Linux Kernel in Action
内存相关
内存的分配机制
内存不是无限的,总有不够用的时候,linux 内核用三个机制来处理这种情况:内存回收、内存规整、oom-kill。
当发现内存不足时,内核会先尝试内存回收,从一些进程手里拿回一些页;如果这样还是不能满足申请需求,则触发内存规整;再不行,则触发 oom 主动 kill 掉一个不太重要的进程,释放内存。
低内存情况下,内核的处理逻辑:
- 内存申请的核心函数是
__alloc_pages_nodemask。__alloc_pages_nodemask会先尝试调用get_page_from_freelist从伙伴系统的freelist里拿空闲页,如果能拿到就直接返回。 - 如果拿不到,则进入慢速路径
__alloc_pages_slowpath,慢速路径,顾名思义,就是拿得慢一点,需要做一些操作以后再拿。首先,__alloc_pages_slowpath会唤醒kswapd,kswapd是一个守护进程,专门进行内存回收操作,执行路径:kswapd -> balance_pgdat -> kswapd_shrink_node -> shrink_node,它被唤醒后,会立刻开始进行回收,效率高的话,freelist上会立刻多出很多空闲页。所以__alloc_pages_slowpath会马上再次尝试从freelist获取页面,获取成功则直接返回了。 - 若还是失败,
__alloc_pages_slowpath则会进入direct_reclaim阶段。direct_reclaim顾名思义,就是直接内存回收,回收到的页不用放回freelist再get_page_from_freelist这么麻烦了,也不用唤醒某个进程帮忙回收,而是由当前进程(current)亲自下场去回收,执行路径:__alloc_pages_direct_reclaim -> __perform_reclaim -> try_to_free_pages -> do_try_to_free_pages -> shrink_zones -> shrink_node。如果direct_reclaim也回收不上来,__alloc_pages_slowpath还会垂死挣扎下,做一下内存规整,尝试把零散的页辗转腾挪,拼成为大 order 页(仅在申请 order>0 的页时有用)。 - 如果还是无法满足要求,则进入 oom-kill 了。
总结:内存申请时,首先尝试直接从 freelist 里拿;失败了则先唤醒 kswapd 帮忙回收内存;若内存低到让 kswapd 也爱莫能助,则进入 direct reclaim 直接回收内存;若 direct reclaim 也无能为力,则 oom。
上述过程可参考 https://github.com/torvalds/linux/blob/master/mm/page_alloc.c#L4697 代码
/*
* This is the 'heart' of the zoned buddy allocator.
*/
struct page *__alloc_pages_noprof(gfp_t gfp, unsigned int order,
int preferred_nid, nodemask_t *nodemask)
{
struct page *page;
unsigned int alloc_flags = ALLOC_WMARK_LOW;
gfp_t alloc_gfp; /* The gfp_t that was actually used for allocation */
struct alloc_context ac = { };
/*
* There are several places where we assume that the order value is sane
* so bail out early if the request is out of bound.
*/
if (WARN_ON_ONCE_GFP(order > MAX_PAGE_ORDER, gfp))
return NULL;
gfp &= gfp_allowed_mask;
/*
* Apply scoped allocation constraints. This is mainly about GFP_NOFS
* resp. GFP_NOIO which has to be inherited for all allocation requests
* from a particular context which has been marked by
* memalloc_no{fs,io}_{save,restore}. And PF_MEMALLOC_PIN which ensures
* movable zones are not used during allocation.
*/
gfp = current_gfp_context(gfp);
alloc_gfp = gfp;
if (!prepare_alloc_pages(gfp, order, preferred_nid, nodemask, &ac,
&alloc_gfp, &alloc_flags))
return NULL;
/*
* Forbid the first pass from falling back to types that fragment
* memory until all local zones are considered.
*/
alloc_flags |= alloc_flags_nofragment(zonelist_zone(ac.preferred_zoneref), gfp);
/* First allocation attempt */
page = get_page_from_freelist(alloc_gfp, order, alloc_flags, &ac);
if (likely(page))
goto out;
alloc_gfp = gfp;
ac.spread_dirty_pages = false;
/*
* Restore the original nodemask if it was potentially replaced with
* &cpuset_current_mems_allowed to optimize the fast-path attempt.
*/
ac.nodemask = nodemask;
page = __alloc_pages_slowpath(alloc_gfp, order, &ac);
out:
if (memcg_kmem_online() && (gfp & __GFP_ACCOUNT) && page &&
unlikely(__memcg_kmem_charge_page(page, gfp, order) != 0)) {
__free_pages(page, order);
page = NULL;
}
trace_mm_page_alloc(page, order, alloc_gfp, ac.migratetype);
kmsan_alloc_page(page, order, alloc_gfp);
return page;
}
三条水线
实际上,从 freelist 上拿页不是简单地直接拿,而是先检查下该 zone 是否满足水线要求,不满足那就直接失败。内核给内存管理划了三条水线:MIN、LOW、HIGH。三者大小关系从字面即可推断,MIN < LOW < HIGH。在首次尝试从 freelist 拿页时,门槛水线是 LOW;唤醒 kswapd 后再次尝试拿页,门槛水线是 MIN。
所以,可以简单地认为,可用内存低于 LOW 水线时,唤醒 kswapd;低于 MIN 水线时,进行 direct reclaim;而 HIGH 水线,是 kswapd 的回收终止线:
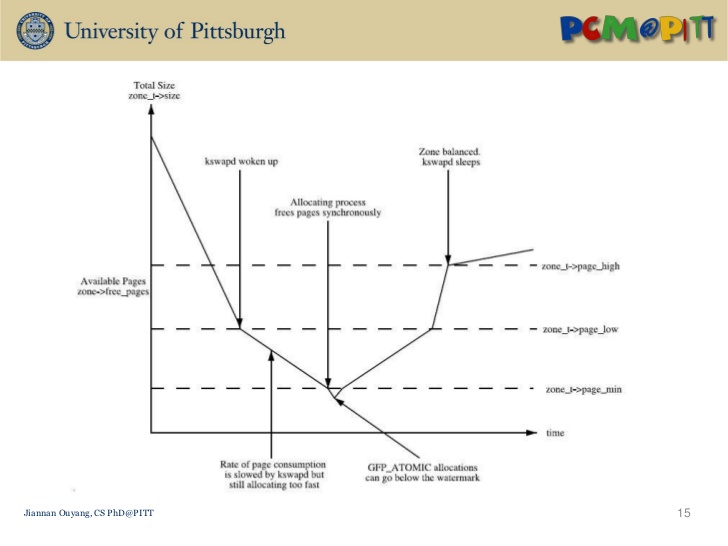
从这张图可以看出:
- 当内存容量小于低位水线 LOW,则开始启动
kswapd回收内存 - 当内存容量小于最小水线 MIN,则开启直接回收
- 当内存容量高于高位水线 HIGH,则
kswapd可以休息
refer:
- https://richardweiyang-2.gitbook.io/kernel-exploring/nei-cun-guan-li/00-index-1/02-watermark
为什么内存回收时,磁盘 IO 会被打满?
可以看到,kswapd 和 direct_reclaim 最终都是走到了 shrink_node。shrink_node 是内存回收的核心函数,顾名思义,让整个 node 进行一次“收缩”,把不要的数据清掉,空出空闲页。


get_scan_count 决定本次扫描多少个 anon page 和 file page。
anon page 就是 Anonymous Page,匿名页,是进程的堆栈、数据段等。内核回收匿名页时,将这些数据进行压缩(压缩比大概为3),然后移动到内存中的一个小角落中 swap 空间,这个过程并没有与磁盘发生交互,因此不会产生 IO,但需要压缩数据,所以耗 CPU。
file page 就是文件页,是进程的代码段、映射的文件。内核回收文件页时,先将“脏”数据回写到磁盘,然后释放掉这些缓存数据,干净的数据则直接释放掉。这个过程涉及到写磁盘,因此会产生 IO。
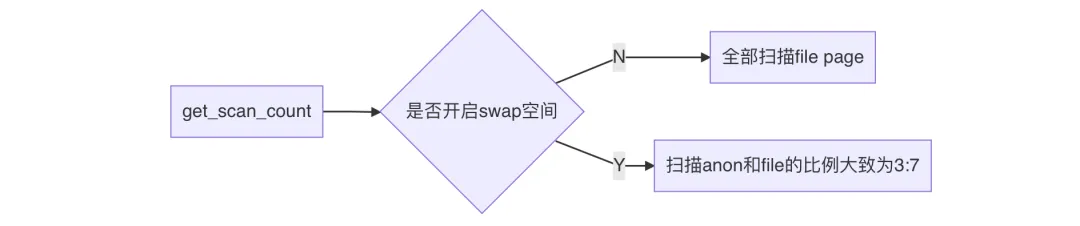
所以说,不论开没开
swap,内存回收都是倾向于回收 file page。如果 file page 中有脏页,那内存回收大概率就会产生一些 IO,无非是 IO 量多少罢了。
以下情况 IO 可能会打满或者暴增:
- 当前内存不是特别紧张,但 low、min 水线设置得太低,之前一直没怎么触发过内存回收,以致于脏页已经累积到大量,一触发回收,立刻就是回写大量脏页,导致 IO 暴增。
- 内存极度紧张(free 和 available 同时很低)。这种情况下,anon page 远比 file page 多,这意味着可回收的内存很少,内核会对活跃数据下手,一些进程上一秒还用着的数据,这一秒可能就被不幸回收了,但下一秒马上又要被使用,会再次被读入内存。如此,同一份数据,内核就进行了多次回收和读入,IO 就加倍了。
为什么低内存有时会引发 hungtask?
低内存时,通常不是个别进程触发了 direct reclaim,而是大量进程都在 direct reclaim。大家都要回写脏页,于是 IO 被打满了。这时候,进程会频繁地被 IO 阻塞,被阻塞的进程为了不占用 CPU,会调用 io_schedule_timeout 或 io_schedule 来挂起自己,直到 IO 完成。这种等待是 D 状态 (TASK_UNINTERRUPTIBLE 状态) 的,一旦超过了 120s 就会触发 hungtask。 当然,这是非常极端的情况,IO 已经完全没救的情况。
大部分时候,IO 虽然打满了,但是总能周转过来,所以这些进程并不会等太久。然而,这些进程若是来自同一个业务,则大概率会访问同一个数据,这就需要通过 mutex、rwsem、semaphore 等同步机制来控制访问行为。而这些同步机制的基本接口都是 uninterruptible 性质的。所谓 uninterruptible 性质,即当进程获取不到同步资源时,直接进入 D 状态等待其他进程释放资源。其他同步资源,rwsem、mutex 等,都有这样的 uninterruptible 性质函数。正常情况下,只要持有同步资源的进程正常运行不卡顿,那么即使有上百个进程来争抢这些同步资源,对于排序靠后的进程来说,时间也是够的,一般不会等待超过 120s。但在低内存情况下,大家都在等 IO,这些持有资源的进程也不能幸免,引发堵车连锁反应。如果此时同步资源的 waiter 们已累计了几十个甚至上百个,那么就算只有一瞬间的 IO 卡顿,排序靠后的 waiter 也容易等待超过 120s 从而触发 hungtask。
内核中的 hungtask 机制
长期以来,处于 D 状态 (TASK_UNINTERRUPTIBLE 状态)的进程都是让人比较烦恼的问题,处于 D 状态的进程不能接收信号,kill 不掉。在一些场景下,常见到进程长期处于 D 状态,用户对此无能为力,也不知道原因,只能重启恢复。
其实进程长期处于 D 状态肯定是不正常的,内核中设计 D 状态的目的是为了让进程等待 IO 完成,正常情况下 IO 应该会顺利完成,然后唤醒相应的 D 状态进程,即使在异常情况下 (比如磁盘离或损坏、磁阵链路断开等),IO 处理也是有超时机制的,原理上不会存在永久处于 D 状态的进程。但是就是因为内核代码流程中可能存在一些 bug,或者用户内核模块中的相关机制不合理,可能导致进程长期处于 D 状态,无法唤醒,类似于死锁状态。
针对这种情况,内核中提供了 hung task 机制用于检测系统中是否存在处于 D 状态超过 120s (时长可以设置)的进程,如果存在,则打印相关警告和进程堆栈。如果配置了 hung_task_panic(proc 或内核启动参数),则直接发起 panic,结合 kdump 可以搜集到 vmcore。从内核的角度看,如果有进程处于 D 状态的时间超过了 120s,那肯定已经出现异常了,以此机制来收集相关的异常信息,用于分析定位问题。
基本原理
hung task 机制的实现很简单,其基本原理为:创建一个内核线程 (khungtaskd),定期 120s 唤醒后,遍历系统中的所有进程,检查是否存在处于 D 状态超过 120s (时长可以设置) 的进程,如果存在,则打印相关警告和进程堆栈。如果配置了 hung_task_panic(proc 或内核启动参数),则直接发起 panic。
优化低内存处理
我们已经知道了低内存会导致 IO 突增,甚至导致 hungtask,那要如何避免呢?可以从两方面来避免。
- 调整脏页回刷频率。
将平时的脏页回刷频率调高,这样内存回收时,需要回收的脏页就更少,降低 IO 的增量。
调低 /proc/sys/vm/dirty_writeback_centisecs
调低 /proc/sys/vm/dirty_background_ratio
$ cat /proc/sys/vm/dirty_writeback_centisecs
500
$ cat /proc/sys/vm/dirty_background_ratio
10
- 调高 low 水线和 min 水线。
调高水线,可以更早地进入内存回收逻辑,这样可以将 free 维持在一个较高水平,避免陷入极端场景。 由于 low 和 min 同时受 min_free_kbytes 管控,所以可以直接调整 min_free_kbytes 值。
调高 /proc/sys/vm/min_free_kbytes
$ cat /proc/sys/vm/min_free_kbytes
45861
不同种类的低内存情况
脏页多时
Linux 内核虽然会对脏页进行周期性回刷,但当产生脏页的速度大于回刷速度时,脏页就会累积。可以模拟出这种情况,找一台 16G 内存的机器,执行以下命令产生脏页:
stress -d 1 --hdd-bytes 100M
查看内存脏页量的变化:
$ awk '/Dirty|MemFree|MemTotal/ {print}' /proc/meminfo
MemTotal: 131483996 kB
MemFree: 3373988 kB
Dirty: 396 kB
此时通过 iostat 可以看到,IO 读为 0,IO 写基本为 0,只有少量来自于周期性脏页回刷。
此时的 free 还是很多的,需要再给点内存压力,触发内存回收:
stress --vm 1 --vm-bytes 14.9G --vm-keep -t 60
加压后,kswapd 立刻被触发。kswapd 努力地回刷脏页,IO 读写都突增,不过读量远远小于写量。将内存压力去掉,kswapd 立刻停止,IO 读写入回到 0。也就是说,脏页多的情况下,触发内存回收时,IO 写大量突增,IO 读少量增加。
可用内存很低时
首先需要了解可用内存的定义:可用内存 = 空闲内存 + 可回收内存
- 空闲内存:指没被分配出去的内存,/proc/meminfo 里的 Memfree、 free 命令里的 free
- 可回收内存:指可以快速被回收的内存,包括大部分文件页和部分 slab
不同于空闲内存有个精确值,可回收内存是个比较模糊的范围,因为只有真正开始回收时,内核才能确定哪些是能回收的,哪些是不能回收的。
虽然无法精确,但是可以估算。内核对可回收内存进行了估算,并把这个估算值与精确的空闲内存相加,得出了可用内存的估算值,这个值就是 /proc/meminfo 里的 MemAvailable。当 MemAvailable 很小时,意味着空闲内存和可回收内存都不足了,此时稍微来一点内存申请,都可能一石激起千层浪,触发各种极端场景。
16G 内存的机器,对其加压14G,持续 60s:
stress --vm 1 --vm-bytes 14G --vm-keep -t 60
然后,快速申请 2G 内存:
stress --vm 1 --vm-bytes 2G --vm-keep -t 60
可以看到,很快就触发了 OOM,stress 进程被 OOM kill 了。这说明单次申请量过大,内核直接放弃了内存回收,触发 OOM 了。如果单次小幅度申请呢?观察 top,可以发现, kswapd0 的 CPU 使用率快速爬升,然后在接近打满一个核时,系统“卡死”,top 界面直接无响应了。此时,无论是新建一个新的 terminal,开始在老的 terminal 中不停地按 ctrl-c,系统都没有一点反应。这段时间内,不仅是系统无响应,CPU 和内存之类的监控也丢失。直到 60s 后 stress 命令施加的 14G 释放系统才恢复响应。查看这段时间的 D 住超过 10ms 的进程及其堆栈,可以看到这些 D 进程的堆栈几乎一样,都是在缺页异常处理中等待 IO。即程序访问文件的某个地址时,发现这个地址对应的内存数据不存在,于是将这些数据从磁盘加载到内存,触发了读 IO,进程陷入 D 状态等待 IO。通常情况,这种 D 状态会在 1ms 以内结束。而从上面堆栈来看,大量进程等 IO 都超多了 10ms,说明当时的 IO 状态不佳。查看 IO 监控,IO 读写都有突增,读远远大于写。这说明 IO 读将 IO 打满了,IO 到了性能瓶颈。那么,这些进程为什么会同时发生缺页异常,将 IO 打满?通过抓取当时的缺页异常 trace 发现:
- 这些地址对应的文件都是lib、可执行文件。说明缺页异常都来自于进程的代码段
- 大部分地址都累计缺页几百次。这说明在这短短 60s 内,这些地址对应的内存数据被反复地被释放,读入多达几百次
也就是说,kswapd 在这 60s 内对这些进程的代码段进行了反复回收,这些进程为了保持正常功能不得不再次读入代码段,然后又被 kswapd 收走。这样来回的拉扯使得 IO read 迅速增高,IO 被打满,于是进程每读一个地址,就需要等待 10ms 以上。并且 kswapd 是无差别攻击的,所以这些“被害”进程包括 sshd、systemd 、监控进程等关键进程,这些进程反复陷入 D 状态,于是系统整体上看上去就“卡死”了,并且丢失了部分监控数据。
那么 kswapd 为什么会这么“丧心病狂”地针对这些代码段呢?因为可回收内存不足,kswapd 只好对进程正在用着的代码段下手。这种情况会持续多久?kswapd 什么时候会停止回收?为什么没有触发 OOM?再来回顾一下内存回收的三条水线:
- 当空闲内存 < LOW 水线时,kswapd 被唤醒开始工作;
- 当空闲内存 > HIGH 水线时,kswapd 停止工作;
- 当空闲内存 < MIN 水线时,OOM 触发,有进程会被 kill。
回到这个场景:
- kswapd 对代码段的回收很高效,因为代码段是不可写的非脏页,只需直接释放即可。这样的高效使得新的内存申请会被立刻满足,空闲内存根本不会低于 MIN 水线,触发不了 OOM。
- 这些内存被回收走后,又会立刻被用于其他代码段,所以空闲内存也上不去,到达不了 HIGH 水线,所以 kswapd 也无法终止。
一句话概括:在这个场景下,空闲内存会一直处 [MIN, HIGH] 这个区间,kswapd 会一直工作,系统也不会触发 OOM。
那么,陷入这个死循环后,该如何破局呢?
乍看破局思路似乎很简单,让 free 跳出 [MIN, HIGH] 这个区间即可,比如再加压 2G,让 free 掉到 MIN 以下,或者手动 kill 某个占用大的内存,让 free 大于 HIGH。但其实这些很难实现,因为系统已经卡死了,响应命令的速度取决于磁盘性能的好坏。也就是说,陷入后这种状态后就很难出来了,要么耐心等待有进程突然释放或者申请大内存,要么重启。
对于这种场景,内核本身没有解决的机制吗?坦白地说,暂时没有。使用最新内核 6.10 做了同样的测试,系统依然是无响应,没有自动恢复。
有办法避免这个场景吗?还是老方法,提高 min_free 值,让 OOM 尽可能快地触发:调高 /proc/sys/vm/min_free_kbytes
怎样判断系统是否陷入了这个场景?
- 监控无数据,ssh 无法登录,执行命令无响应;
- 磁盘 IO 读大量突增,IO 写少量突增或者没有明显变化;
- 系统还能偶尔响应的话,执行 top 看到 kswapd0 的 CPU 使用率很高。
扩展
Kernel Samepage Merging
KSM is a memory-saving de-duplication feature, enabled by CONFIG_KSM=y, added to the Linux kernel in 2.6.32. See mm/ksm.c for its implementation, and http://lwn.net/Articles/306704/ and https://lwn.net/Articles/330589/
KSM was originally developed for use with KVM (where it was known as Kernel Shared Memory), to fit more virtual machines into physical memory, by sharing the data common between them. But it can be useful to any application which generates many instances of the same data.
The KSM daemon ksmd periodically scans those areas of user memory which have been registered with it, looking for pages of identical content which can be replaced by a single write-protected page (which is automatically copied if a process later wants to update its content). The amount of pages that KSM daemon scans in a single pass and the time between the passes are configured using sysfs interface
KSM only merges anonymous (private) pages, never pagecache (file) pages. KSM’s merged pages were originally locked into kernel memory, but can now be swapped out just like other user pages (but sharing is broken when they are swapped back in: ksmd must rediscover their identity and merge again).
Refer
- https://github.com/torvalds/linux
- The Linux Kernel documentation
- x86-specific Documentation
- https://richardweiyang-2.gitbook.io/kernel-exploring