TCP/IP in Action
- TCP 状态变化
- TCP 核心思想:带重传的累积正向应答
- 正确使用 TCP/IP 首要原则:别添乱
- IPv4 Header
- TCP Header
- Network address
- DataStruct
- Options (socket)
- Interface
- Nagle 算法
- Tools
- Q&A
- Refer
TCP 状态变化
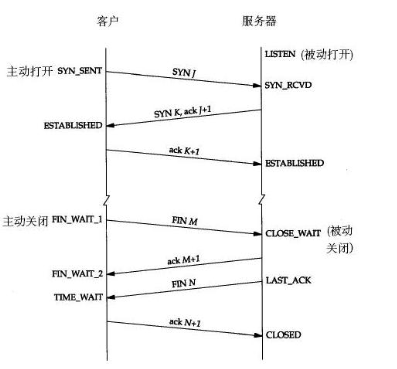
TCP关闭连接如上图下半部分的四次握手实现。发起终止的一方称主动关闭(client),响应的一方为被动关闭(server)。
- 当 client 要关闭时,发出一个 TCP 的 FIN 包, 此时 socket 状态改为
FIN_WAIT_1。 - 接收方收到 FIN 包,返回一个带确认序号的 ACK,同时向自己对应的进程发送一个文件结束符 EOF,此时 server 端 socket 状态变为
CLOSE_WAIT,发起方接到 ACK 后状态更改为FIN_WAIT_2; - server 端应用层侦测到 socket 需关闭,即调用 close,向对端发出一个 TCP 的 FIN 包,同时其 socket 状态更改为
LAST_ACK; - 发起方接到 FIN 包后即发 ACK 确认包,同时 socket 状态更改为
TIME_WAIT。此时 server 端 socket 正常变为CLOSED, 但客户端需等待 2MSL(Maximum Segment Lifetime 报文最大生存时间)后状态方变为CLOSED。
TIME_WAIT状态的目的是为了防止最后发出 ACK 丢失,接收方处于LAST_ACK超时重发 FIN。所以,主动发起关闭连接的一方会进入TIME_WAIT状态,在进行压力测试的时候,这种状态大量存在,进程所占用的端口号不能被释放,导致后来的连接建立失败。
在内核协议层通过设置以下两个参数来解决 TIME_WAIT 问题:
TIME_WAIT状态可以重用,这样即使TIME_WAIT占满了所有端口,也不会拒绝新的请求
echo 1 > /proc/sys/net/ipv4/tcp_tw_reuse
TIME_WAIT尽快回收
echo 1 > /proc/sys/net/ipv4/tcp_tw_recycle
tcp_tw_recycle 打开后能在很短的时间能将
TIME_WAIT的端口回收(但是具体时间并未找到相应的资料,测试观察在1秒左右)。同时,打开加速回收或者允许重用,存在一定的问题,例如,发起方(client) 在发出最后一个 ACK 后立即被回收,而 ACK 丢失,接受方超时重发 FIN,恰好此时发起方使用刚才的端口建立起新的连接,那它将收到一个 FIN,从而可能引发异常被动关闭。
与 TIME_WAIT 相对应的是 CLOSE_WAIT 问题,被动关闭的情况下,已经接收到 FIN,但是还没有发送自己的 FIN 的时刻,连接处于 CLOSE_WAIT 状态。正常情况下 CLOSE_WAIT 状态时间很短。如果出现大量的 CLOSE_WAIT,是某种情况下对方关闭了连接,但是接收方忙于读或者写,没有关闭连接导致。在代码实现的时候需要判断 socket,一旦 read 返回 0,断开连接,read 返回负,检查一下 errno,如果不是 AGAIN,也断开连接。
TCP 核心思想:带重传的累积正向应答
- Cumulative positive acknowledgement with retransmission
- Flow control (sliding window)
- Congestion control
2 & 3 are optional ! Really ?!
TCP/IP 协议中的拥塞控制和流量控制都是为了保证网络传输的可靠性和效率,但它们的目的和实现方式有所不同。
拥塞控制是为了防止网络拥塞,即当网络中的数据流量过大时,导致网络性能下降或数据丢失。拥塞控制的目的是通过限制发送方的数据发送速率,以避免网络拥塞。TCP 协议中的拥塞控制算法包括慢启动、拥塞避免、快速重传和快速恢复等。
流量控制是为了防止接收方无法处理发送方发送的数据,即当接收方处理速度较慢时,导致数据丢失或缓存溢出。流量控制的目的是通过限制发送方的数据发送速率,以避免接收方无法处理数据。TCP 协议中的流量控制使用了滑动窗口机制,接收方通过发送窗口大小告诉发送方可以接收的数据量,发送方根据接收方的窗口大小来控制发送速率。
因此,拥塞控制和流量控制都是为了保证网络传输的可靠性和效率,但拥塞控制是为了避免网络拥塞,而流量控制是为了避免接收方无法处理数据。
正确使用 TCP/IP 首要原则:别添乱
- 不要轻易相信网上来路不明,相互抄袭,似是而非,以讹传讹的过时“调优”经验
例如,Buffer auto-tuning: don’t set SNDBUF/RCVBUF unless you want to reduce them
- 从一次经历谈 TIME_WAIT 的那些事 - 陈皓
- Coping with the TCP TIME-WAIT state on busy Linux servers
- TCP 的那些事儿(上)- 陈皓
- TCP 的那些事儿(下)- 陈皓
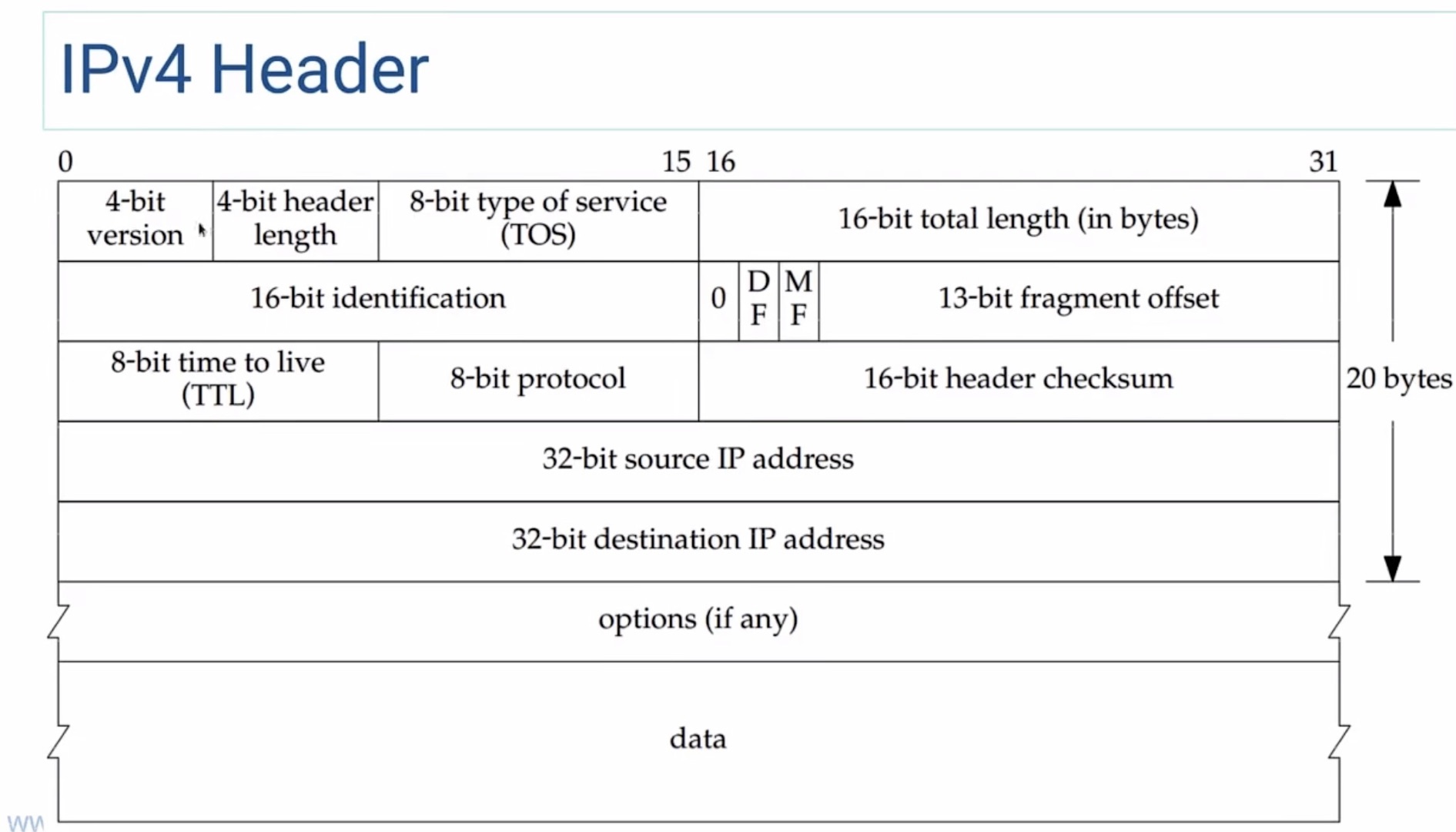
IPv4 Header
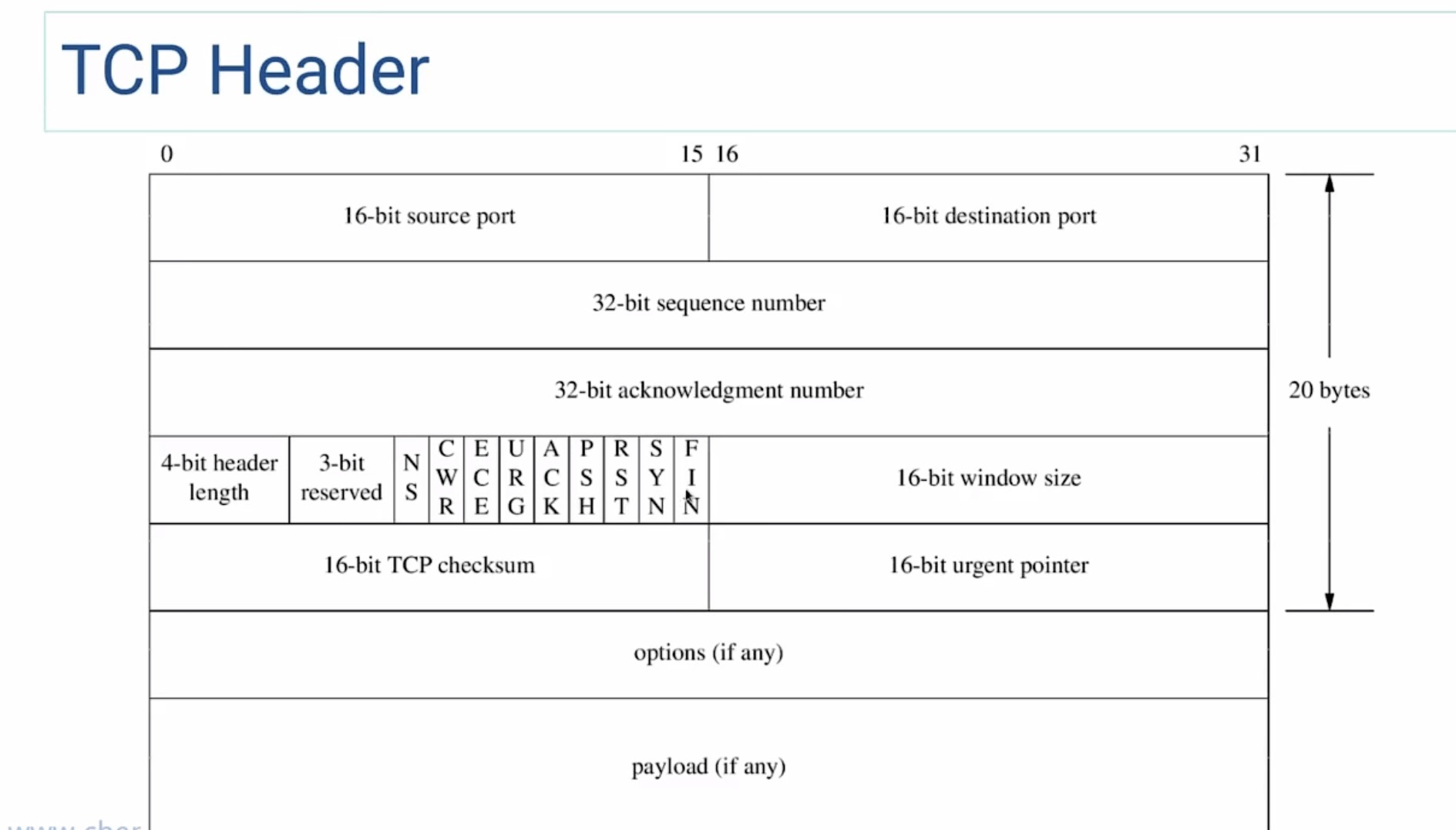
TCP Header
Network address
A network address is an identifier for a node or host on a telecommunications network. Network addresses are designed to be unique identifiers across the network, although some networks allow for local, private addresses, or locally administered addresses that may not be unique. Special network addresses are allocated as broadcast or multicast addresses. These too are not unique.
In some cases, network hosts may have more than one network address. For example, each network interface controller may be uniquely identified. Further, because protocols are frequently layered, more than one protocol’s network address can occur in any particular network interface or node and more than one type of network address may be used in any one network.
Network addresses can be flat addresses which contain no information about the node’s location in the network (such as a MAC address), or may contain structure or hierarchical information for the routing (such as an IP address).
- https://en.wikipedia.org/wiki/Network_address
DataStruct
sockaddr_in
struct sockaddr_in {
sa_family_t sin_family; /* address family: AF_INET */
in_port_t sin_port; /* port in network byte order */
struct in_addr sin_addr; /* internet address */
};
/* Internet address */
struct in_addr {
uint32_t s_addr; /* address in network byte order */
};
- https://man7.org/linux/man-pages/man7/ip.7.html
hostent
The hostent structure is defined in <netdb.h> as follows:
struct hostent {
char *h_name; /* official name of host */
char **h_aliases; /* alias list */
int h_addrtype; /* host address type */
int h_length; /* length of address */
char **h_addr_list; /* list of addresses */
}
#define h_addr h_addr_list[0] /* for backward compatibility */
The members of the hostent structure are:
h_nameThe official name of the host.h_aliasesAn array of alternative names for the host, terminated by a null pointer.h_addrtypeThe type of address; alwaysAF_INETorAF_INET6at present.h_lengthThe length of the address in bytes.h_addr_listAn array of pointers to network addresses for the host (in network byte order), terminated by a null pointer.-
h_addrThe first address in h_addr_list for backward compatibility. - https://man7.org/linux/man-pages/man3/gethostbyname.3.html
addrinfo
The addrinfo structure used by getaddrinfo() contains the following fields:
struct addrinfo {
int ai_flags;
int ai_family;
int ai_socktype;
int ai_protocol;
socklen_t ai_addrlen;
struct sockaddr *ai_addr;
char *ai_canonname;
struct addrinfo *ai_next;
};
- https://man7.org/linux/man-pages/man3/getaddrinfo.3.html
Options (socket)
SO_SNDBUF
Sets or gets the maximum socket send buffer in bytes. The kernel doubles this value (to allow space for bookkeeping overhead) when it is set using setsockopt(2), and this doubled value is returned by getsockopt(2). The default value is set by the /proc/sys/net/core/wmem_default file and the maximum allowed value is set by the /proc/sys/net/core/wmem_max file. The minimum (doubled) value for this option is 2048.
SO_RCVBUF
Sets or gets the maximum socket receive buffer in bytes. The kernel doubles this value (to allow space for bookkeeping overhead) when it is set using setsockopt(2), and this doubled value is returned by getsockopt(2). The default value is set by the /proc/sys/net/core/rmem_default file, and the maximum allowed value is set by the /proc/sys/net/core/rmem_max file. The minimum (doubled) value for this option is 256.
NOTES: Linux assumes that half of the send/receive buffer is used for internal kernel structures; thus the sysctls are twice what can be observed on the wire.
- https://man7.org/linux/man-pages/man7/socket.7.html
- Understanding set/getsockopt SO_SNDBUF size doubles
Interface
connect
connect - initiate a connection on a socket
non-blocking connect
解释1:
You should use the following steps for an non-blocking connect:
- create socket with
socket(..., SOCK_NONBLOCK, ...) - start connection with
connect(fd, ...) - if return value is neither
0norEINPROGRESS, then abort with error - wait until
fdis signalled as ready for output - check status of socket with
getsockopt(fd, SOL_SOCKET, SO_ERROR, ...) - done
No loops - unless you want to handle EINTR.
If the client is started first, you should see the error ECONNREFUSED in the last step. If this happens, close the socket and start from the beginning.
解释2:
Situation: You set up a non-blocking socket and do a connect() that returns -1/EINPROGRESS or -1/EWOULDBLOCK. You select() the socket for writability. This returns as soon as the connection succeeds or fails. (Exception: Under some old versions of Ultrix, select() wouldn’t notice failure before the 75-second timeout.)
Question: What do you do after select() returns writability? Did the connection fail? If so, how did it fail?
If the connection failed, the reason is hidden away inside something called so_error in the socket. Modern systems let you see so_error with getsockopt(,,SO_ERROR,,), but this isn’t portable—in fact, getsockopt() can crash old systems. A different way to see so_error is through error slippage: any attempt to read or write data on the socket will return -1/so_error.
Sometimes you have data to immediately write to the connection. Then you can just write() the data. If connect() failed, the failure will be reported by write(), usually with the right connect() errno. This is the solution I supplied for IRC in 1990. Unfortunately, on some systems, under some circumstances, write() will substitute EPIPE for the old errno, so you lose information.
Another possibility is read(fd,&ch,0). If connect() succeeded, you get a 0 return value, except under Solaris, where you get -1/EAGAIN. If connect() failed, you should get the right errno through error slippage. Fatal flaw: under Linux, you will always get 0.
…
- https://man7.org/linux/man-pages/man2/connect.2.html
- Linux, sockets, non-blocking connect
- Non-blocking BSD socket connections
- https://blog.csdn.net/nphyez/article/details/10268723
send
send, sendto, sendmsg - send a message on a socket
DESCRIPTION
The system calls send(), sendto(), and sendmsg() are used to transmit a message to another socket.
The send() call may be used only when the socket is in a connected state (so that the intended recipient is known). The only difference between send() and write(2) is the presence of flags. With a zero flags argument, send() is equivalent to write(2).
- https://man7.org/linux/man-pages/man2/send.2.html
- Asynchronous socket send on Linux
recv
recv, recvfrom, recvmsg - receive a message from a socket
DESCRIPTION
The recv(), recvfrom(), and recvmsg() calls are used to receive messages from a socket. They may be used to receive data on both connectionless and connection-oriented sockets.
The only difference between recv() and read(2) is the presence of flags. With a zero flags argument, recv() is generally equivalent to read(2) (but see NOTES).
Also, the following call recv(sockfd, buf, len, flags); is equivalent to recvfrom(sockfd, buf, len, flags, NULL, NULL);
All three calls return the length of the message on successful completion. If a message is too long to fit in the supplied buffer, excess bytes may be discarded depending on the type of socket the message is received from.
If no messages are available at the socket, the receive calls wait for a message to arrive, unless the socket is nonblocking (see fcntl(2)), in which case the value -1 is returned and errno is set to EAGAIN or EWOULDBLOCK. The receive calls normally return any data available, up to the requested amount, rather than waiting for receipt of the full amount requested.
An application can use select(2), poll(2), or epoll(7) to determine when more data arrives on a socket.
- https://man7.org/linux/man-pages/man2/recv.2.html
- What is the maximum len to recv/recvfrom
select
select, pselect, FD_CLR, FD_ISSET, FD_SET, FD_ZERO - synchronous I/O multiplexing
int select(int nfds,
fd_set *restrict readfds,
fd_set *restrict writefds,
fd_set *restrict exceptfds,
struct timeval *restrict timeout);
DESCRIPTION
WARNING: select() can monitor only file descriptors numbers that are less than FD_SETSIZE (1024)—an unreasonably low limit for many modern applications—and this limitation will not change. All modern applications should instead use poll(2) or epoll(7), which do not suffer this limitation.
select() allows a program to monitor multiple file descriptors, waiting until one or more of the file descriptors become “ready” for some class of I/O operation (e.g., input possible). A file descriptor is considered ready if it is possible to perform a corresponding I/O operation (e.g., read(2), or a sufficiently small write(2)) without blocking.
nfds
This argument should be set to the highest-numbered file descriptor in any of the three sets, plus 1. The indicated file descriptors in each set are checked, up to this limit (but see BUGS).
BUGS
POSIX allows an implementation to define an upper limit, advertised via the constant FD_SETSIZE, on the range of file descriptors that can be specified in a file descriptor set. The Linux kernel imposes no fixed limit, but the glibc implementation makes fd_set a fixed-size type, with FD_SETSIZE defined as 1024, and the FD_*() macros operating according to that limit. To monitor file descriptors greater than 1023, use poll(2) or epoll(7) instead.
- https://man7.org/linux/man-pages/man2/select.2.html
poll
#include <poll.h>
int poll(struct pollfd *fds, nfds_t nfds, int timeout);
poll() performs a similar task to select(2): it waits for one of a set of file descriptors to become ready to perform I/O. The Linux-specific epoll(7) API performs a similar task, but offers features beyond those found in poll().
The set of file descriptors to be monitored is specified in the fds argument, which is an array of structures of the following form:
struct pollfd {
int fd; /* file descriptor */
short events; /* requested events */
short revents; /* returned events */
};
The caller should specify the number of items in the fds array in nfds.
- https://man7.org/linux/man-pages/man2/poll.2.html
getsockopt
getsockopt, setsockopt - get and set options on sockets
DESCRIPTION
getsockopt() and setsockopt() manipulate options for the socket referred to by the file descriptor sockfd. Options may exist at multiple protocol levels; they are always present at the uppermost socket level.
- https://man7.org/linux/man-pages/man2/getsockopt.2.html
getaddrinfo
int getaddrinfo(const char *restrict node,
const char *restrict service,
const struct addrinfo *restrict hints,
struct addrinfo **restrict res);
Given node and service, which identify an Internet host and a service, getaddrinfo() returns one or more addrinfo structures, each of which contains an Internet address that can be specified in a call to bind(2) or connect(2). The getaddrinfo() function combines the functionality provided by the gethostbyname(3) and getservbyname(3) functions into a single interface, but unlike the latter functions, getaddrinfo() is reentrant and allows programs to eliminate IPv4-versus-IPv6 dependencies.
getaddrinfo() is used to translate a domain name, like stackoverflow.com, to an IP address like 69.59.196.211.
For more info, here’s how it works in detail: What does getaddrinfo do?
TL;DR it runs through /etc/nsswitch.conf, and uses whatever modules are listed in there to resolve the path. Usually this is hosts: files myhostname dns, when it finally hits the dns module it dynamically loads that library and then that does the DNS lookup by looking at /etc/hosts and /etc/resolv.conf.
测试代码:
https://wandbox.org/permlink/lLxsF1NqXamWodoF
#include <stdio.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <netdb.h>
#include <arpa/inet.h>
int main(void)
{
struct addrinfo* addr;
int result = getaddrinfo("google.com", NULL, NULL, &addr);
if (result != 0) {
printf("Error from getaddrinfo: %s\n", gai_strerror(result));
return 1;
}
struct sockaddr_in* internet_addr = (struct sockaddr_in*) addr->ai_addr;
printf("google.com is at: %s\n", inet_ntoa(internet_addr->sin_addr));
freeaddrinfo(addr);
return 0;
}
$./a.out
google.com is at: 172.217.163.46
- https://man7.org/linux/man-pages/man3/getaddrinfo.3.html
- How does getaddrinfo() do DNS lookup?
- What does getaddrinfo do?
gethostbyname
#include <stdio.h>
#include <netdb.h>
int main()
{
struct hostent *lh = gethostbyname("localhost");
if (lh) {
puts(lh->h_name);
printf("%u.%u.%u.%u\n", lh->h_addr_list[0][0],
lh->h_addr_list[0][1],
lh->h_addr_list[0][2],
lh->h_addr_list[0][3]);
} else {
herror("gethostbyname");
}
}
/*
localhost
127.0.0.1
*/
- https://man7.org/linux/man-pages/man3/gethostbyname.3.html
getpeername
#include <sys/socket.h>
int getpeername(int sockfd, struct sockaddr *restrict addr,
socklen_t *restrict addrlen);
getpeername() returns the address of the peer connected to the socket sockfd, in the buffer pointed to by addr. The addrlen argument should be initialized to indicate the amount of space pointed to by addr. On return it contains the actual size of the name returned (in bytes). The name is truncated if the buffer provided is too small.
The returned address is truncated if the buffer provided is too small; in this case, addrlen will return a value greater than was supplied to the call.
- https://man7.org/linux/man-pages/man2/getpeername.2.html
epoll
Don’t include EPOLLOUT unless you got EAGAIN from a write attempt, and remove it when you have successfully written bytes to a socket. This basically means that socket is always writable as long as there’s space in socket in-kernel send buffer.
You have two data streams - input and output.
You are waiting for the input by including EPOLLIN in the flags. If upon return from epoll_wait(2) that flag is not set, then either some event happened on some other socket, or this socket had some other event. Leave the flag in the events unless you get an error (meaning you are still interested in the input on the socket).
You don’t have to wait for the output (since it’s your action), you just write to the socket, but if you overflow socket send buffer, you’ll get EAGAIN from send(2) or write(2). In this case you start waiting for output to be possible (kernel draining socket send buffer thus making room for you to send more) by including EPOLLOUT. Once you get that, write your pending output bytes to the socket, and if you are successful, remove EPOLLOUT from the events.
Now EPOLLET indicates edge-triggered wait, meaning your desired event would only be signaled once per state change (like from “no input” to “there’s input”). In this mode you are supposed to read input bytes in a loop until you get EAGAIN.
- https://man7.org/linux/man-pages/man7/epoll.7.html
- https://stackoverflow.com/questions/13568858/epoll-wait-always-sets-epollout-bit
epoll_ctl
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
The event argument describes the object linked to the file descriptor fd. The struct epoll_event is defined as:
typedef union epoll_data {
void *ptr;
int fd;
uint32_t u32;
uint64_t u64;
} epoll_data_t;
struct epoll_event {
uint32_t events; /* Epoll events */
epoll_data_t data; /* User data variable */
};
The data member of the epoll_event structure specifies data that the kernel should save and then return (via epoll_wait(2)) when this file descriptor becomes ready.
The events member of the epoll_event structure is a bit mask composed by ORing together zero or more of the following available event types:
EPOLLIN: The associated file is available forread(2)operations.EPOLLOUT: The associated file is available forwrite(2)operations.EPOLLRDHUP (since Linux 2.6.17): Stream socket peer closed connection, or shut down writing half of connection. (This flag is especially useful for writing simple code to detect peer shutdown when using edge-triggered monitoring.)EPOLLPRI: There is an exceptional condition on the file descriptor. See the discussion of POLLPRI inpoll(2).EPOLLERR: Error condition happened on the associated file descriptor. This event is also reported for the write end of a pipe when the read end has been closed.epoll_wait(2)will always report for this event; it is not necessary to set it in events when callingepoll_ctl().EPOLLHUP: Hang up happened on the associated file descriptor.epoll_wait(2)will always wait for this event; it is not necessary to set it in events when callingepoll_ctl(). Note that when reading from a channel such as a pipe or a stream socket, this event merely indicates that the peer closed its end of the channel. Subsequent reads from the channel will return 0 (end of file) only after all outstanding data in the channel has been consumed.EPOLLET: Requests edge-triggered notification for the associated file descriptor. The default behavior for epoll is level-triggered. Seeepoll(7)for more detailed information about edge-triggered and level-triggered notification. This flag is an input flag for theevent.eventsfield when callingepoll_ctl(); it is never returned byepoll_wait(2).EPOLLONESHOT (since Linux 2.6.2): Requests one-shot notification for the associated file descriptor. This means that after an event notified for the file descriptor byepoll_wait(2), the file descriptor is disabled in the interest list and no other events will be reported by the epoll interface. The user must callepoll_ctl()withEPOLL_CTL_MODto rearm(重新装备) the file descriptor with a new event mask. This flag is an input flag for theevent.eventsfield when callingepoll_ctl(); it is never returned byepoll_wait(2).- EPOLLWAKEUP (since Linux 3.5)
- EPOLLEXCLUSIVE (since Linux 4.5)
refer:
- https://man7.org/linux/man-pages/man2/epoll_ctl.2.html
- https://cloud.tencent.com/developer/article/1481046
Nagle 算法
Nagle 算法主要用来预防小分组的产生。在广域网上,大量 TCP 小分组极有可能造成网络的拥塞。Nagle 是针对每一个 TCP 连接的。它要求一个 TCP 连接上最多只能有一个未被确认的小分组。在该分组的确认到达之前不能发送其他小分组。TCP 会搜集这些小的分组,然后在之前小分组的确认到达后将刚才搜集的小分组合并发送出去。
有时候必须要关闭 Nagle 算法,特别是在一些对时延要求较高的交互式操作环境中,所有的小分组必须尽快发送出去。可以通过编程取消 Nagle 算法,利用 TCP_NODELAY 选项来关闭 Nagle 算法。
Nagle 算法是时代的产物,因为当时网络带宽有限。而当前的局域网、广域网的带宽则宽裕得多,所以目前的 TCP/IP 协议栈默认将 Nagle 算法关闭。
- https://cloud.tencent.com/developer/article/1784570
Tools
EaseProbe
EaseProbe is a simple, standalone, and lightweight tool that can do health/status checking, written in Go.
Q&A
How to convert string to IP address and vice versa
Use inet_ntop() and inet_pton() if you need it other way around. Do not use inet_ntoa(), inet_aton() and similar as they are deprecated and don’t support ipv6.
// IPv4 demo of inet_ntop() and inet_pton()
struct sockaddr_in sa;
char str[INET_ADDRSTRLEN];
// store this IP address in sa:
inet_pton(AF_INET, "192.0.2.33", &(sa.sin_addr));
// now get it back and print it
inet_ntop(AF_INET, &(sa.sin_addr), str, INET_ADDRSTRLEN);
printf("%s\n", str); // prints "192.0.2.33"
When is TCP option SO_LINGER (0) required?
The typical reason to set a SO_LINGER timeout of zero is to avoid large numbers of connections sitting in the TIME_WAIT state, tying up all the available resources on a server.
When a TCP connection is closed cleanly, the end that initiated the close (“active close”) ends up with the connection sitting in TIME_WAIT for several minutes. So if your protocol is one where the server initiates the connection close, and involves very large numbers of short-lived connections, then it might be susceptible to this problem.
This isn’t a good idea, though - TIME_WAIT exists for a reason (to ensure that stray packets from old connections don’t interfere with new connections). It’s a better idea to redesign your protocol to one where the client initiates the connection close, if possible.