10000];
for (int i = 0; i < 10000; ++i) {
data[i] = i;
}
process_data(data, 10000);
printf("result: %d\n", data[9999]);
return 0;
}
可以使用 __builtin_prefetch 对 process_data 函数进行优化,以预先提取关键指令并降低缓存的缺失比例:
#include <stdio.h>
void process_data(int *data, size_t size) {
for (size_t i = 0; i < size; ++i) {
// 预先提取下一个数据元素,提前 16 个元素进行预取
if (i + 16 < size) {
__builtin_prefetch(&data[i + 16], 1, 1);
}
data[i] = data[i] * 2;
}
}
int main() {
int data[10000];
for (int i = 0; i < 10000; ++i) {
data[i] = i;
}
process_data(data, 10000);
printf("result: %d\n", data[9999]);
return 0;
}
在 process_data 函数中,添加了 __builtin_prefetch 指令来预先提取数组中的下一个元素。这样,当 CPU 处理当前元素时,下一个元素已经被预取到缓存中,从而减少了缓存缺失和等待指令获取的时间。请注意,这个优化可能在某些情况下对性能产生负面影响,因为预取操作可能会消耗内存带宽。在实际应用中,需要根据具体情况调整预取距离(在本例中为 16)并进行性能测试,以确保优化达到预期效果。
Refer
- Brendan Gregg’s Homepage
- LinkedIn 公司的 Engineering Blog
- Netflix 公司 的 Netflix TechBlog