HTTP Libcurl in Action
- libcurl (the multiprotocol file transfer library)
- Other HTTP/FTP client Libraries for C/C++
- The libcurl API
- Easy or Multi
- The Easy interface
- multi interface overview
- Usage
- Q&A
- Refer
libcurl (the multiprotocol file transfer library)
libcurl is probably the most portable, most powerful and most often used network transfer library on this planet.
libcurl is a free and easy-to-use client-side URL transfer library, supporting DICT, FILE, FTP, FTPS, GOPHER, GOPHERS, HTTP, HTTPS, IMAP, IMAPS, LDAP, LDAPS, MQTT, POP3, POP3S, RTMP, RTMPS, RTSP, SCP, SFTP, SMB, SMBS, SMTP, SMTPS, TELNET and TFTP. libcurl supports SSL certificates, HTTP POST, HTTP PUT, FTP uploading, HTTP form based upload, proxies, HTTP/2, HTTP/3, cookies, user+password authentication (Basic, Digest, NTLM, Negotiate, Kerberos), file transfer resume, http proxy tunneling and more!
libcurl is highly portable, it builds and works identically on numerous platforms, including Solaris, NetBSD, FreeBSD, OpenBSD, Darwin, HPUX, IRIX, AIX, Tru64, Linux, UnixWare, HURD, Windows, Amiga, OS/2, BeOs, Mac OS X, Ultrix, QNX, OpenVMS, RISC OS, Novell NetWare, DOS and more…
libcurl is free, thread-safe, IPv6 compatible, feature rich, well supported, fast, thoroughly documented and is already used by many known, big and successful companies.
Download
Go to the regular curl download page and get the latest curl package, or one of the specific libcurl packages listed.
API
You use libcurl with the provided C API. The curl team works hard to keep the API and ABI stable. If you prefer using libcurl from your other favorite language, chances are there’s already a binding written for it.
Howto
Check out our using libcurl page for general hints and advice, the free HTTP client library comparison. or read the comparisons against libwww and WinInet.
Other HTTP/FTP client Libraries for C/C++
Free and Open Source Software projects have a long tradition of forks and duplicate efforts. We enjoy “doing it ourselves”, no matter if someone else has done something very similar already.
Beast (Boost)
Beast is a C++ header-only library serving as a foundation for writing interoperable networking libraries by providing low-level HTTP/1, WebSocket, and networking protocol vocabulary types and algorithms using the consistent asynchronous model of Boost.Asio.
wget (GPL)
While not a library at all, I’ve been told that people sometimes extract the network code from it and base their own hacks from there.
The libcurl API
Read the libcurl API overview and the libcurl tutorial to get a general in-depth grip of what libcurl programming is all about.
There are some example C source codes you can check out.
Dig into the Symbols In Versions document to learn in which libcurl releases symbols were added or removed.
Easy or Multi
The easy interface is a synchronous, efficient, quickly used and… yes, easy interface for file transfers. Numerous applications have been built using this.
The multi interface is the asynchronous brother in the family and it also offers multiple transfers using a single thread and more. Get a grip of how to work with it in the multi interface overview.
The Easy interface
When using libcurl you init your easy-session and get a handle, which you use as input to the following interface functions you use.
You continue by setting all the options you want in the upcoming transfer, most important among them is the URL itself. You might want to set some callbacks as well that will be called from the library when data is available etc.
When all is setup, you tell libcurl to perform the transfer. It will then do the entire operation and won’t return until it is done or failed.
After the performance is made, you may get information about the transfer and then you cleanup the easy-session’s handle and libcurl is entirely off the hook!
See also the easy interface overview.
curl_easy_init()
curl_easy_cleanup()
curl_easy_setopt()
curl_easy_perform()
curl_easy_getinfo()
While the above functions are the main functions to use in the easy interface, there is a series of other helpful functions too including:
curl_version() // returns a pointer to the libcurl version string
curl_getdate() // converts a date string to time_t
curl_mime_init() // ... and family, to build multipart form-data posts
curl_formadd() // (old-style) build multipart form-data posts
curl_slist_append() // builds a linked list
curl_slist_free_all() // frees a whole curl_slist as made with curl_slist_append()
curl_easy_escape() // URL encodes a string
curl_easy_unescape() // URL decodes a string
multi interface overview
libcurl-multi - how to use the multi interface
This is an overview on how to use the libcurl multi interface in your C programs. There are specific man pages for each function mentioned in here. There’s also the libcurl-tutorial man page for a complete tutorial to programming with libcurl and the libcurl-easy man page for an overview of the libcurl easy interface.
All functions in the multi interface are prefixed with curl_multi.
Objectives
The multi interface offers several abilities that the easy interface does not. They are mainly:
-
Enable a “pull” interface. The application that uses libcurl decides where and when to ask libcurl to get/send data.
-
Enable multiple simultaneous transfers in the same thread without making it complicated for the application.
-
Enable the application to wait for action on its own file descriptors and curl’s file descriptors simultaneously.
-
Enable event-based handling and scaling transfers up to and beyond thousands of parallel connections.
One multi handle many easy handles
To use the multi interface, you must first create a ‘multi handle’ with curl_multi_init. This handle is then used as input to all further curl_multi_* functions.
With a multi handle and the multi interface you can do several simultaneous transfers in parallel. Each single transfer is built up around an easy handle. You create all the easy handles you need, and setup the appropriate options for each easy handle using curl_easy_setopt.
There are two flavours of the multi interface, the select() oriented one and the event based one we call multi_socket. You will benefit from reading through the description of both versions to fully understand how they work and differentiate. We start out with the select() oriented version.
When an easy handle is setup and ready for transfer, then instead of using curl_easy_perform like when using the easy interface for transfers, you should add the easy handle to the multi handle with curl_multi_add_handle. You can add more easy handles to a multi handle at any point, even if other transfers are already running.
Should you change your mind, the easy handle is again removed from the multi stack using curl_multi_remove_handle. Once removed from the multi handle, you can again use other easy interface functions like curl_easy_perform on the handle or whatever you think is necessary. You can remove handles at any point during transfers.
Adding the easy handle to the multi handle does not start the transfer. Remember that one of the main ideas with this interface is to let your application drive. You drive the transfers by invoking curl_multi_perform. libcurl will then transfer data if there is anything available to transfer. it will use the callbacks and everything else you have setup in the individual easy handles. it will transfer data on all current transfers in the multi stack that are ready to transfer anything. It may be all, it may be none. When there’s nothing more to do for now, it returns back to the calling application.
Your application extracts info from libcurl about when it would like to get invoked to transfer data or do other work. The most convenient way is to use curl_multi_poll that will help you wait until the application should call libcurl again. The older API to accomplish the same thing is curl_multi_fdset that extracts fd_sets from libcurl to use in select() or poll() calls in order to get to know when the transfers in the multi stack might need attention. Both these APIs allow for your program to wait for input on your own private file descriptors at the same time. curl_multi_timeout also helps you with providing a suitable timeout period for your select() calls.
curl_multi_perform stores the number of still running transfers in one of its input arguments, and by reading that you can figure out when all the transfers in the multi handles are done. ‘done’ does not mean successful. One or more of the transfers may have failed.
To get information about completed transfers, to figure out success or not and similar, curl_multi_info_read should be called. It can return a message about a current or previous transfer. Repeated invokes of the function get more messages until the message queue is empty. The information you receive there includes an easy handle pointer which you may use to identify which easy handle the information regards.
When a single transfer is completed, the easy handle is still left added to the multi stack. You need to first remove the easy handle with curl_multi_remove_handle and then close it with curl_easy_cleanup, or possibly set new options to it and add it again with curl_multi_add_handle to start another transfer.
When all transfers in the multi stack are done, close the multi handle with curl_multi_cleanup. Be careful and please note that you MUST invoke separate curl_easy_cleanup calls for every single easy handle to clean them up properly.
If you want to re-use an easy handle that was added to the multi handle for transfer, you must first remove it from the multi stack and then re-add it again (possibly after having altered some options at your own choice).
Multi_socket
curl_multi_socket_action function offers a way for applications to not only avoid being forced to use select(), but it also offers a much more high-performance API that will make a significant difference for applications using large numbers of simultaneous connections.
curl_multi_socket_action is then used instead of curl_multi_perform.
When using this API, you add easy handles to the multi handle just as with the normal multi interface. Then you also set two callbacks with the CURLMOPT_SOCKETFUNCTION and CURLMOPT_TIMERFUNCTION options to curl_multi_setopt. They are two callback functions that libcurl will call with information about what sockets to wait for, and for what activity, and what the current timeout time is - if that expires libcurl should be notified.
The multi_socket API is designed to inform your application about which sockets libcurl is currently using and for what activities (read and/or write) on those sockets your application is expected to wait for.
Your application must make sure to receive all sockets informed about in the CURLMOPT_SOCKETFUNCTION callback and make sure it reacts on the given activity on them. When a socket has the given activity, you call curl_multi_socket_action specifying which socket and action there are.
The CURLMOPT_TIMERFUNCTION callback is called to set a timeout. When that timeout expires, your application should call the curl_multi_socket_action function saying it was due to a timeout.
This API is typically used with an event-driven underlying functionality (like libevent, libev, kqueue, epoll or similar) with which the application “subscribes” on socket changes. This allows applications and libcurl to much better scale upward and beyond thousands of simultaneous transfers without losing performance.
When you have added your initial set of handles, you call curl_multi_socket_action with CURL_SOCKET_TIMEOUT set in the sockfd argument, and you will get callbacks call that sets you up and you then continue to call curl_multi_socket_action accordingly when you get activity on the sockets you have been asked to wait on, or if the timeout timer expires.
You can poll curl_multi_info_read to see if any transfer has completed, as it then has a message saying so.
Blocking
A few areas in the code are still using blocking code, even when used from the multi interface. While we certainly want and intend for these to get fixed in the future, you should be aware of the following current restrictions:
- Name resolves unless the c-ares or threaded-resolver backends are used
- file:// transfers
- TELNET transfers
Usage
Compile
./configure --prefix=/data/home/gerryyang/tools/curl/curl-7.82.0-install --with-ssl
make && make install
$./curl -V
curl 7.82.0 (x86_64-pc-linux-gnu) libcurl/7.82.0 OpenSSL/1.0.2k-fips zlib/1.2.7
Release-Date: 2022-03-05
Protocols: dict file ftp ftps gopher gophers http https imap imaps mqtt pop3 pop3s rtsp smb smbs smtp smtps telnet tftp
Features: alt-svc AsynchDNS HSTS HTTPS-proxy IPv6 Largefile libz NTLM NTLM_WB SSL UnixSockets
./curl-config --cflags
-I/data/home/gerryyang/tools/curl/curl-7.82.0-install/include
./curl-config --libs
-L/data/home/gerryyang/tools/curl/curl-7.82.0-install/lib -lcurl
./curl-config --feature
AsynchDNS
HSTS
HTTPS-proxy
IPv6
Largefile
NTLM
NTLM_WB
SSL
UnixSockets
alt-svc
libz
Global preparation
The program must initialize some of the libcurl functionality globally. That means it should be done exactly once, no matter how many times you intend to use the library. Once for your program’s entire life time. This is done using
curl_global_init()
and it takes one parameter which is a bit pattern that tells libcurl what to initialize. Using CURL_GLOBAL_ALL will make it initialize all known internal sub modules, and might be a good default option. The current two bits that are specified are:
CURL_GLOBAL_WIN32
which only does anything on Windows machines. When used on a Windows machine, it will make libcurl initialize the win32 socket stuff. Without having that initialized properly, your program cannot use sockets properly. You should only do this once for each application, so if your program already does this or of another library in use does it, you should not tell libcurl to do this as well.
CURL_GLOBAL_SSL
which only does anything on libcurls compiled and built SSL-enabled. On these systems, this will make libcurl initialize the SSL library properly for this application. This only needs to be done once for each application so if your program or another library already does this, this bit should not be needed.
libcurl has a default protection mechanism that detects if curl_global_init has not been called by the time curl_easy_perform is called and if that is the case, libcurl runs the function itself with a guessed bit pattern. Please note that depending solely on this is not considered nice nor good.
When the program no longer uses libcurl, it should call curl_global_cleanup, which is the opposite of the init call. It will then do the reversed operations to cleanup the resources the curl_global_init call initialized.
Repeated calls to curl_global_init and curl_global_cleanup should be avoided. They should only be called once each.
Two interfaces
libcurl first introduced the so called easy interface. All operations in the easy interface are prefixed with ‘curl_easy’. The easy interface lets you do single transfers with a synchronous and blocking function call.
libcurl also offers another interface that allows multiple simultaneous transfers in a single thread, the so called multi interface. More about that interface is detailed in a separate chapter further down. You still need to understand the easy interface first, so please continue reading for better understanding.
Multi-threading issues
libcurl is thread safe but there are a few exceptions. Refer to libcurl-thread for more information.
When it does not work (问题定位)
There will always be times when the transfer fails for some reason. You might have set the wrong libcurl option or misunderstood what the libcurl option actually does, or the remote server might return non-standard replies that confuse the library which then confuses your program.
There’s one golden rule when these things occur: set the CURLOPT_VERBOSE option to 1. it will cause the library to spew out the entire protocol details it sends, some internal info and some received protocol data as well (especially when using FTP). If you are using HTTP, adding the headers in the received output to study is also a clever way to get a better understanding why the server behaves the way it does. Include headers in the normal body output with CURLOPT_HEADER set 1.
If CURLOPT_VERBOSE is not enough, you increase the level of debug data your application receive by using the CURLOPT_DEBUGFUNCTION.
Getting some in-depth knowledge about the protocols involved is never wrong, and if you are trying to do funny things, you might understand libcurl and how to use it better if you study the appropriate RFC documents at least briefly.
Libcurl with c++
There’s basically only one thing to keep in mind when using C++ instead of C when interfacing libcurl:
The callbacks CANNOT be non-static class member functions
Example C++ code:
class AClass {
static size_t write_data(void *ptr, size_t size, size_t nmemb,
void *ourpointer)
{
/* do what you want with the data */
}
}
Q&A
curl_multi_perform creates new thread
I compiled curl from the github repository with --with-openssl then I compiled multi-app.c. When I run the program in gdb and add a breakpoint for pthread_create I see:
> gdb) bt
> #0 __pthread_create_2_1 (newthread=0x555555590d50, attr=0x0,
> start_routine=0x7ffff7f61d20, arg=0x555555590fe0) at pthread_create.c:625
> #1 0x00007ffff7f61da6 in ?? () from /lib/x86_64-linux-gnu/libcurl.so.4
> #2 0x00007ffff7f65224 in ?? () from /lib/x86_64-linux-gnu/libcurl.so.4
> #3 0x00007ffff7f29875 in ?? () from /lib/x86_64-linux-gnu/libcurl.so.4
> #4 0x00007ffff7f3f2ce in ?? () from /lib/x86_64-linux-gnu/libcurl.so.4
> #5 0x00007ffff7f5125f in ?? () from /lib/x86_64-linux-gnu/libcurl.so.4
> #6 0x00007ffff7f520c1 in curl_multi_perform () from
> /lib/x86_64-linux-gnu/libcurl.so.4
> #7 0x00005555555554ec in main () at main.c:45
>
Is this expected?
Thanks
Answers:
curl will use the threaded resolver option by default, so yes, this is expected. You can configure with the --disable-threaded-resolver or
--enable-ares option to avoid this.
Chunked encoded POSTs
When talking to an HTTP 1.1 server, you can tell curl to send the request body without a Content-Length: header upfront that specifies exactly how big the POST is. By insisting on curl using chunked Transfer-Encoding, curl will send the POST chunked piece by piece in a special style that also sends the size for each such chunk as it goes along.
You send a chunked POST with curl like this:
curl -H "Transfer-Encoding: chunked" -d @file http://example.com
How does HTTP Deliver a Large File?
In the early era of the network, people send files in single-digit KB size. In 2021, we enjoy hi-res MB-size images and watch 4K (soon 8K) video in several GB. Even with a good internet connection, it still takes a while to download a 5GB file.
We have three ways to shorten the time sending extensive data by HTTP:
compress data
When sending a request, a browser includes a header Accept-Encoding with a list of supported compression algorithms, including gzip (GZIP), compress, deflate, and br (Brotli).
Next, the server picks the one it supports from the list and sets the algorithm name in the Content-Encoding header.
When the browser receives the response, it knows how to digest the data in the body.
send chunked data
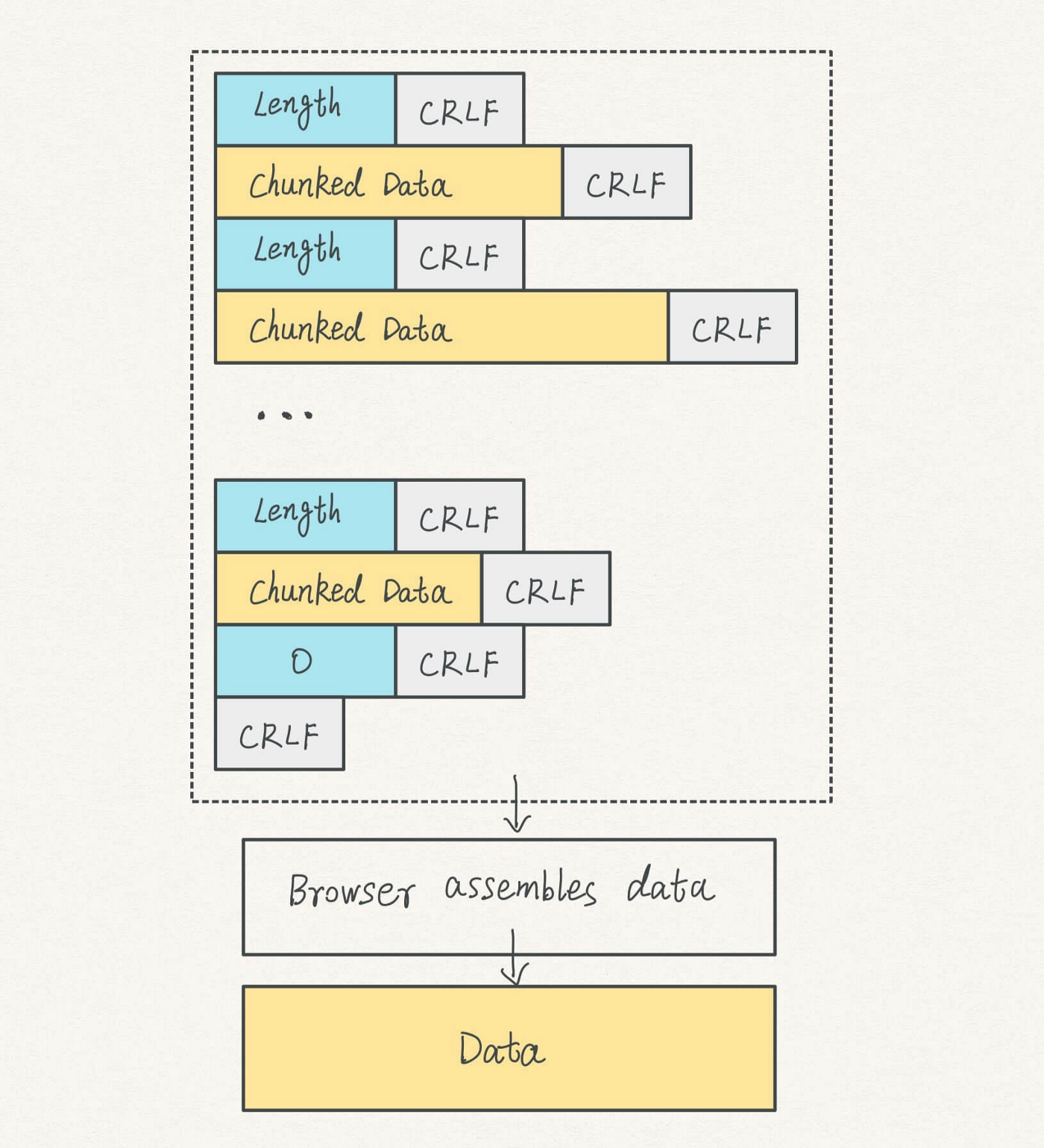
In version 1.1, HTTP introduced chunked data to help with the large-data cases.
When sending a response, the server adds a header Transfer-Encoding: chunked, letting the browser know that data is transmitted in chunks.
Each piece of chunked data has the following components:
- a Length block marks, well, the length of the current part of chunked data
- the chunked data block
- a CRLF separator at the end of each block
Wondering what a CRLF is?
A CR immediately followed by an LF (CRLF, \r\n, or 0x0D0A) moves the cursor down to the next line and then to the beginning of the line.
The server continues streaming chunked data to the browser.
When reaching the end of the data stream, it attaches an end mark consisting of the following parts:
- a Length block with the number 0 and a CRLF at the end
- an additional CRLF
On the browser side, it waits for all data chunks until it reaches the end mark. It then removes the chunked encoding, including the CRLF and the length information.
Next, it combines the chunked data into a whole. Therefore, you can only see the assembled data on Chrome DevTools instead of chunked ones.
Finally, you receive the entire data in one piece.
Chunked data is useful. However, for a 5GB video, it still takes a while for the complete data to arrive.
request data in a selected range
Can we get a selected chunk of the date and request the others when we need?
HTTP says yes.
Opening a video on YouTube, you see a grey progress bar is moving forward.
What you just saw is YouTube requesting data in a selected range.
This feature enables you to jump anywhere in the timeline. When clicking on the spot on the progress bar, the browser requests a specific range of the video data.
It is optional to implement the range requests on a server. If it does, you can see the Accept-Ranges: bytes in the response header.
Refer
- https://curl.se/libcurl/
- libcurl programming tutorial
- libcurl - small example snippets
- https://github.com/nodejs/http-parser
- https://github.com/nodejs/llhttp
- Understand HTTP3 in 5 minutes